文章参考来源javaguide
并发题目进阶篇总结
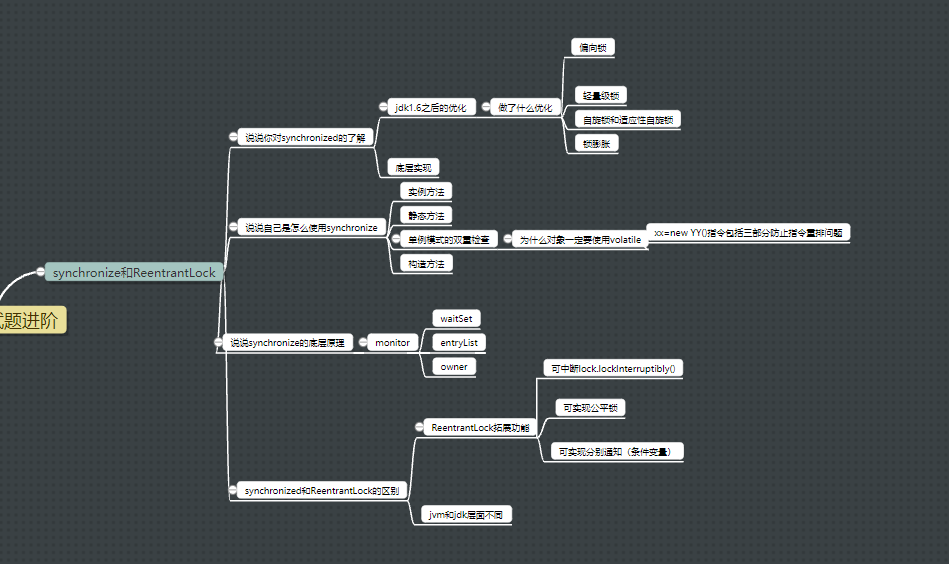
1.synchronized
1.1说说你对synchronized的了解?
- 重量级锁,底层使用的是监视器锁
- 上下文切换耗费大量时间和资源,原因是java线程需要转换到操作系统线程,用户态到内核态的转移
- jdk1.6之后进行大量优化,偏向锁,轻量级锁、自旋锁、锁膨胀
1.2说说自己是怎么使用synchronized?
- 修饰实例方法(对象实例作为锁)
- 修饰静态方法(类对象作为锁),分别调用静态方法和实例方法不会互斥
- 修饰代码块
说说双重验证的单例模式?
- 第一次判断可能会有多个线程通过,然后只能有一个线程进入创建,但是创建之前还是要判断一次。创建成功之后,还有其他判断成功的线程进入同步块创建但是第二次判断把他们都拒绝了防止了多次创建。
为什么双重验证要用volatile修饰对象?
因为xx=new yy()的时候分了三步
- 分配空间
- 初始化
- 赋值地址
如果不加上volatile就可能导致这些执行发生指令重拍,可能分配空间之后先执行赋值地址,然后切换线程获取到了不完整(没有经过初始化)的对象。
1.3构造方法需要使用synchronized吗?
不用是因为构造方法本身就是线程安全的。各自创建新的对象。不是共享资源。
1.3讲一下synchronized的底层原理
- 处于jvm层面的
- 通过monitorentry指令获取锁,并且保存一份引用
- 然后就是monitorexit释放锁
- 而且对象有一个ObjectMonitor,如果有关联monitor计数器就是1,否则就是0。这也是为什么没有synchronized的时候wait/notify不能使用,如果使用会报错IllegalMonitorStateException
- 如果是方法的话会使用ACC_SYNCHRONIZED来进行标识来调用monitor
//javac SynchronizedDemo.class编译
//javap -c -s -v -l SynchronizedDemo.class生成字节码文件
public class SynchronizedDemo {
public void method() {
synchronized (this) {
System.out.println("synchronized 代码块");
}
}
}
3: monitorenter
4: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
7: ldc #3 // String synchronized
9: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
12: aload_1
13: monitorexit
总结:本质就是对monitor的获取
1.4jdk1.6之后做了什么优化?
- 偏向锁、轻量级锁、自旋锁、锁膨胀、锁消除、锁粗化、适应性自旋锁
- 锁的状态,无锁,偏向锁,轻量级锁,重量级锁
1.5谈谈synchronized和ReentrantLock的区别?
-
都是可重入锁
-
synchronize通过jvm层面实现,ReentrantLock通过JDK层面进行实现
-
ReentrantLock多出来的功能包括
- 等待可中断,可以实现lock.lockInterruptibly()正在等待的线程可以选择放弃。假设两个线程在竞争同一把锁,其中一个获取到而且执行时间非常长,那么后面等待线程,可以通过外面的调用interrupt来中断等待。但是如果是lock那么就不行,还是要等待前面线程执行完,进去之后才发现自己被中断了。
- 可实现公平锁,
- 可实现选择性通知。通过条件变量
2.volatile关键字
2.2讲一下JMM
线程可以把变量读取到本地内存中执行(缓存),导致数据不一致的问题。如果两个线程同时运行读取变量并且一个进行i++,一个i–就会出现脏数据.另一种解释是JIT把常用的变量直接重新编译出来,而不是去内存中取。
2.3并发编程的3个重要特性
- 原子性
- 可见性
- 有序性
2.4说说synchronize和volatile的区别?
- volatile轻量级,性能更好但无法实现原子性
- volatile只能修饰变量,synchronized可以修饰方法和同步块
- volatile用于多个线程可见性,synchronized用于解决多线程访问资源同步性
3.ThreadLocal
谈谈ThreadLocal的原理
看了很多篇文章的讲解,对于ThreadLocal的理解是这样。这里创建了一个ThreadLoacal但是却可以实现多个线程独立有自己的ThreadLocal对应的值。原因就是源码里面的Thread里面的threadLocals,实际上ThreadLoacal的set方法创建了ThreadLocalMap,然后把自己当做key和传入的value存入线程内。那么就算是ThreadLocal被多个线程引用,但是最后获取value还是要靠你在对应线程的ThreadLocalMap存入的东西是什么,这样就是隔离的原理
ThreadLocal.ThreadLocalMap threadLocals = null;//Thread里面的map引用
//ThreadLocal初始化set的时候调用的方法
void createMap(Thread t, T firstValue) {
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
//然后再看看set方法,实际上就是取出线程t的threadLocals引用创建ThreadLocalMap对象,ThreadLocal作为key,存入value,就算多个线程的key相同但是他们的value是不同的
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
public class ThreadLocalExample implements Runnable{
// guide哥的这个例子里面ThreadLocal就是只有一个。
private static final ThreadLocal<SimpleDateFormat> formatter = ThreadLocal.withInitial(() -> new SimpleDateFormat("yyyyMMdd HHmm"));
public static void main(String[] args) throws InterruptedException {
ThreadLocalExample obj = new ThreadLocalExample();
for(int i=0 ; i<10; i++){
Thread t = new Thread(obj, ""+i);
Thread.sleep(new Random().nextInt(1000));
t.start();
}
}
@Override
public void run() {
System.out.println("Thread Name= "+Thread.currentThread().getName()+" default Formatter = "+formatter.get().toPattern());
try {
Thread.sleep(new Random().nextInt(1000));
} catch (InterruptedException e) {
e.printStackTrace();
}
//formatter pattern is changed here by thread, but it won't reflect to other threads
formatter.set(new SimpleDateFormat());
System.out.println("Thread Name= "+Thread.currentThread().getName()+" formatter = "+formatter.get().toPattern());
}
}
4.线程池
4.1为什么要使用线程池
- 降低资源消耗,重用线程
- 提高响应速度,任务以来就能执行,不需要创建线程
- 提高线程可管理性
4.2Runnable和Callable的区别
- Runnable不能返回异常,但是Callable可以
4.3execute和submit的区别
- execute不返回结果,但是submit可以返回结果
- 而且execute不能得知任务执行情况,submit可以通过返回future对象来获取任务执行信息和结果
public Future<?> submit(Runnable task) {
//创建FutureTask,并且执行
if (task == null) throw new NullPointerException();
RunnableFuture<Void> ftask = newTaskFor(task, null);
execute(ftask);
return ftask;
}
protected <T> RunnableFuture<T> newTaskFor(Runnable runnable, T value) {
return new FutureTask<T>(runnable, value);
}
4.4如何创建线程池
不推荐使用Executors的原因?
- FixedThreadPool和SingleThreadExecutor的队列是无限大的,可以创建无数任务导致oom内存溢
- CacheThreadPool和ScheduleThreadPool无限创建线程导致内存溢出,申请太多线程的栈
方式1
通过构造方法实现ThreadPoolExecutor
方式2
通过Executors来构造,实际上还是通过ThreadPoolExecutor来进行构造
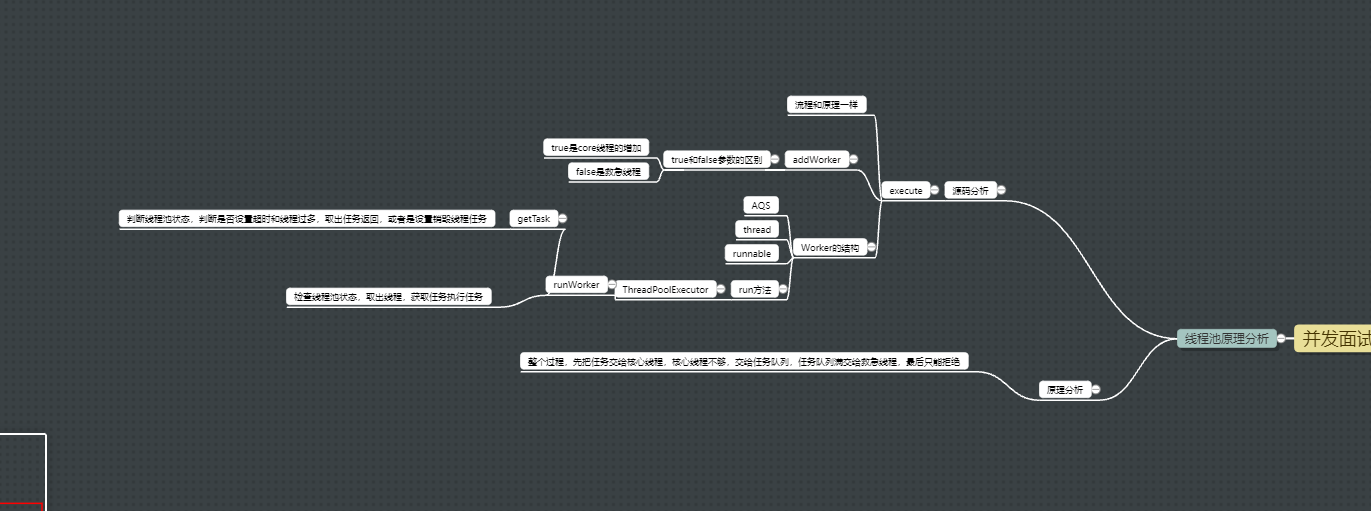
4.7线程池原理分析
参考文章链接:https://blog.csdn.net/u013332124/article/details/79587436
实际上就是把任务交给workSet的worker执行或者是如果线程已经没有空闲那么就要加入到阻塞队列,如果阻塞队列也满了那么就要创建救急线程
execute
//32位,这里把int的高3位拿来充当线程池状态,后29位拿来充当当前运行worker的数量
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
//存放任务的阻塞队列
private final BlockingQueue<Runnable> workQueue;
//worker的集合,用set来存放
private final HashSet<Worker> workers = new HashSet<Worker>();
//历史达到的worker数最大值
private int largestPoolSize;
public void execute(Runnable command) {
//没有任务抛出异常
if (command == null)
throw new NullPointerException();
//ctl是线程的状态,判断当前线程的状态
int c = ctl.get();
//如果线程池执行任务小于核心线程
if (workerCountOf(c) < corePoolSize) {
//添加线程处理任务
if (addWorker(command, true))
return;
c = ctl.get();
}
//如果执行任务大于核心线程,判断线程池是不是在工作,如果是就把任务加入到队列
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
//再次判断线程池如果不是在工作就移除任务,执行拒绝策略,(可能线程池结束)
if (! isRunning(recheck) && remove(command))
reject(command);
//如果有效线程数量是0
else if (workerCountOf(recheck) == 0)
//那么就需要创建一个临时线程,false使用的界限是maxPoolSize,如果任务为空的线程会直接去任务队列里面找。
addWorker(null, false);
}
//创建临时线程,如果无法创建那么就执行拒绝策略
else if (!addWorker(command, false))
reject(command);
}
- 先看核心,再看队列,最后才看是否有救急线程
addWorker源码
- 判断线程池状态,如果是stop和shutdown那么立刻停止返回false
- 如果没问题那么就CAS+while来修改状态添加线程,如果添加失败首先去查询一下状态是否改变,如果发现状态改成stop或者shutdown再次回到外层的for返回false。
- 没问题下面就是创建线程worker,添加成功之后开启线程(线程的开启在这里)
- 很明显这里的t其实就是worker内部的thread,也就是由worker内部的thread来执行任务。
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
//这个状态变量
int c = ctl.get();
//获取线程池状态
int rs = runStateOf(c);
//如果是shutdown状态或者是stop就无法加入
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
//CAS+while重试修改状态
for (;;) {
int wc = workerCountOf(c);
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
if (compareAndIncrementWorkerCount(c))//修改状态成功那么结束循环
break retry;
//再次获取状态如果发现被改变,重新从最外层for开始
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
//创建和加入线程
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
//加入成功
workerAdded = true;
}
} finally {
mainLock.unlock();
}
//如果加入成功那么就开启线程
if (workerAdded) {
t.start();
//线程开启成功
workerStarted = true;
}
}
} finally {
//如果开启失败执行别的方法
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
Worker的结构
- thread一个内部线程,用来执行任务,execute里面开启的就是这个线程
- AQS,用于获取任务的时候和执行任务的时候保证线程安全,任务不被取出和执行两次
- 而且实现了runnable
- run方法调用runWorker,而且把自己当成锁传过去,保证线程安全
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable
{
/**
* This class will never be serialized, but we provide a
* serialVersionUID to suppress a javac warning.
*/
private static final long serialVersionUID = 6138294804551838833L;
/** Thread this worker is running in. Null if factory fails. */
//用于执行任务的线程
final Thread thread;
/** Initial task to run. Possibly null. */
//存放的当前准备执行的任务
Runnable firstTask;
/** Per-thread task counter */
//完成任务数量的总数
volatile long completedTasks;
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
public void run() {
//ThreadPoolExecutor的方法
runWorker(this);
}
。。。。AQS的实现方法
}
ThreadPoolExecutor的运行方法
这个地方直接run的原因就是,这个方法调用者是worker
- execute开启线程之后线程可以被打断,而且不断循环寻找任务去执行
final void runWorker(Worker w) {
//获取当前线程
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
//允许被中断
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
//如果有任务直接执行,如果没有就去队列找,如果队列也没有那么结束循环
while (task != null || (task = getTask()) != null) {
//锁住,给shutdown方法看到,shutdown也要给他加锁,如果发现线程正在执行那么就不会中断
w.lock();
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
//执行任务前的拓展
beforeExecute(wt, task);
Throwable thrown = null;
try {
//直接执行任务
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
//执行任务后的拓展
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
getTask
- 检查线程池状态,shutdown或者stop就返回null
- 然后计算有效线程个数,如果超过核心数,那么就要看看是不是核心线程是否设置会等待超时销毁,或者是有效线程过多,那么在取任务返回给线程的时候就会设置等待超时时间keepAliveTime,如果等待超时,那么worker自动销毁。
private Runnable getTask() {
boolean timedOut = false; // Did the last poll() time out?
for (;;) {
//获取状态
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
//如果发现状态是shutdown或者是stop或者是队列是空那么就返回null
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
// Are workers subject to culling?
//这里的意思其实是看核心线程是不是也设置了等待超时销毁,或者有效线程数大于核心线程数
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
//如果获取任务超时或者是有效线程数太多,那么就会修改有效线程数,减少线程
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
//修改状态,减少一个有效线程
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
//取出普通任务或者是超时任务,如果设置了等待超时那么下次队列没有任务进来超过时间就会自动销毁worker
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
- 本质上就是execute三部曲检查线程池状态、创建线程、开启线程。然后就是线程自旋while等待任务,如果任务大于核心线程那么先存入队列,如果队列满了,那么尝试创建救急线程,救急线程也不够那么就拒绝策略。
- 最后执行完任务之后,线程自旋等待的时候会判断是否设置核心线程超时,或者有效线程数大于核心线程数,那么就会给任务队列设置一个超时销毁任务,交给线程执行,一旦超时立刻销毁worker
- worker是锁也是runnable也内涵线程。
5.原子类
说说原子类的原理
- 其实就是依靠CAS+volatile和native方法保证取到的数值是一个最新的值,而且是一个原子操作
普通的int会有什么问题?
- i++这里其实包括了多条指令,get,add,put,会发生线程切换的时候指令交错导致最后数据计算错误
分类
单个基本类型
- AtomicIteger
- AtomicBoolean
数组
- AtomicIntegerArray
引用(处理对象赋值的原子性)
- AtomicReference
对象属性修改类型
- AtomicIntegerFieldUpdater
使用方式就是通过newUpdater来传对象class和修改字段,等到要修改的时候调用方法和传入要修改的对象就可以了
class AtomicIntegerTest {
public static void main(String[] args) {
AtomicIntegerFieldUpdater<User> user=AtomicIntegerFieldUpdater.newUpdater(User.class,"age");
User user1 = new User("123", 23);
System.out.println(user.getAndIncrement(user1));
System.out.println(user.get(user1));
}
}
class User {
private String name;
public volatile int age;
public User(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
ABA问题如何解决?
- 实际上就是原子类虽然可以通过对比旧值来得知是否被其它线程修改但是唯一避免不了的情况就是。线程1去想把A修改为B,在这个时候切换到了线程2那么线程2的任务是把A改成B再把B改成A,那么再次切换到线程1把A改成B但是前面其实已经修改过但是没有记录到,因为还是旧值对比新值导致线程1判断失误
问题的应用场景?
比如你要做个优惠活动,卡内小于100的人可以获取20块钱奖励。那么这个时候老板采用CAS和while操作账户,但是增加了其中一个账户的钱之后这个用户刚好又去消费20块,那么就会被重复奖励。导致老板损失很大。
6.AQS
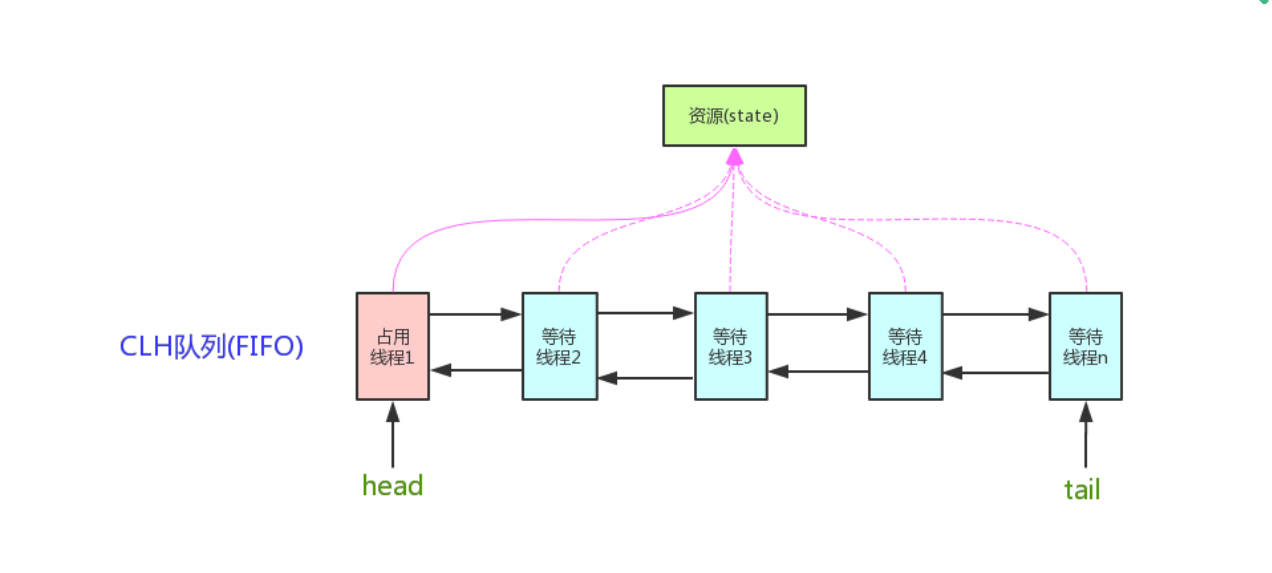
6.1说说AQS的原理
如果共享资源空闲,那么当前请求共享资源的线程设置有效线程,并且锁定共享资源。如果共享资源被占用那么其他线程就要进入阻塞队列等待
6.2AQS对资源的共享方式?
- Exclusive独占,只能一个线程执行,ReentrantLock
- Shared分享可以多个线程一起执行。CountDownLatch、Semaphore、CycliBarrier
AQS的底层实现?
使用的是模板方法
- isHeldExclusive()线程是否独占资源
- tryAcquire(int)独占方式,尝试获取,true成功
- tryRelease(int)独占方式,释放资源
- tryAcquireShared(int)共享方式
- tryReleaseShared(int)共享方式
其它方法都是final不能被子类实现
6.3AQS组件总结
- Semaphore信号量,限制线程执行的个数,允许多线程访问
- CountDownLatch倒计时器,协调多个线程同步执行
- CyclicBarrier:循环栅栏功能更强大,可以重用