提前声明:该专栏涉及的所有案例均为学习使用,如有侵权,请联系本人删帖!
一、前言
- 目的:今天我们搞点小姐姐的照片
- 网站:https://pic.sogou.com/pics
- 所需要的工具:
- 环境:python3.6
- 开发工具:pycharm
- 模块:requests
二、代码分析
首先我们进入搜狗图片,输入小姐姐
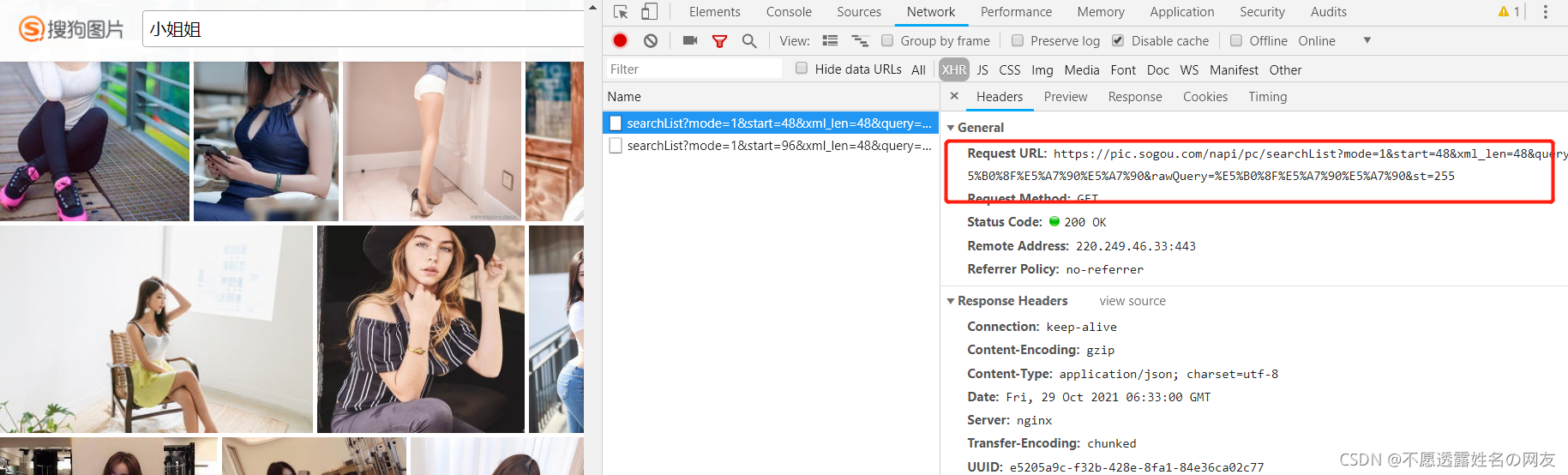
这么多小姐姐,确实有点按捺不住躁动的心。抓包测试,发现链接不一样
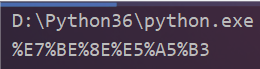
我们知道这是转换了编码
from urllib.parse import quote
print(quote('美女'))
继续往下,我们看到该链接返回来图片链接列表
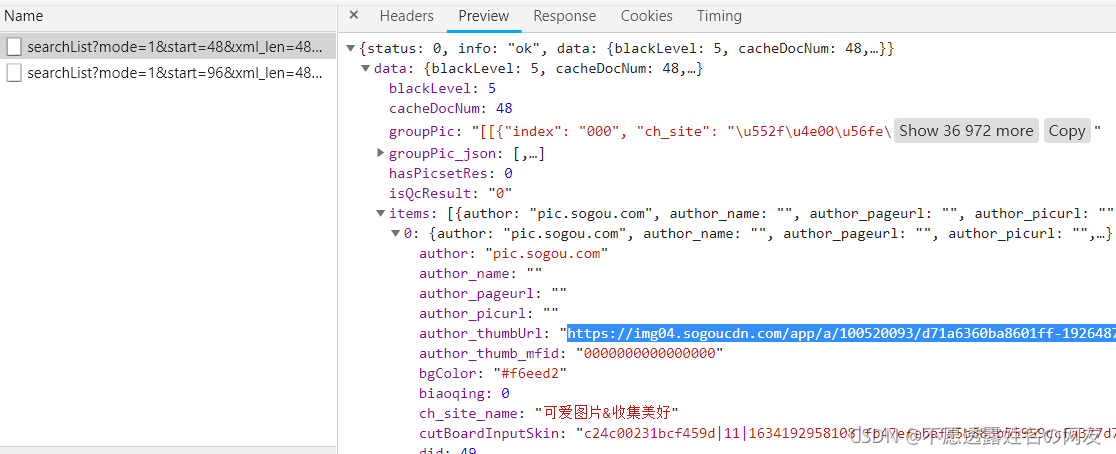
然后我们往下翻图片,发现链接变化
扫描二维码关注公众号,回复:
13170588 查看本文章

https://pic.sogou.com/napi/pc/searchList?mode=1&start=48&xml_len=48&query=%E7%BE%8E%E5%A5%B3
https://pic.sogou.com/napi/pc/searchList?mode=1&start=96&xml_len=48&query=%E7%BE%8E%E5%A5%B3
https://pic.sogou.com/napi/pc/searchList?mode=1&start=144&xml_len=48&query=%E7%BE%8E%E5%A5%B3
得到规律,应该是每次返回48张图片,每次start是上一次的48的倍数值,query是查询词,其他可以不变,因此循环的时候要注意哦
for start in range(0, 1000, 48)
接着我们还有把图片保存下载,晚上偷偷欣赏
with open(r'D:\CODE\其他代码\爬虫案例\pic\{}.jpg'.format(int(time.time())), 'wb') as f:
content = requests.get(pic_url, verify=False, timeout=3).content
f.write(content)
print('{}图片下载成功'.format(pic_url))
三、完整代码
# -*- coding: utf-8 -*-
import os
import time
import requests
from urllib.parse import quote
def get_keyword_pic_url_list(keyword, start):
query = quote(keyword)
url = 'https://pic.sogou.com/napi/pc/searchList?mode=1&start={}&xml_len=48&query={}'.format(start, query)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3877.400 QQBrowser/10.8.4506.400'
}
r = requests.get(url, headers=headers, verify=False)
if r.status_code == 200:
# 开始解析
try:
pic_url_list = []
items = r.json()['data']['items']
for item in items:
pic_url = item['picUrl']
pic_url_list.append(pic_url)
return pic_url_list
except Exception as e:
print(e)
return []
else:
return []
# 下载图片
def dowload_pic(pic_url_list):
if not os.path.exists(r'D:\CODE\其他代码\爬虫案例\pic'):
os.makedirs(r'D:\CODE\其他代码\爬虫案例\pic')
for pic_url in pic_url_list:
try:
with open(r'D:\CODE\其他代码\爬虫案例\pic\{}.jpg'.format(int(time.time())), 'wb') as f:
content = requests.get(pic_url, verify=False, timeout=3).content
f.write(content)
print('{}图片下载成功'.format(pic_url))
except Exception as e:
print(e)
if __name__ == '__main__':
for start in range(0, 1000, 48):
pic_url_list = get_keyword_pic_url_list('美女', 48)
dowload_pic(pic_url_list)
兄弟们,今天晚上冲了!