前言
在经典搜索算法中,搜索过程是系统的探索状态空间,通过在内存中保留一条或多条路径和记录路径中的每个结点的选择,当找到目标的时,到达目标的路径就是问题的一个解,比如说在罗马尼亚问题中,关注的是到达目标状态的路径,因此在搜索的过程中,需要在内存中保留一颗搜索树,这对内存是很大的挑战,或者说这类问题有着无限的状态空间,这甚至可能直接导致经典搜索算法失去完备性。然而在许多问题中,到达目标的路径是不相关的,搜索更多的关注不是路径,而是结果,更加关注能否达到某个状态,对于这类问题,可以考虑不同的算法来求解,比如说经典的八皇后问题,该问题关注就是能否找到一个状态,使得在该状态下皇后的位置没有冲突,这种问题就不在乎求解目标状态的路径,而更关注目标状态是什么样的,所以对于这种问题我们不必要像经典搜索那样,系统的探索状态空间,而是仅仅关注当前的状态,以及采取什么样的行动使得当前状态转换成目标状态,这样使得在内存中只需要保存一个当前状态,内存消耗仅仅是常数级别,而且对于状态空间无限的情况依然能找到合理的解。
离散空间的局部搜索
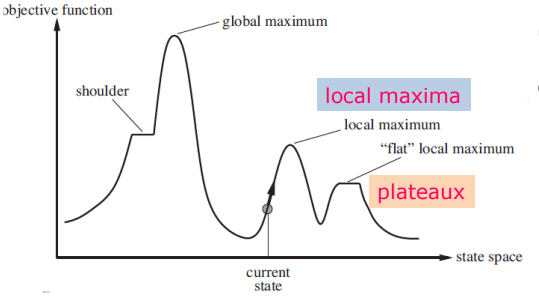
局部搜索算法从单个当前结点出发,通常只移动到它的邻近状态,一般情况下不保留搜索路径,虽然局部搜索算法不是系统化的,但是它有两个关键的优点:仅使用很少的内存,通常是常数;经常能在系统化算法不适用的很大或无限的状态空间中找到合理的解。通常使用状态空间地形图(如下)来理解局部搜索,地形图既有“坐标”(表示状态),又有“标高”(表示代价或者目标函数)。若标高对应代价,则目标就是找到最低谷 ——即全局最小值;若标高对应目标函数,则目标就是找到最高峰 —— 即全局最大值。
0x1 爬山法
为了找到最高峰,通常可以采用贪心的策略,即每次找到最陡的状态进行替换目前的状态,算法在到达一个峰值的时候终止,邻接状态中没有比它值更高的。这也被称为最陡爬山法,其算法伪代码如下:

显然,最陡爬山法很容易遇到局部极大值、山脊、高原的问题,为了进一步改善,可以采用一种优化的策略,即每次在上山移动中在所有好的后继中随机选择一个进行迭代,这也被称为随机爬山法,这种算法通常比最陡爬山法的收敛速度慢很多,但是可能会找到更好的解。
在随机爬山法中,每次在所有的好的后继中选择,那么就需要保存所有的后继状态,如果后继很多的话,则可能对内存消耗过大,所以可以通过首选爬山法来实现它,即随机地生成后继结点直到生成一个优于当前结点的后继,这样就不需要把后继的状态信息保存,节约了内存。
以上几种爬山法都是不完备的,他们都会因为局部极大值卡住而找不到目标。引入随机重启爬山法,即如果没有成功,则再次重新搜索,它通过随机生成初始状态来导引爬山法搜索,直到找到目标(该算法的完备性接近于1)。随机重启爬山法分为串行的和并行的。
0x2 模拟退火法
爬山法搜索从来不下山,即不会向值比当前结点低的方向搜索,它肯定是不完备的,因为会被卡在局部极大值处。而纯粹的随机行走算法 —— 就是从后继集合中完全等概率的随机选取后继 —— 是完备的,但是效率极低。因此把爬山法和随机行走法以某种方式结合,就得到了模拟退火算法(最类似于爬山法中的首选爬山法)。模拟退火算法的思想就是通过允许一些不好的行为(使代价变高),来避免局部最优值,但是对这些不好行为的频率是在算法的迭代过程中逐渐下降的。其算法伪代码如下:

0x3 局部束搜索
局部束搜索算法的思想:从 k 个随机生成的状态开始,每一步生成 k 个状态的所有后继状态,如果其中有一个是目标状态,则算法停止,否则从刚刚生成的整个后继列表中选择 k 个最佳的后继,重复此过程。
注意局部束搜索算法不同与并行的随机重启算法,因为在随机重启中,每个搜索的过程是独立互不受影响的。同时,由于局部束搜索算法是选择 k 个最佳的后继,所以可能会很快使得其状态集中到状态空间的一小块区域,无法避免局部最优解问题,因此引入随机束搜索,他不再选择 k 个最佳的后继,而是根据状态值给每个状态生成一个合理性概率,根据概率随机的选择 k 个后继。
0x4 遗传算法
遗传算法是随机束搜索的一个变种,非常像一个繁殖过程。遗传算法主要包含以下要素:
- 一个状态被表示成一个串。
- 评估函数:当状态更好(即状态更接近于目标状态),则其评估函数值更高。
- 从 k 个随机生成的状态开始,这些状态被视为一个种群。
- 一个后继状态由两个双亲状态结合生成。
- 通过选择(根据评估函数选择双亲)、杂交(双亲结合出下一代)、变异(下一代会依据一定的概率产生变异)生成下一代状态。
- 种群中有多少个状态,就要生成多少的状态。
其算法伪代码实现如下:

连续空间中的局部搜索
因为连续空间中状态空间也是无穷的,所以在离散空间中使用的算法只有首选爬山法和模拟退火法可以适用于连续空间,因为他们每次迭代只考虑一个随机的状态。对于连续空间中的迭代,可以使用类似最陡爬山法的梯度上升法,其迭代公式如下:

其中 α 代表步长,也称为学习率,如果它的值太小,则迭代速度会很慢,如果它的值太大,则可能在迭代过程中越过最优解。为了解决 α 的大小问题,可以换用 Newton-Raphson 来迭代:

其中,H 是二阶导数的 Hessian 矩阵。
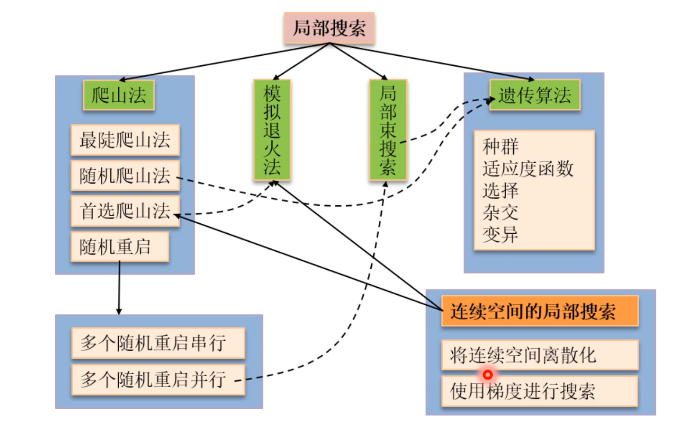
局部搜索算法汇总