CPU——核心,也可理解为MPU,而MCU微控制器表示包括CPU、片上外设(如存储器控制器)在内。
处理器——可能包括多个CPU
处理器系统——可能包括多个处理器
一、处理器体系结构
1. CISC –复杂指令集计算机
在CISC指令集的各种指令中,大约有20%的指令会被反复使用,占整个程序代码的80%。而余下的80%的指令却不经常使用,在程序中只占20%。代表有X86系列处理器。
2.RISC—精简指令集计算机
RISC结构优先选取使用频最高的简单指令,避免复杂指令;将指令长度固定,指令格式和寻地方式种类减少;以控制逻辑为主,不用或少用微码控制等。代表有ARM系列处理器。
RISC体系结构应具有如下特点:
采用固定长度的指令格式,指令归整、简单、基本寻址方式有2~3种。
使用单周期指令,便于流水线操作执行。
大量使用寄存器,数据处理指令只对寄存器进行操作,只有加载/ 存储指令可以访问存储器,以提高指令的执行效率。
除此以外,ARM体系结构还采用了一些特别的技术,在保证高性能的前提下尽量缩小芯片的面积,并降低功耗:
所有的指令都可根据前面的执行结果决定是否被执行,从而提高指令的执行效率。
可用加载/存储指令批量传输数据,以提高数据的传输效率。
可在一条数据处理指令中同时完成逻辑处理和移位处理。
在循环处理中使用地址的自动增减来提高运行效率。
3. CISC—RISC的区别
(本小节不知道在哪里找的资料,忘记了,如果侵权秒删,目的是写一篇比较全的处理器相关文章)
这里就不去管细节,简单来谈一下,ARM和X86之间为什么不太具有可比性的问题。要搞清楚这个问题首先要明白什么是架构,之前也有很多人提到了架构不同,但架构是什么意思?它是一个比较抽象的概念,不太容易用几句话就解释清楚。
我们要明白CPU是一个执行部件,它之所以能执行,也是因为人们在里面制作了执行各种功能的硬件电路,然后再用一定的逻辑让它按照一定的顺序工作,这样就能完成人们给它的任务。也就是说,如果把CPU看作一个人,首先它要有正常的工作能力(既执行能力),然后又有足够的逻辑能力(能明白做事的顺序),最后还要听的懂别人的话(既指令集),才能正常工作。而这些集中在一起就构成了所谓的“架构”,它可以理解为一套“工具”、“方法”和“规范”的集合。不同的架构之间,工具可能不同,方法可能不同,规范也可能不同,这也造成了它们之间的不兼容——你给一个意大利泥瓦匠看一份中文写成的烹饪指南,他当然不知道应该干什么了。
如果还看不懂,没关系,我们继续。从CPU发明到现在,有非常多种架构,从我们熟悉的X86,ARM,到不太熟悉的MIPS,IA64,它们之间的差距都非常大。但是如果从最基本的逻辑角度来分类的话,它们可以被分为两大类,即所谓的“复杂指令集”与“精简指令集”系统,也就是经常看到的“CISC”与“RISC”。属于这两种类中的各种架构之间最大的区别,在于它们的设计者考虑问题方式的不同。我们可以继续举个例子,比如说我们要命令一个人吃饭,那么我们应该怎么命令呢?我们可以直接对他下达“吃饭”的命令,也可以命令他“先拿勺子,然后舀起一勺饭,然后张嘴,然后送到嘴里,最后咽下去”。从这里可以看到,对于命令别人做事这样一件事情,不同的人有不同的理解,有人认为,如果我首先给接受命令的人以足够的训练,让他掌握各种复杂技能(即在硬件中实现对应的复杂功能),那么以后就可以用非常简单的命令让他去做很复杂的事情——比如只要说一句“吃饭”,他就会吃饭。但是也有人认为这样会让事情变的太复杂,毕竟接受命令的人要做的事情很复杂,如果你这时候想让他吃菜怎么办?难道继续训练他吃菜的方法?我们为什么不可以把事情分为许多非常基本的步骤,这样只需要接受命令的人懂得很少的基本技能,就可以完成同样的工作,无非是下达命令的人稍微累一点——比如现在我要他吃菜,只需要把刚刚吃饭命令里的“舀起一勺饭”改成“舀起一勺菜”,问题就解决了,多么简单。
这就是“复杂指令集”和“精简指令集”的逻辑区别。可能有人说,明显是精简指令集好啊,但是我们不好去判断它们之间到底谁好谁坏,因为目前他们两种指令集都在蓬勃发展,而且都很成功——X86是复杂指令集(CISC)的代表,而ARM则是精简指令集(RISC)的代表,甚至ARM的名字就直接表明了它的技术:Advanced RISC Machine——高级RISC机。
到了这里你就应该明白为什么RISC和CISC之间不好直接比较性能了,因为它们之间的设计思路差异太大。这样的思路导致了CISC和RISC分道扬镳——前者更加专注于高性能但同时高功耗的实现,而后者则专注于小尺寸低功耗领域。实际上也有很多事情CISC更加合适,而另外一些事情则是RISC更加合适,比如在执行高密度的运算任务的时候CISC就更具备优势,而在执行简单重复劳动的时候RISC就能占到上风,比如假设我们是在举办吃饭大赛,那么CISC只需要不停的喊“吃饭吃饭吃饭”就行了,而RISC则要一遍一遍重复吃饭流程,负责喊话的人如果嘴巴不够快(即内存带宽不够大),那么RISC就很难吃的过CISC。但是如果我们只是要两个人把饭舀出来,那么CISC就麻烦得多,因为CISC里没有这么简单的舀饭动作,而RISC就只需要不停喊“舀饭舀饭舀饭”就OK。
这就是CISC和RISC之间的区别。但是在实际情况中问题要比这复杂许许多多,因为各个阵营的设计者都想要提升自家架构的性能。这里面最普遍的就是所谓的“发射”概念。什么叫发射?发射就是同时可以执行多少指令的意思,例如双发射就意味着CPU可以同时拾取两条指令,三发射则自然就是三条了。现代高级处理器已经很少有单发射的实现,例如Cortex A8和A9都是双发射的RISC,而Cortex A15则是三发射。ATOM是双发射CISC,Core系列甚至做到了四发射——这个方面大家倒是不相上下,但是不要忘了CISC的指令更加复杂,也就意味着指令更加强大,还是吃饭的例子,CISC只需要1个指令,而RISC需要5个,那么在内存带宽相同的情况下,CISC能达到的性能是要超过RISC的(就吃饭而言是5倍),而实际中CISC的Core i处理器内存带宽已经超过了100GB/s,而ARM还在为10GB/s而苦苦奋斗,一个更加吃带宽的架构,带宽却只有别人的十分之一,性能自然会受到非常大的制约。为什么说ARM和X86不好比,这也是很重要的一个原因,因为不同的应用对带宽需求是不同的。一旦遇到带宽瓶颈,哪怕ARM处理器已经达到了很高的运算性能,实际上根本发挥不出来,自然也就会落败了。
说到这儿大家应该也已经明白CISC和RISC的区别和特色了。简而言之,CISC实际上是以增加处理器本身复杂度作为代价,去换取更高的性能,而RISC则是将复杂度交给了编译器,牺牲了程序大小和指令带宽,换取了简单和低功耗的硬件实现。但如果事情就这样发展下去,为了提升性能,CISC的处理器将越来越大,而RISC需要的内存带宽则会突破天际,这都是受到技术限制的。所以进十多年来,关于CISC和RISC的区分已经慢慢的在模糊,例如自P6体系(即Pentium Pro)以来,作为CISC代表的X86架构引入了微码概念,与此对应的,处理器内部也增加了所谓的译码器,负责将传统的CISC指令“拆包”为更加短小的微码(uOPs)。一条CISC指令进来以后,会被译码器拆分为数量不等的微码,然后送入处理器的执行管线——这实际上可以理解为RISC内核+CISC解码器。而RISC也引入了指令集这个就逻辑角度而言非常不精简的东西,来增加运算性能。正常而言,一条X86指令会被拆解为2~4个uOPs,平均来看就是3个,因此同样的指令密度下,目前X86的实际指令执行能力应该大约是ARM的3倍左右。不过不要忘了这是基于“同样指令密度”下的一个假设,实际上X86可以达到的指令密度是十倍甚至百倍于ARM的。
最后一个需要考虑的地方就是指令集。这个东西的引入,是为了加速处理器在某些特定应用上性能而设计的,已经有了几十年的历史了。而实际上在目前的应用环境内,起到决定作用的很多时候是指令集而不是CPU核心。X86架构的强大,很多时候也源于指令集的强大,比如我们知道的ATOM,虽然它的X86核心非常羸弱,但是由于它支持SSE3,在很多时候性能甚至可以超过核心性能远远强大于它的Pentium M,这就是指令集的威力。目前X86指令集已经从MMX,发展到了SSE,AVX,而ARM依然还只有简单而基础的NEON。它们之间不成比例的差距造成了实际应用中成百上千倍的性能落差,例如即便是现今最强大的ARM内核依然还在为软解1080p H.264而奋斗,但一颗普通的中端Core i处理器却可以用接近十倍播放速度的速度去压缩1080p H.264视频。至少在这点上,说PC处理器的性能百倍于ARM是无可辩驳的,而实际中这样的例子比比皆是。这也是为什么我在之前说平均下来ARM只有X86几十分之一的性能的原因。
上面叙述其实就是为了说明一点,虽然现在ARM很强大,但它距离X86还是非常遥远,并没有因为这几年的进步而缩短,实际上反而在被更快的拉大。毕竟它们设计的出发点不一样,因此根本不具备多少可比性,X86无法做到ARM的功耗,而ARM也无法做到X86的性能。这也是为什么ATOM一直以来都不成功的原因所在——Intel试图用自己的短处去和别人的长处对抗,结果自然是不太好的,要不是Intel拥有这个星球上最先进的半导体工艺,ATOM根本都不可能出现。而ARM如果尝试去和X86拼性能,那结果自然也好不到哪儿去,原因刚刚也解释过了。不过这也不意味着ARM以后就只能占据低端,毕竟任何架构都有其优点,一旦有应用针对其进行优化,那么就可以扬长避短。X86的繁荣也正是因为整个世界的资源都针对它进行了优化所致。只要能为ARM找到合适的应用与适合的领域,未来ARM也未必不可以进入更高的层次。
理论上讲, 针对不同的任务设计不同的指令集可以达到效率最优, 例如TI的C55主要针对音频和调制解调, C64主要针对视频。ARM主要针对控制。其实就是在灵活性(软件)和速度/功耗(这个硬件加速器最擅长)。现在急需一种可以适用于异构CPU的并行OS和C编译器。如果用TI的OMAP写程序, ARM和DSP之间的协调是非常头痛的一件事情。
二、ARM核的处理器
1. ARM处理器系列

ARM Cortex 应用程序处理器 |
|
| Cortex™-A 系列 - 开放式操作系统的高性能处理器 |
|
| Cortex 应用程序处理器在高级工艺节点中可实现高达 2GHz+ 标准频率的卓越性能,从而可支持下一代的移动 Internet 设备。这些处理器具有单核和多核种类,最多提供四个具有可选NEON™多媒体处理模块和高级浮点执行单元的处理单元。 应用包括: |
|
ARM Cortex 嵌入式处理器 |
|
| Cortex-R 系列 - 面向实时应用的卓越性能 Cortex-M 系列 - 面向具有确定性的微控制器应用的成本敏感型解决方案 |
|
| Cortex 嵌入式处理器旨在为各种不同的市场提供服务。Cortex-M 系列处理器主要是针对微控制器领域开发的,在该领域中,既需进行快速且具有高确定性的中断管理,又需将门数和可能功耗控制在最低。而 Cortex-R 系列处理器的开发则面向深层嵌入式实时应用,对低功耗、良好的中断行为、卓越性能以及与现有平台的高兼容性这些需求进行了平衡考虑。 应用包括: |
|
| Cortex-M 系列 |
Cortex-R 系列 |
经典 ARM 处理器 |
| ARM11™ 系列 - 基于 ARMv6 架构的高性能处理器 ARM9™ 系列 - 基于 ARMv5 架构的常用处理器 ARM7™ 系列- 面向普通应用的经典处理器 |
| ARM 经典处理器适用于那些希望在新应用中使用经过市场验证的技术的组织。这些处理器提供了许多的特性、卓越的功效和范围广泛的操作能力,适用于成本敏感型解决方案。这些处理器每年都有数十亿的发货量,因此可确保设计者获得最广泛的生态体系和资源,从而最大限度地减少集成过程中出现的问题并缩短上市时间。 |
ARM 专家处理器 |
|
| SecurCore™ - 面向高安全性应用的处理器 FPGA Cores - 面向 FPGA 的处理器 |
|
| ARM 专家处理器旨在满足特定市场的苛刻需求。SecurCore 处理器在安全市场中用于手机 SIM 卡和识别应用,集成了多种既可为用户提供卓越性能,又能检测和避免安全攻击的技术。 ARM 还开发面向 FPGA 构造的处理器,在保持与传统 ARM 设备兼容的同时,方便用户产品快速上市。此外,这些处理器具有独立于构造的特性,因此开发人员可以根据应用选择相应的目标设备,而不会受制于特定供应商。 |
|
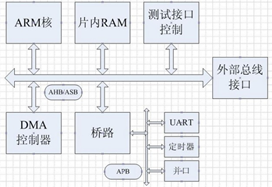
2. ARM核处理器的总线
ARM核的MCU属于SOC设计,即片上系统。ARM处理器使用基于AMBA规范的片上系统设计。AMBA规范主要包括了AHB(Advanced High performance Bus)系统总线和APB(Advanced Peripheral Bus)外围总线。如下图例:
3. ARM处理器的物理地址空间
32位的CPU,理论上可以使用的地址范围为4GB(物理地址)。 (S3C2440而言)存储器控制器占用这4GB物理地址空间的1GB。存储器控制器提供了访问外部设备所需要的信号,它支持8个BANKs,每个BANKs 为128MB,总共1GB的地址空间(范围为0x00000000-0x40000000)。BANKs0-7可以与NOR Flash、IDE接口、10M或100M网卡、扩展串口芯片、SDRAM等相连接。
存储器控制器的BANKs0-7与外设相连,比如内存、网卡等。而这些外设的控制也是通过寄存器来控制的,这些寄存器的物理地址占用4GB物理地址空间的0x4800000-0x5FFFFFFF。对于ARM处理器而言,4GB物理地址空间剩下部分地址空间没有编址,即没有使用。
4. 物理地址空间与虚拟地址空间的映射
有了MMU等内存管理单元后,许多多用户多进程操作系统通过MMU使得各个用户进程都拥有自己独立的地址空间,每个进程都认为自己拥有的地址空间为4GB,并且通过MMU内存访问权限的检查可以保护每个进程所用的内存不会被其他进程破坏,这个地址空间为虚拟地址空间。物理地址空间到虚拟地址空间的映射,在Linux操作系统中常使用函数为ioremap。
每个进程拥有的4GB虚拟地址空间,其中1GB为内核空间准备,3GB用户空间可以访问。