面试官常考的15道链表题,你会多少?
链表题,在平时练起来感觉难度还行。但是在面试的过程中,在那种氛围,面试者很容易因为紧张,导致面试表现不好。所以这里总结了一些链表最常见的练习题。反复练习,孰能生巧。希望能帮助到大家!!!

| 题目 | 在线OJ链接 | 难度 |
|---|---|---|
| 反转单向链表 | 牛客网 | 易 |
| 反转部分单向链表 | 牛客网 | 易 |
| 在链表中删除倒数第K个节点 | 牛客网 | 易 |
| 环形链表的约瑟夫环问题 | 牛客网 | 中 |
| 判断一个链表是否为回文结构 | 牛客网 | 易 |
| 将单链表按某值划分左边小、中间等于、右边大于 | 牛客网 | 易 |
| 单链表的选择排序 | 牛客网 | 易 |
| 单链表中每K个节点之间进行反转 | LeetCode | 中 |
| 复制一个带随机指针的单链表 | LeetCode | 中 |
| 合并两个有序的链表 | 牛客网 | 易 |
| 一种怪异节点的删除方式 | 牛客网 | 中 |
| 按照左右半区的方式重新组合链表 | 牛客网 | 中 |
| 在单链表中删除重复的节点 | LeetCode | 中 |
| 判断单链表是否有环,若有,返回第一个入环节点 | LeetCode | 易 |
//单链表结点
public class ListNode {
public int val;
public ListNode next;
public ListNode(int val) {
this.val = val;
}
}
文章目录
一、反转单向链表

题意:输入一个链表,反转链表之后,返回新链表的表头!
这道题,解法有好几种,我们这里就讨论两种思路。
方法一: 头插法与三指针法

头插法:定义pre 、cur和next引用。pre 指向前驱结点,cur指向当前结点,next指向后继结点。
- 首先保存后继结点next。
- 当next保存之后,cur的下一个结点就指向pre。
- 然后pre和cur分别往下走一步。
- 循环往复,由图可知,当cur == null时,循环结束。
//头插法
public ListNode reverseLinkList(ListNode head) {
if (head == null || head.next == null) {
//没有结点,或者只有一个结点的情况
return head;
}
ListNode pre = null; //前驱结点
ListNode cur = head; //当前结点
ListNode next = null; //后继结点
while (cur != null) {
next = cur.next; //首先保存后驱结点
cur.next = pre; //改变链表的指向
pre = cur; //pre和cur往下走一步
cur = next;
}
return pre;
}
//三指针法---只是在头插法的基础之上改了一下。本质上没有什么区别
public ListNode reverseLinkList(ListNode head) {
if (head == null || head.next == null) {
//没有结点,或者只有一个结点的情况
return head;
}
ListNode pre = null; //前驱结点
ListNode cur = head; //当前结点
ListNode next = null; //后驱结点
ListNode newHead = null;
while (cur != null) {
next = cur.next; //首先保存后驱结点
if (newHead == null) {
newHead = cur;
}
cur.next = pre; //改变链表的指向
pre = cur; //pre和cur往下走一步
cur = next;
}
return pre;
}
方法二:递归
思想:我们只需要一直往下递归,如果cur == null,说明pre这就是原来链表的最后一个结点。我们作为返回值,直接返回即可。递归函数有两个参数ListNode cur, ListNode pre,代表当前结点和上一结点。在找到最后一个结点后,返回的过程中,将cur的下一结点连上pre就行。
public ListNode reverseLinkList(ListNode head) {
if (head == null || head.next == null) {
return head;
}
return process(head, null); //第一次调用,上一结点就是null
}
public ListNode process(ListNode cur, ListNode pre) {
if (cur == null) {
return pre;
}
ListNode newHead = process(cur.next, cur); //递归调用下一结点
cur.next = pre; //连接pre
return newHead; //将头结点返回去
}
二、反转部分单向链表
这个题就是在反转链表的基础之上进行了改进,换汤不换药。核心代码还是那几行,这道题就是需要一些细节问题。我们先看看反转后的情况:
反转 第2个结点到第4个结点的情况:
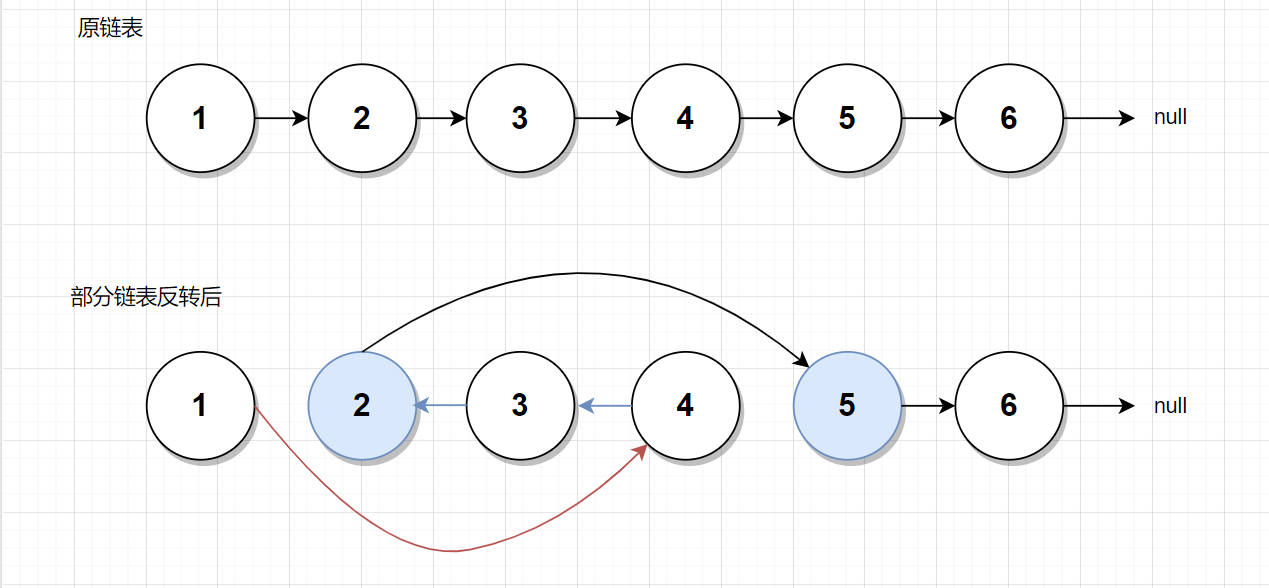
由上图可知,我们大概知道思路,该怎么对这个链表着手。
- 首先遍历链表,找到需要反转链表的头结点的上一个结点,对应上图就是
1号结点,定义变量名为left - 然后继续往下遍历链表,找到需要反转链表的尾结点 的下一个结点,对应上图就是
5号结点,定义变量名为right - 此时声明一个函数reverse,将参数
(left,开始结点,结束结点,right),转入进去,进行反转,反转后连接left和right即可
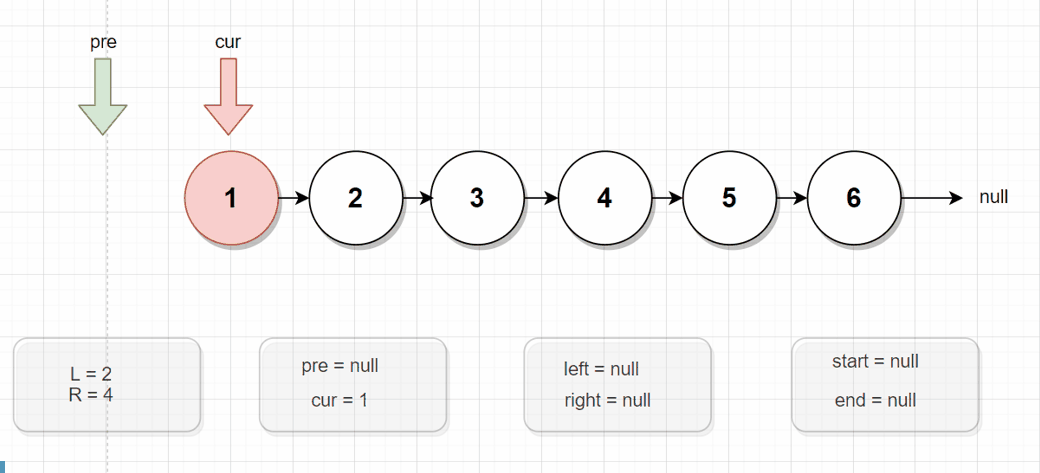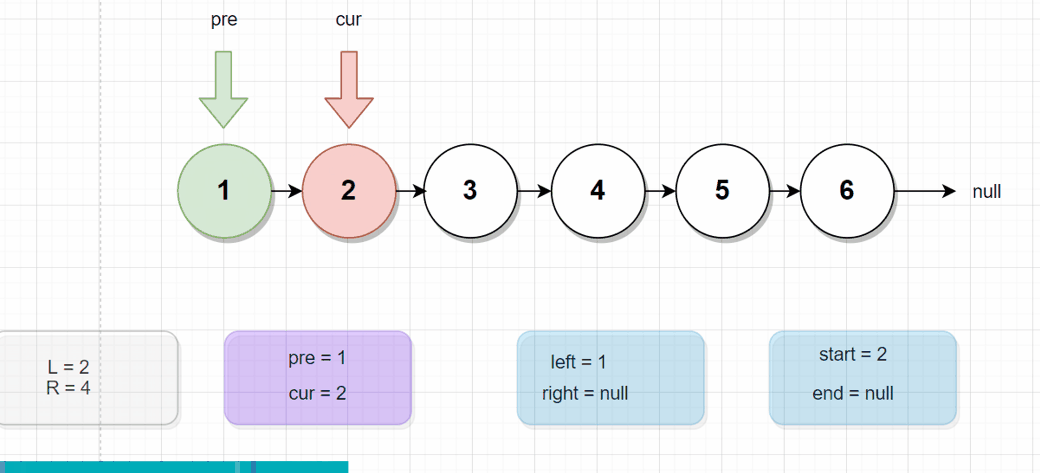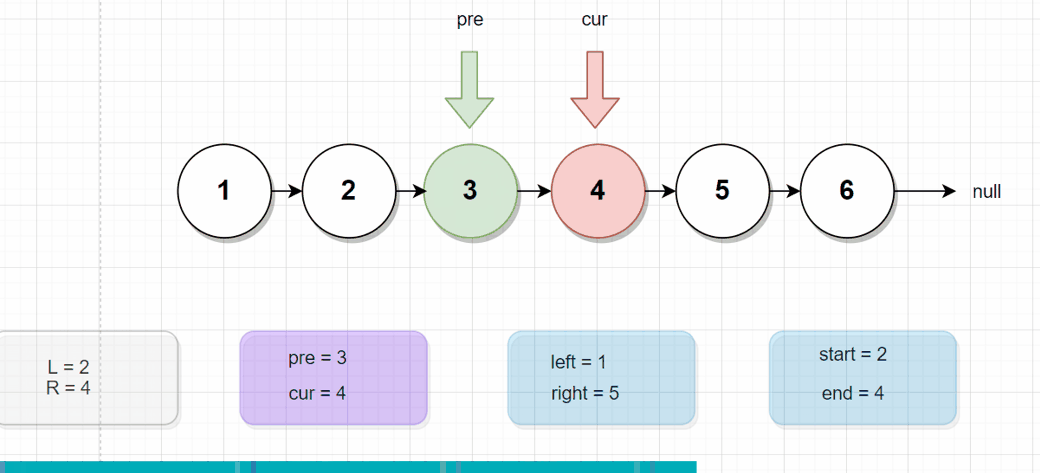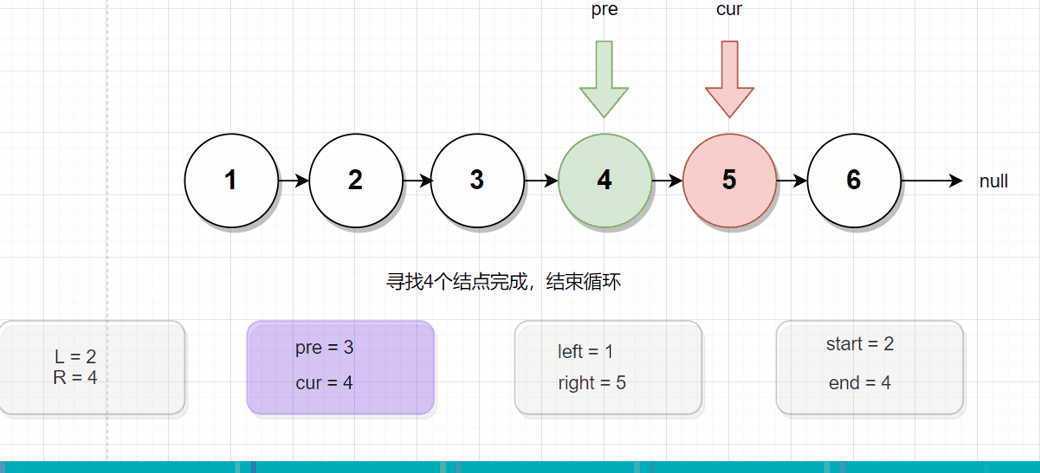
public ListNode reversePartList(ListNode head, int L, int R) {
if (head == null || head.next == null || L > R) {
//没有结点,或者只有一个结点的情况
return head;
}
ListNode cur = head;
ListNode pre = null; //临时变量 , pre 是 cur的前驱结点
ListNode left = null; //表头的上一个结点
ListNode right = null; //尾结点的下一个结点
ListNode start = null; //需要反转链表的表头
ListNode end = null; //需要反转链表的尾结点
for (int i = 1; i <= R && cur != null; i++) {
if (i == L) {
left = pre; //pre 是 cur的前驱结点
start = cur;
}
if (i == R) {
end = cur;
right = cur.next; //反转链表的尾结点 的下一结点
break;
}
pre = cur;
cur = cur.next;
}
reverse(left, start, end, right);
return left == null? end : head; //有可能反转后,头结点被换了。
}
public void reverse(ListNode left, ListNode start, ListNode end, ListNode right) {
ListNode next = null;
ListNode pre = right; //头结点需要连接right,比如上图 2号结点连接5号结点
while (start != right) {
next = start.next;
start.next = pre;
pre = start;
start = next;
}
//循环结束后,此时pre指向反转链表的尾结点,也就是上图的 4号结点
if (left != null) {
left.next = pre; //上图的 1号结点连接4号结点
}
}
总结:这道题找出4个关键结点,调用reverse函数即可。reverse函数跟第一题的差不多。
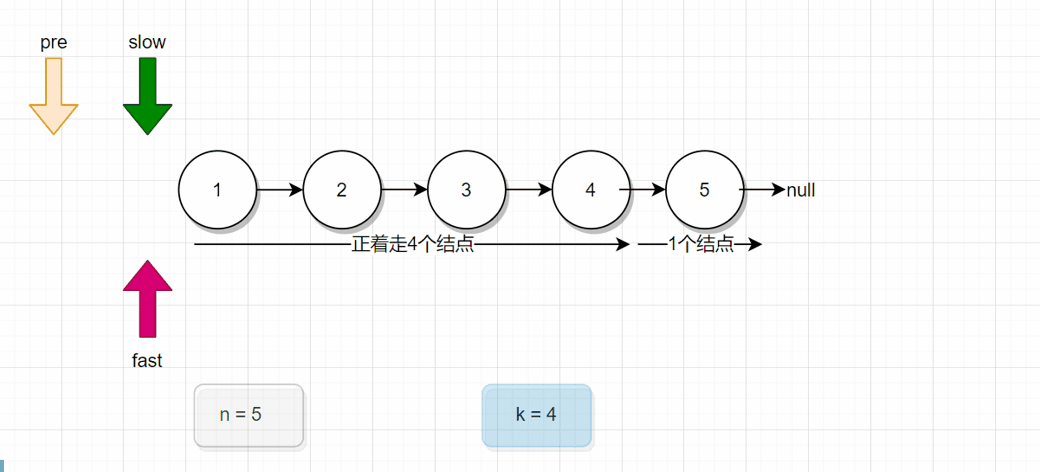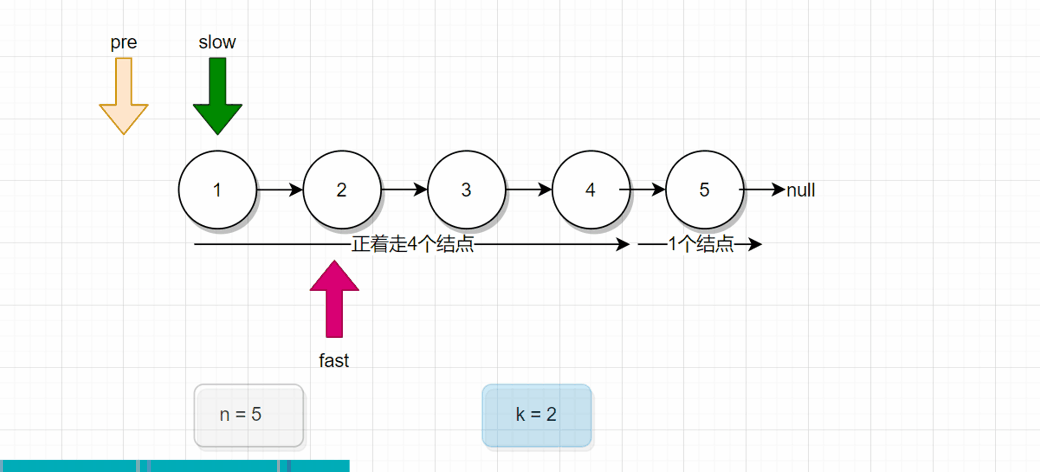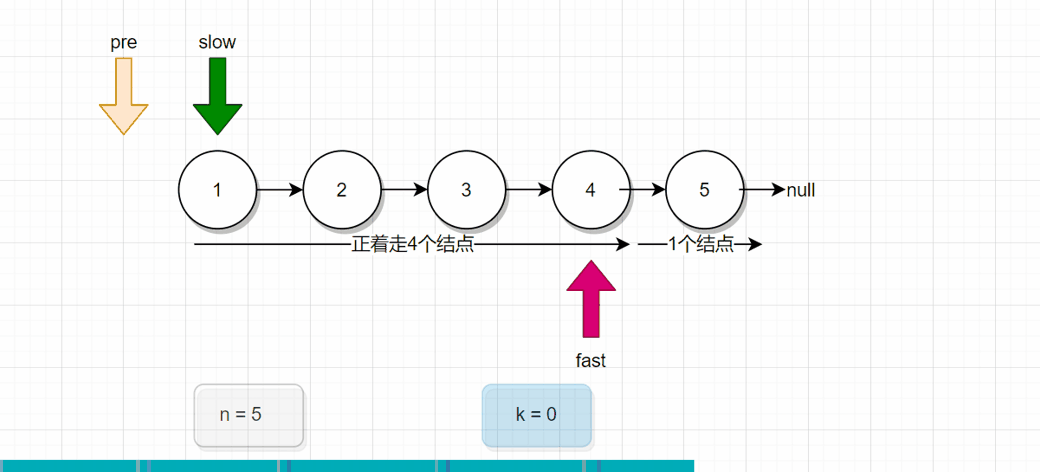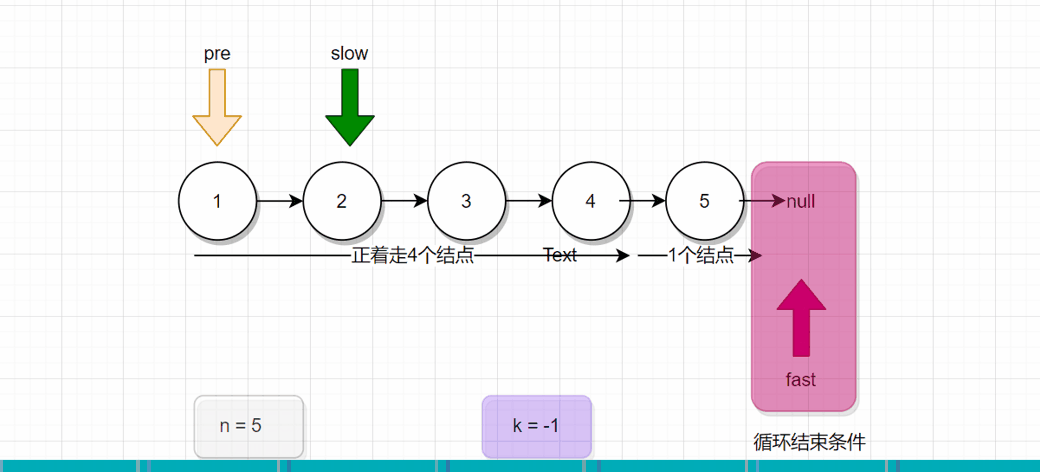
三、在链表中删除倒数第K个节点
题意:删除倒数第K个结点。跟另一道题很像“返回倒数第K个结点”。都是一样的意思。
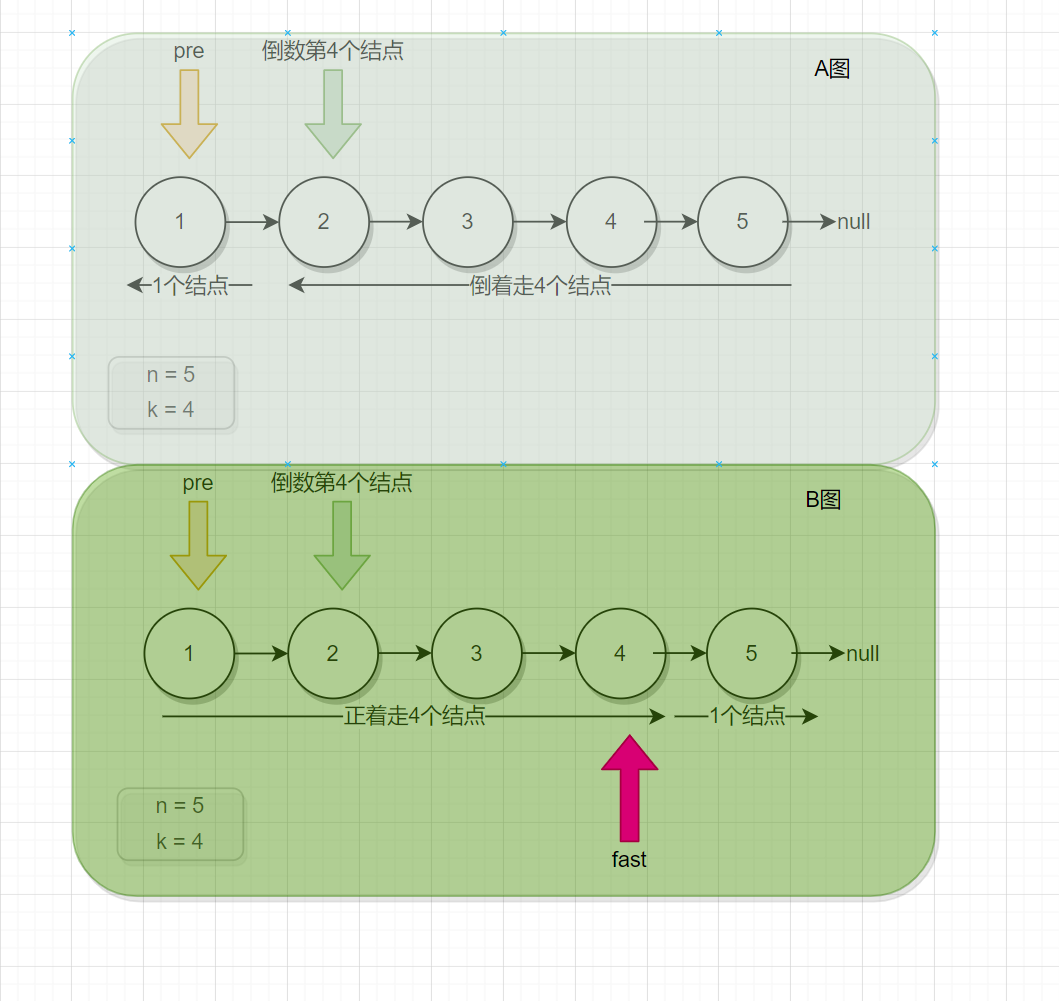
分析:对比上面两幅图,上面那一幅图是倒着走的情况,下面这一副是正着走的情况。 我们会发现下面那一幅图,当fast刚好走4个结点后,接下来pre和fast同时往下走一步,此时pre就是指向了2号结点。
也就是说,我们会发现一个规律,假设倒着走K步,我们定义两个引用变量fast和slow,fast先正着走K步后,slow才从头结点开始出发,此时fast和slow一起走,一次走一步,当fast来到尾结点时,此时的slow指向的结点,就是倒数第K个结点。(画草稿图,更容易理解)
public ListNode delBackKNode(ListNode head, int k) {
if (head == null || k < 1) {
return head;
}
ListNode slow = head;
ListNode fast = head;
ListNode pre = null; //slow的前驱结点
for (; fast != null; fast = fast.next) {
if (--k < 0) {
pre = slow; //pre紧跟着slow
slow = slow.next;
}
}
pre.next = slow.next; //C++的朋友,需要自己手动回收ListNode结点的内存
return head;
}
四、环形链表的约瑟夫环问题
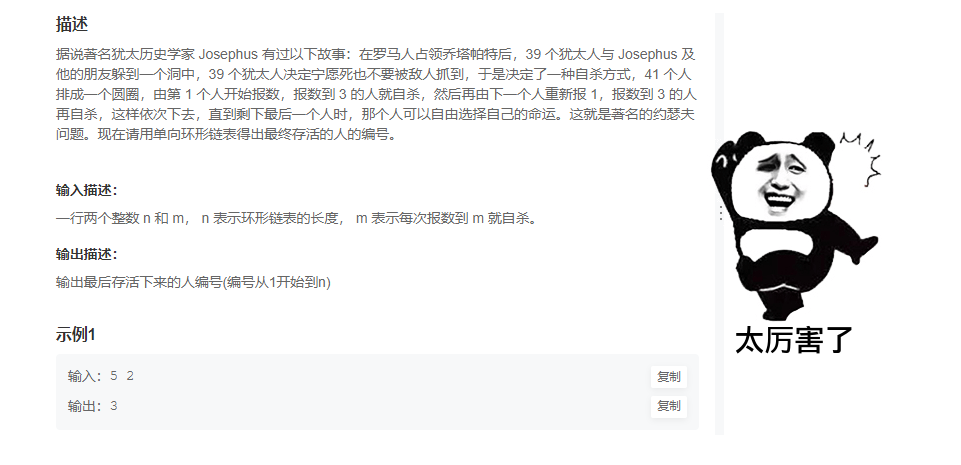
题意:总之就是一句话:给你两个数,一个数是循环链表的长度,另一个数是m,每个人报数,报到m的就出局。剩下的接着报数。返回最后剩下的那个结点。
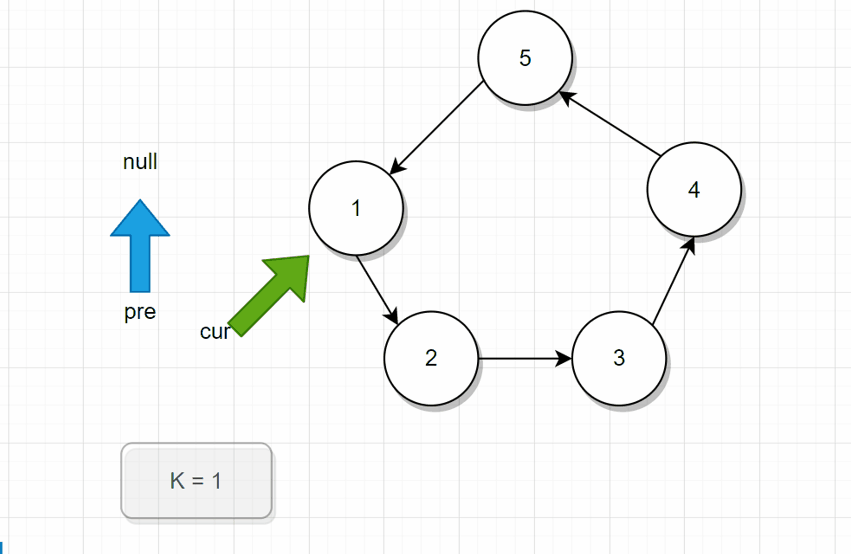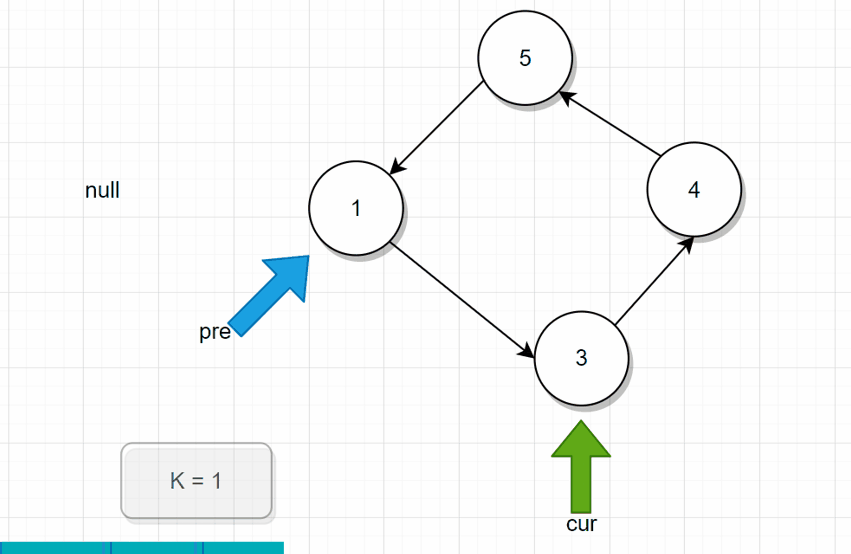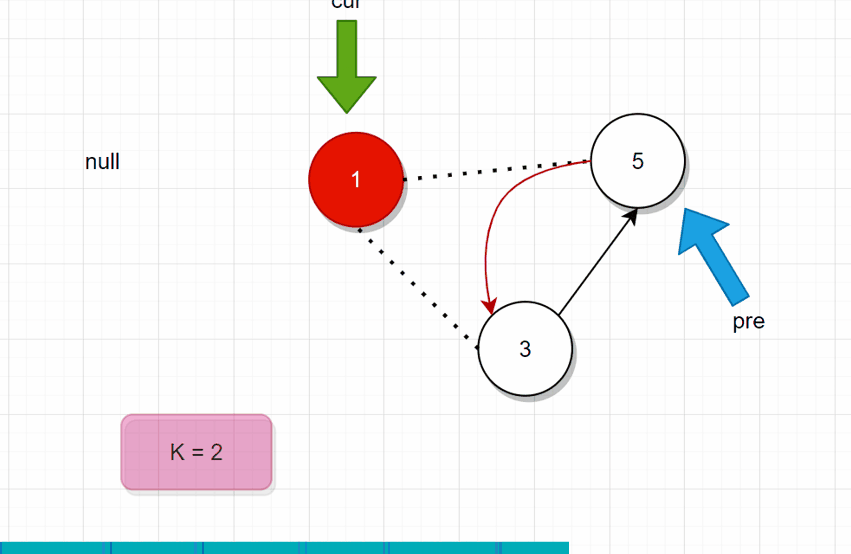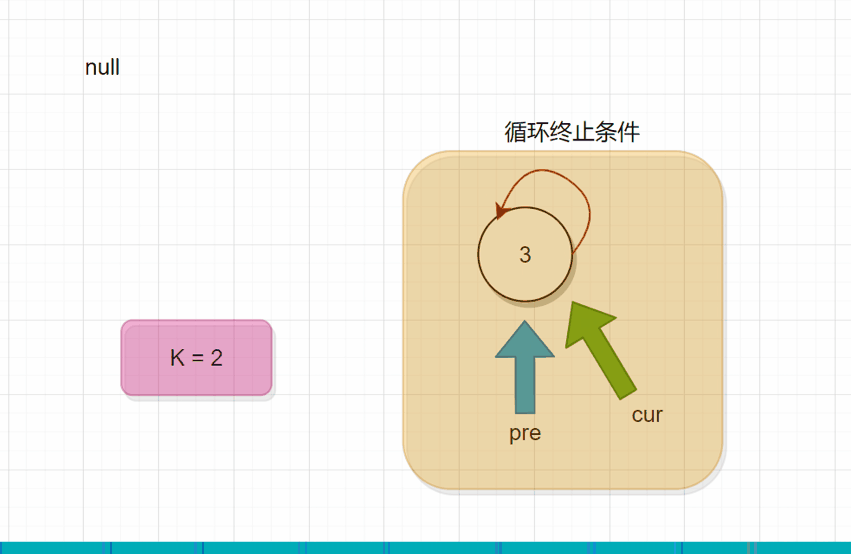
分析: 从头开始遍历,用一个变量记录当前报的数。pre指向前驱结点,cur指向当前结点。循环终止条件就是还剩下一个结点的时候。
public ListNode josephusKill(ListNode head, int k) {
if (head == null || head.next == head) {
//没有结点,或者只有一个结点的情况
return head;
}
int count = 1; //计数
ListNode pre = null;
ListNode cur = head;
while (cur != cur.next) {
//当自己的next指向自己时,说明只有一个结点了
if (count++ == k) {
pre.next = cur.next;
count = 1; //重置为1
} else {
pre = cur;
}
cur = cur.next;
}
return cur;
}
这个约瑟夫环问题,还有一个进阶版的。进阶版的和原题一样,只是测试的数据要多很多。所以一个个去建立循环链表,再去一个个的删除结点。时间效率就很低,感兴趣的朋友可以去看看《程序员代码面试指南》,书中有讲解,如何通过一些规律,来推导出剩下的那个结点,这里我们就不多讲了。
五、判断一个链表是否为回文结构

题意:判断一个单链表是不是回文结构。 回文结构就是:从中间为轴,左右两边对折起来,左右两边每个位置所对应的数值是一样的,比如1221,12321就是一个回文数.
方法一:: 判断是不是回文数,我们可以用一个容器先把整个链表的数据装在一起,这里就用栈,比如链表就是1 -> 2 -> 2 -> 1 ->null;我们压栈后的情况就是这样:
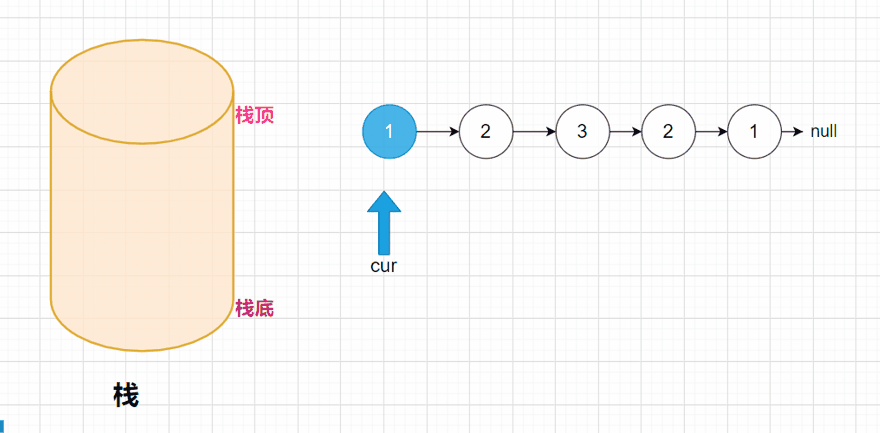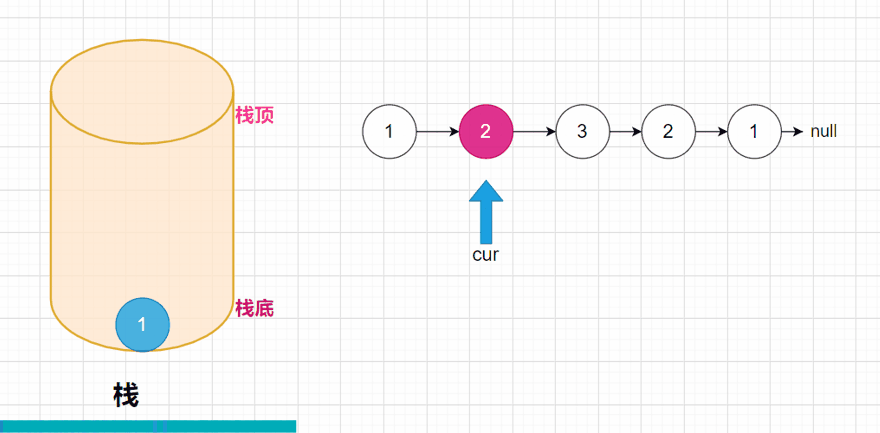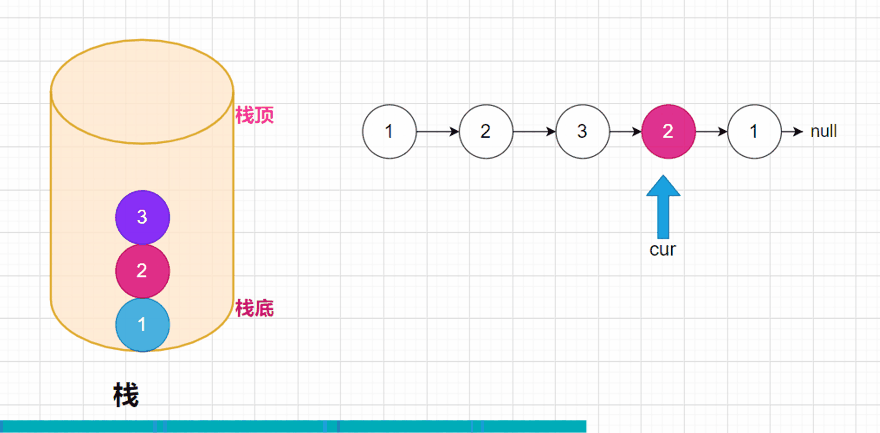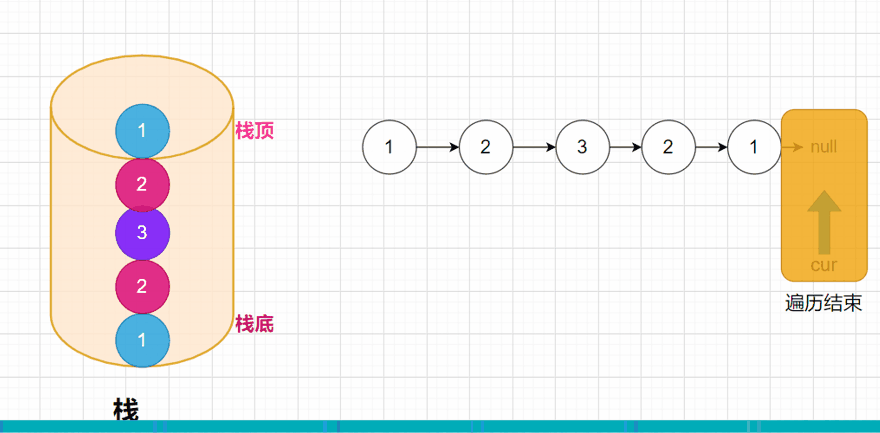
此时我们就已经将整个链表的全部数据压入到栈中,我们都知道,栈是先进后出的,所以在弹出数据的时候,是先弹出栈顶的元素。弹出的元素,我们再去和链表进行比较,如果其中有不相等的,说明这个链表就不是回文结构。
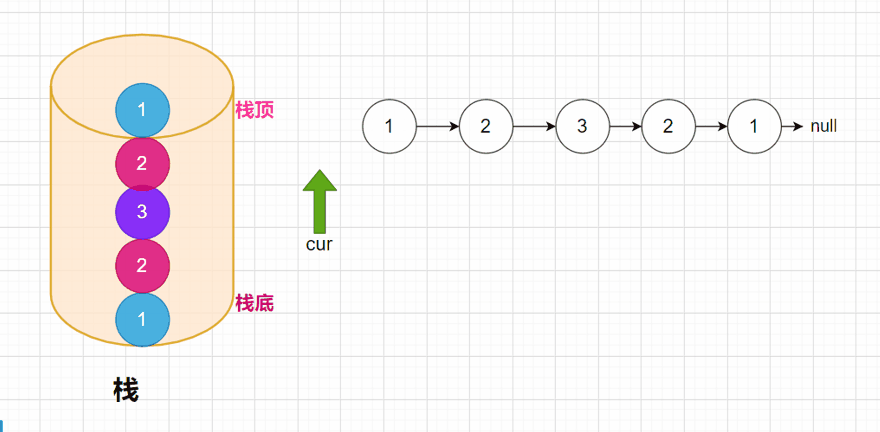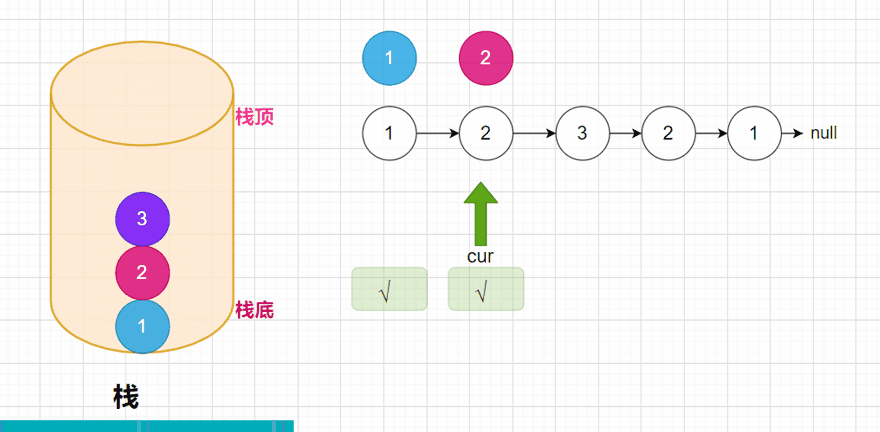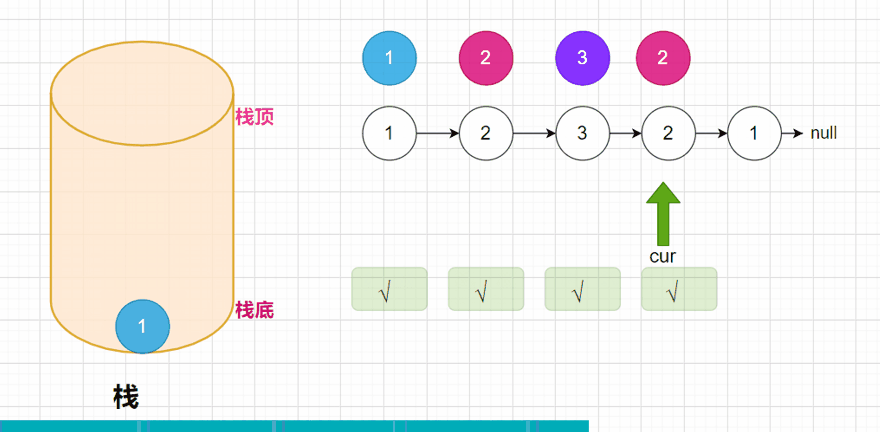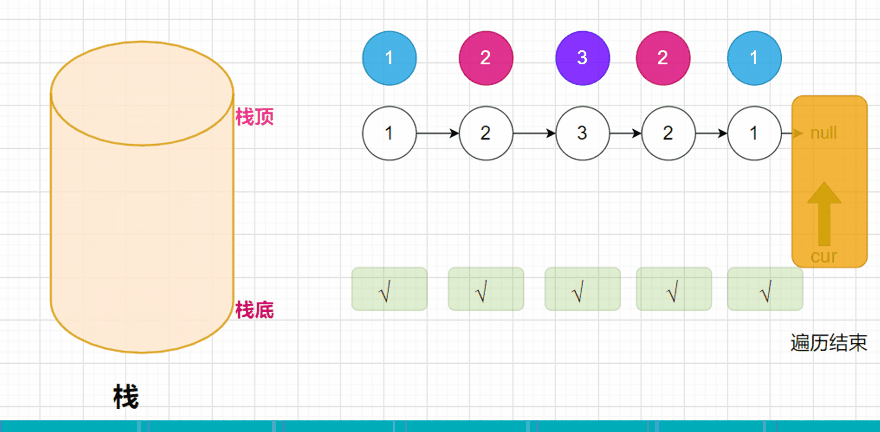
public boolean isPlalindromeList(ListNode head) {
if (head == null || head.next == null) {
return true;
}
Stack<Integer> stack = new Stack<>(); //栈
ListNode cur = head;
while (cur != null) {
stack.push(cur.val); //压栈
cur = cur.next;
}
cur = head;
while (cur != null) {
if (cur.val != stack.pop()) {
return false; //弹出的元素不相等的情况
}
cur = cur.next;
}
return true;
}
上面的代码,就是运用栈来求解。当然这个方法还可以优化空间复杂度,假设我只压入后半部分的数据,再去和前半部分链表进行比较,也是一样的效果。这里就不多赘述了,自己动手实现一下吧。
方法二: 反转后半部分的链表,优化空间复杂度O(1)
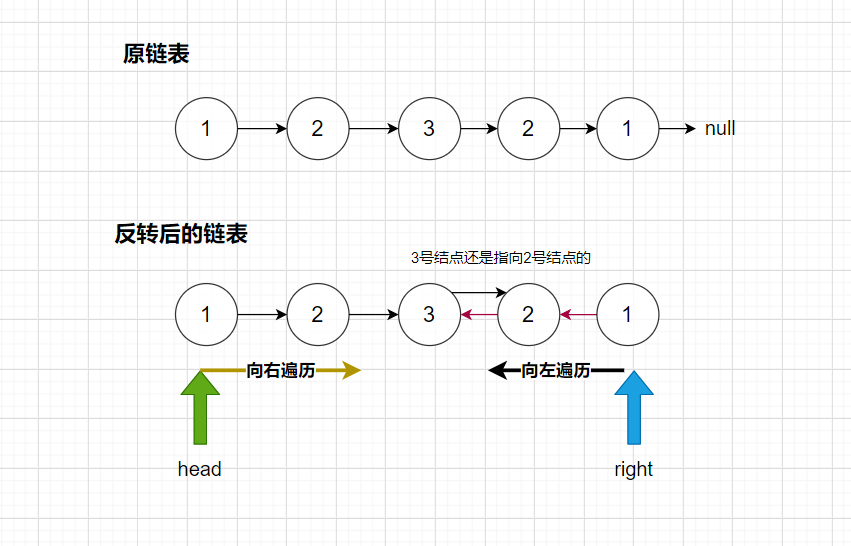
分析:一个向左遍历,一个向右遍历,每次都比较一下,如果有一个不相等。那就不是回文结构。返回结果前,要先把链表反转回来。
//进阶解法,将右边部分,反转链表,指向中间结点
public boolean isPlalindromeList3(ListNode head, int size) {
//size,是链表的总长度
if (head == null || head.next == null) {
return true;
}
boolean res = true;
ListNode leftStart = head;
ListNode rightStart = null;
ListNode cur = head;
for (int i = 0; i < size / 2; i++) {
cur = cur.next;
}
rightStart = reverseList(cur); //右半部分的头结点
cur = rightStart;
for (int i = 0; i < size / 2; i++) {
if (cur.val != leftStart.val) {
res = false;
break;
}
cur = cur.next;
leftStart = leftStart.next;
}
reverseList(rightStart); //恢复链表,不需要接收返回值。本身上一个结点的next域,没被修改
return res;
}
public ListNode reverseList(ListNode head) {
if (head == null || head.next == null) {
return head;
}
ListNode pre = null;
ListNode cur = head;
ListNode next = null;
while (cur != null) {
next = cur.next;
cur.next = pre;
pre = cur;
cur = next;
}
return pre;
}
六、将单链表按某值划分左边小、中间等于、右边大

题意:给你一个单链表,和一个数值。根据这个数值将单链表分为小于区、等于区和大于区。
方法一:跟“荷兰国旗问题”一样,我们只需将所有结点放到一个数组里面,然后在数组上做partition操作。具体的思想,前面的文章八大排序算法 中的快速排序,就是引用了这个思想,可以看一看。
public ListNode listPartiton(ListNode head, int pivot) {
if (head == null || head.next == null) {
return head;
}
ListNode cur = head;
int count = 0; //计算链表的长度
while (cur != null) {
count++;
cur = cur.next;
}
ListNode[] arr = new ListNode[count];
for (int i = 0; i < count; i++) {
//将所有结点放入数组
arr[i] = head;
head = head.next;
}
int left = -1; //小于区域的范围
int right = count; //大于区域的范围
int index = 0; //用于遍历数组的下标
while (index < right) {
//只要index没有和大于区域相遇,循环就继续
if (arr[index].val == pivot) {
index++; //等于区域,别动,index往后走即可
} else if (arr[index].val > pivot) {
swap(arr, index, --right); //切记,这里index还不能动。因为从后面拿前来的数据,还没有判断大小
} else {
swap(arr, index++, ++left);
}
}
for (int i = 1; i < count; i++) {
//连接每个结点
arr[i - 1].next = arr[i];
}
arr[count - 1].next = null; //最后一个结点的next,赋值null
return arr[0];
}
public void swap(ListNode[] arr, int left, int right) {
ListNode tmp = arr[left];
arr[left] = arr[right];
arr[right] = tmp;
}
方法二: 方法一空间复杂度O(N),可能还不能够得到面试官的青睐,现在再说一种空间复杂度O(1)的解法。
分析:题目是要我分为三个区域,我们就把这三个区域分别看成是3个独立的链表,每个链表都有头尾指针。我们只需要6个引用变量来指向这头尾结点即可。
如图:
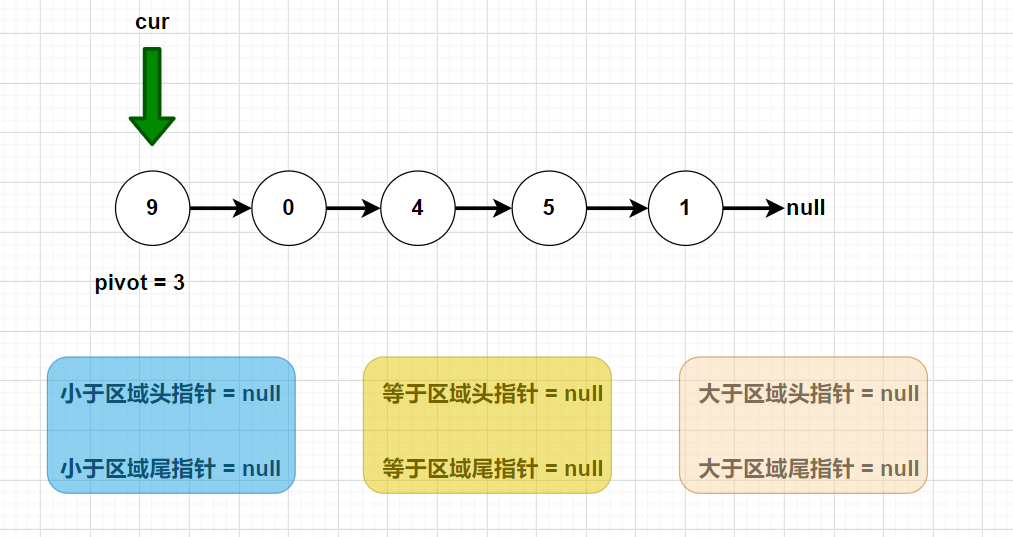
public ListNode listPartition2(ListNode head, int pivot) {
if (head == null || head.next == null) {
return head;
}
ListNode sH = null;
ListNode sT = null; //小于区域
ListNode eH = null;
ListNode eT = null; //等于区域
ListNode bH = null;
ListNode bT = null; //大于区域
while (head != null) {
ListNode next = head.next;
head.next = null;
if (head.val < pivot) {
if (sH == null) {
sH = head;
sT = head;
} else {
sT.next = head; //尾结点去连接
sT = head;
}
} else if (head.val == pivot) {
if (eH == null) {
eH = head;
eT = head;
} else {
eT.next = head; //尾结点去连接
eT = head;
}
} else {
if (bH == null) {
bH = head;
bT = head;
} else {
bT.next = head; //尾结点去连接
bT = head;
}
}
head = next; //往后走
}
//连接三个区域
if (sH != null) {
sT.next = eH;
eT = eH == null? sT : eT; //判断等于区域是否有结点
}
if (bH != null) {
eT.next = bH;
}
return sH != null? sH : (eH != null? eH : bH);
}
七、单链表的选择排序

题意:也就是说,在单链表上做选择排序。(选择排序:在一定的范围内,选择最大值或者最小值,把它放到最前面,循环往复)
方法一:也可以将所有结点放入数组,在数组上做选择排序,然后再连接起来。这样的算法能过OJ,面试官那里可能过不了。这里就不说了。
方法二:在单链表的基础之上,做选择排序操作。我们定义一个newHead,作为新的头结点。minPre指向最小结点的前驱结点。每一次循环进去,寻找当前链表中最小的结点,使其“挂”在newHead下。
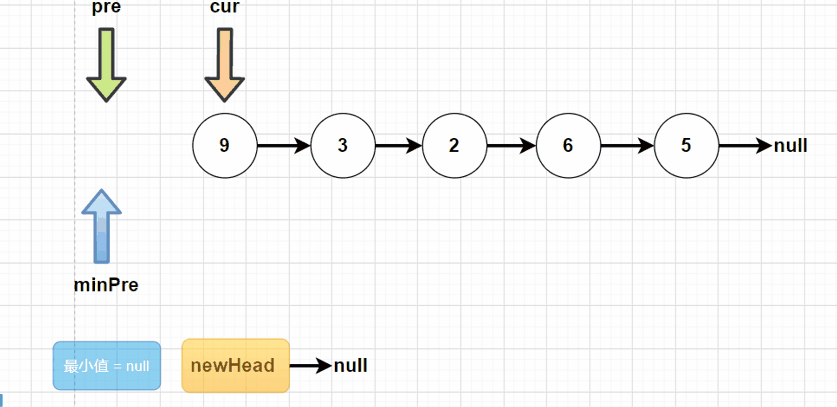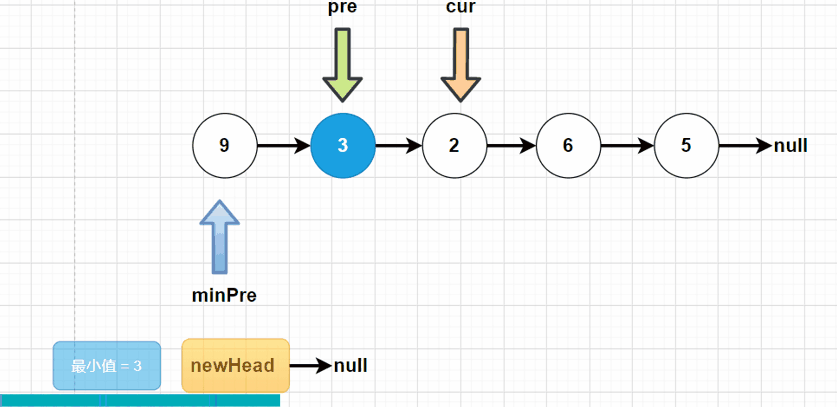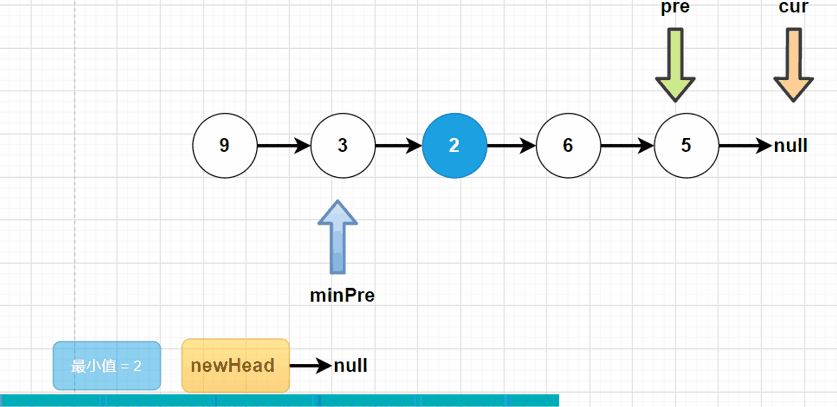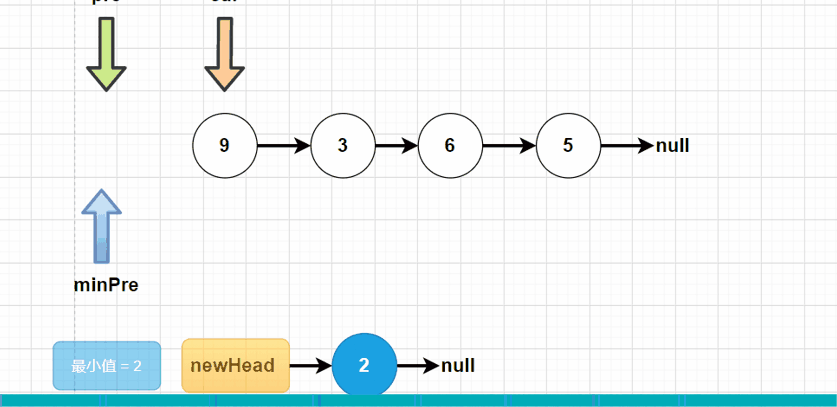
public ListNode sortList(ListNode head) {
if (head == null || head.next == null) {
return head;
}
ListNode newHead = null;
ListNode tail = null;
while (head != null) {
ListNode minNode = null; //最小结点
ListNode minPre = null; //最小结点的前驱结点
ListNode pre = null;
ListNode cur = head;
while (cur != null) {
if (minNode == null || cur.val < minNode.val) {
minPre = pre; //保存最小结点的前驱结点
minNode = cur; //保存最小结点
}
pre = cur;
cur = cur.next;
}
if (minNode == head) {
head = head.next; //换头结点的情况
} else {
minPre.next = minNode.next; //将最小结点拿出
}
if (newHead == null) {
newHead = minNode;
tail = minNode;
} else {
tail.next = minNode;
tail = minNode; //尾插法
}
}
tail.next = null;
return newHead;
}
八、单链表中每K个节点之间进行反转
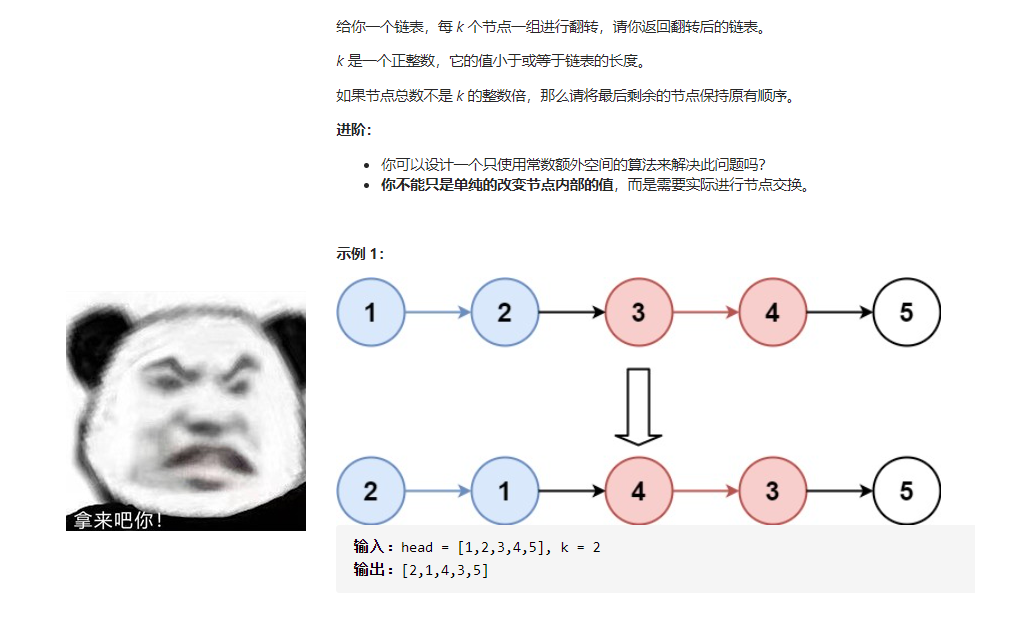
题意:根据给的K,K个一组进行反转。也就是前面几道题的进阶版。
分析:我们可以定义引用变量start,表示需要反转链表部分的开始,引用变量end表示反转链表的尾结点。还有left和right,分别表示start的前驱结点和end的后驱结点。如图:
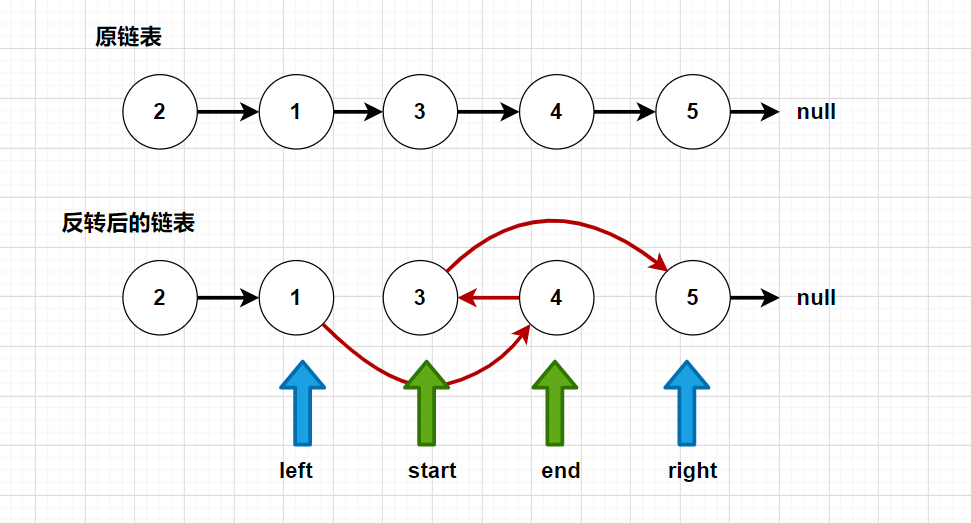
所以,我们只需要封装一个reverse函数,传递这四个引用变量,就能实现反转。
public ListNode reverseKGroup(ListNode head, int k) {
if (head == null || head.next == null || k < 2) {
//k=1时,等于没有反转
return head;
}
ListNode left = null;
ListNode start = head;
ListNode cur = head;
int count = 1;
while (cur != null) {
ListNode next = cur.next;
if (count++ == k) {
//反转
reverse(left, start, cur, cur.next); //这里的end和right,就是cur和cur.next
if (start == head) {
//更换头结点
head = cur;
}
left = start; //更新left和start的指向
start = start.next; //上图的right
count = 1;
}
cur = next;
}
return head;
}
public void reverse(ListNode left, ListNode start, ListNode end, ListNode right) {
ListNode pre = right;
ListNode next = null;
while (start != right) {
next = start.next;
start.next = pre;
pre = start;
start = next;
}
if (left != null) {
left.next = pre; //也就是上图的1号结点 连接4号结点
}
}
九、复制一个带随机指针的单链表

题意:给定一个链表,链表本身除了一个next域指向下一结点以外,还有一个random域,它可以指向这个链表中的任意一个结点。问:怎么复制出一个一模一样的链表出来。(深拷贝与浅拷贝,前期文章有讲解)
方法一: 运用哈希表,复制一个一模一样的结点出来,然后再连接起来即可。
//哈希表实现
public Node copyRandomList(Node head) {
HashMap<Node, Node> map = new HashMap<>();
Node cur = head;
while (cur != null) {
map.put(cur, new Node(cur.val)); //复制结点
cur = cur.next;
}
Node res = map.get(head);
while (head != null) {
map.get(head).next = map.get(head.next); //复制next域
map.get(head).random = map.get(head.random); //复制random域
head = head.next;
}
return res;
}
方法二: 遍历一遍链表,将每一个结点都复制一个出来,复制出来的结点连接在原来结点的后面。然后可以得到如下图所示:
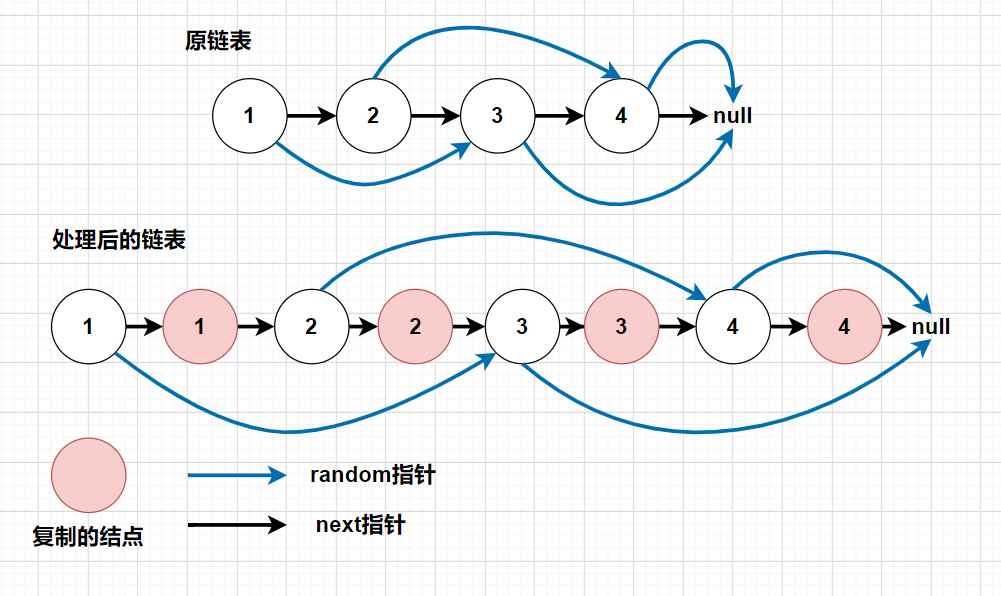
当我们将结点复制出来,并且连接在原结点之后,我们就会清晰地看见:
假设1号结点的random -> 3号结点,那么复制的结点1号结点random = 3号结点的后驱结点。
所以这道题,整体三步:
- 复制结点,连接到原结点的后面
- 处理每个结点的random指针。
(1'号结点.random = 1号结点.random.next) - 然后分离两个链表即可
class Node {
public int val;
public Node next;
public Node random;
public Node(int val) {
this.val = val;
}
}
public Node copyRandomList(Node head) {
if (head == null) {
return head;
}
//第一步-复制结点
Node cur = head;
while (cur != null) {
Node next = cur.next;
Node node = new Node(cur.val);
node.next = next; //连接下一结点
cur.next = node; //新结点挂在旧结点的后面
cur = next;
}
//第二步 - random指针
cur = head;
Node res = cur.next; //复制链表的头结点
Node copy = null;
while (cur != null) {
Node next = cur.next.next; //下一个旧结点
copy = cur.next;
copy.random = cur.random == null? null : cur.random.next; //连接random指针,需要注意null
cur = next;
}
//第三步-分离
cur = head;
copy = res; //指向复制链表的第一个结点
while (cur != null) {
Node next = cur.next.next; //下一个旧结点
copy.next = next == null? null : next.next; //注意,这里需要判断是否为null
cur.next = next; //将原来的链表还原
copy = copy.next;
cur = next;
}
return res;
}
十、合并两个有序的链表

题意:给定了两个已经有序的单链表,将它们合并在一起,且还是有序的!
分析:我们只需声明一个引用newHead,然后两个变量依次取出结点进行比较,谁小,谁就先挂在newHead上。循环终止条件是其中有一个链表遍历完了,循环就结束!
- 声明newHead,循环遍历两个链表
- 取出的结点谁更小,谁就先挂newHead上
- 循环结束的原因是,肯定有一个链表遍历完了。还剩一个链表直接连上newHead即可

public ListNode mergeList(ListNode headA, ListNode headB) {
if (headA == null || headB == null) {
return headA == null? headB : headA; //其中一个是null,返回另一个链表
}
ListNode newHead = null;
ListNode tail = null; //尾指针,用尾插法
while (headA != null && headb != null) {
//两个链表都不是null,循环就继续
if (headA.val < headB.val) {
if (newHead == null) {
newHead = headA;
} else {
tail.next = headA;
}
tail = headA;
headA = headA.next; //继续往下走
} else {
if (newHead == null) {
newHead = headB;
} else {
tail.next = headB;
}
tail = headB;
headB = headB.next; //继续往下走
}
}
//循环结束后,一定是有一个链表遍历完了,此时将另一个链表连接上即可
tail.next = headA != null? headA : headB;
return newHead;
}
十一、一种怪异节点的删除方式
题意:只给你单链表中的一个结点(非头结点),问:如何将给你的结点删除?例如: 原链表: 1 -> 2 -> 3 -> 4-> null ,假设给你3号结点,在没有头结点的情况下,如何删除3号结点?
可能有人会说:将给你的结点,赋值为null不就行了吗?
答案:肯定是不行的。给你的node结点,只是一个引用(地址),而在java中,变量是在栈上开辟的,直接赋值为null,只是让这个变量找不到node结点了而已。具体的,画一画栈区和堆区的内存图,你或许就明白了。
分析:这道题,有一定的局限性。如果结点的数据只是普通的数据,我们可以直接将下一个结点的数据覆盖到node结点上,然后node去连接下一个结点的下一个结点。切记:如果给你的node,是尾结点的话,这道题就没有解。如图:

public void delStrangerNode(ListNode node) {
if (node == null || node.next == null) {
return;
}
node.val = node.next.val;
node.next = node.next.next;
}
注:要跟面试过说清楚情况,这样的方式,其实并不是删除了结点,只是进行了数据的覆盖。假设这一个结点时一个很大的工程,又或者是一个服务器,如果去进行数据的覆盖,工程量还是很大的。
十二、按照左右半区的方式重新组合链表
题意:先将单链表从中间分开,分为两个链表。然后这两个链表交叉着插入结点,得到新的链表。
整体分为两步:
- 使用快慢指针,得到整个链表的中间结点。分为两个链表
- 交叉着穿插结点,得到新的链表
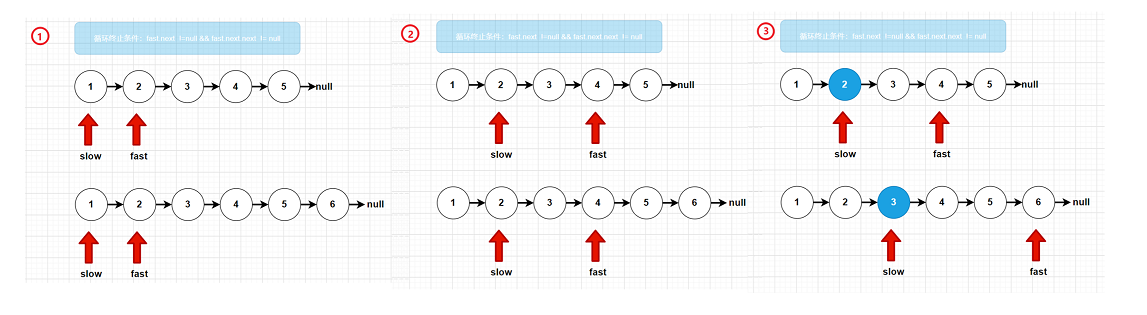
由上图,我们可以发现当fast和slow停下来的时候,slow的下一结点就是当前链表的中间结点。此时我们就可以分为两个链表了。

public ListNode againCombinationList(ListNode head) {
if (head == null || head.next == null) {
return head;
}
ListNode slow = head;
ListNode fast = head.next;
while (fast.next != null && fast.next.next != null) {
fast = fast.next.next;
slow = slow.next;
}
//当循环停下的时候,slow的下一结点就是整个链表的中间结点
ListNode right = slow.next; //右半部分的链表
slow.next = null; //置为null
ListNode left = head; //左半部分的链表
while (left.next != null) {
ListNode next = right.next;
right.next = left.next;
left.next = right;
left = right.next;
right = next;
}
left.next = right;
return head;
}
十三、在单链表中删除重复的节点

分析:首先看到删除重复结点,我就想到了HashSet集合,做容器,遍历一遍链表,将所有数据添加到集合中,最后再连接起来。但是这样的话,空间复杂度就高了,这样的思路只是适合在笔试的时候用,在面试的时候,入不了面试官的眼的。
所以我们只能想办法在链表上直接动手了,一开始,我们以链表的第一个结点作为目标,在这个结点的后面的结点做遍历,如果剩下的结点中没有与目标结点相等的,我们的目标结点就转换到下一个结点,继续做这样的遍历。时间复杂度O(N2)。
public ListNode removeDuplicateNodes(ListNode head) {
if (head == null || head.next == null) {
return head;
}
ListNode cur = head;
ListNode pre = null;
ListNode next = null;
while (cur != null) {
next = cur.next; //首先保存cur的下一结点,在这个结点上去做比较
pre = cur;
while (next != null) {
//从next往下走,每一个结点都与cur比较
if (cur.val == next.val) {
pre.next = next.next; //相等的情况,pre直接连接下一个结点
} else {
pre = next;
}
next = next.next;
}
cur = cur.next;
}
return head;
}
十四、判断单链表是否有环,若有,返回第一个入环节点
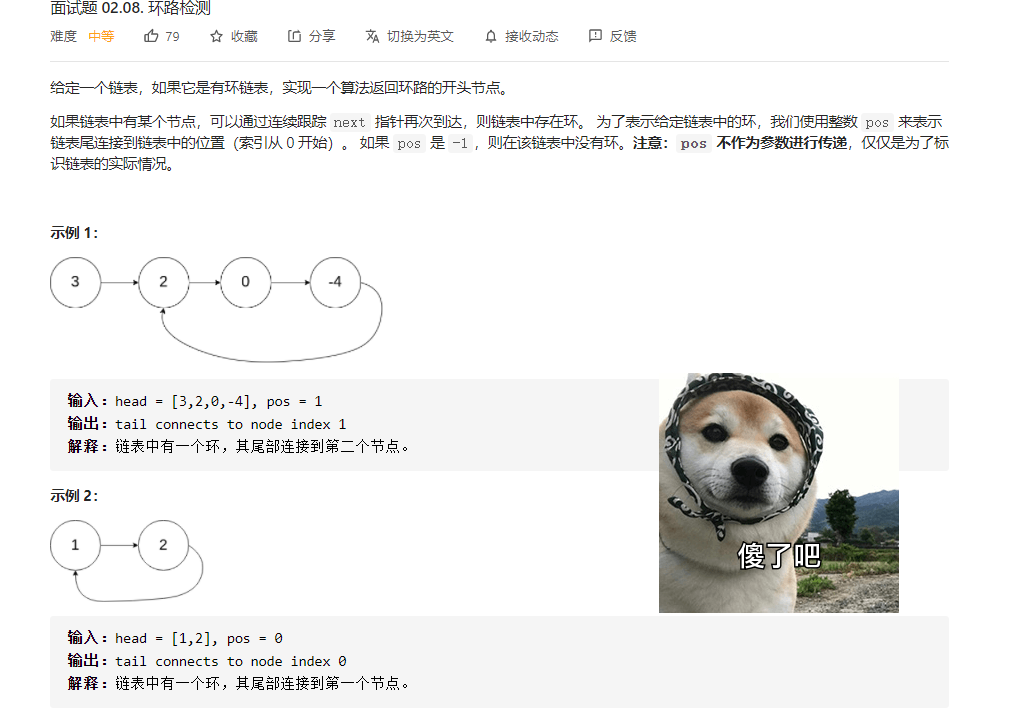
分析:有一道链表题是判断给定链表是否有环,这道题就是在有环的基础之上,需要返回第一个入环的结点。如果就是入环的第一个结点;
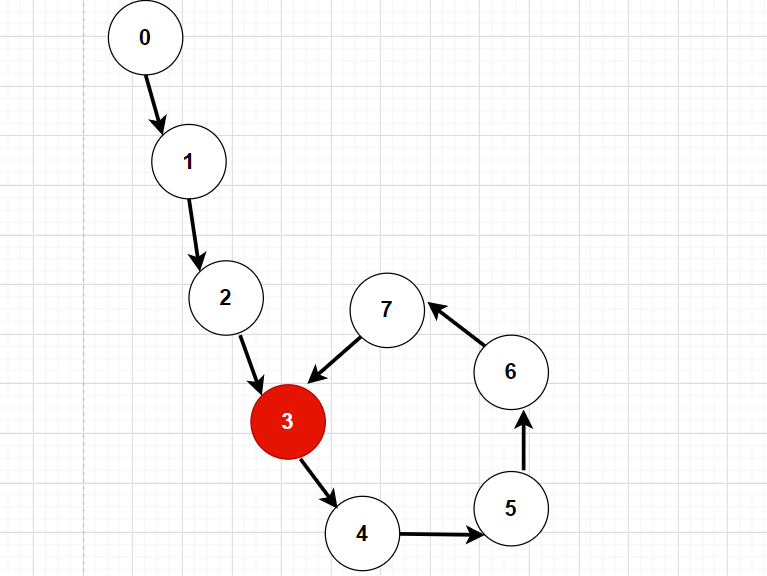
此时的3号结点,我们就称为入环的第一个结点。
如何找到这个入环结点并返回?
还是要引入小学的数学问题,追赶问题。引入slow和fast指针,slow每次走一步,fast每次走两步。如果给定的链表是有环的,slow和fast肯定能在环上相遇(fast的速度是slow的两倍)。此时我们让fast从head重新出发,这次slow和fast每次只有一步,这样slow和fast肯定能在入环结点处相遇。至于如何证明这个问题,我就不多说了。动图如下:
public ListNode detectCycle(ListNode head) {
if (head == null || head.next == null) {
return null;
}
ListNode slow = head;
ListNode fast = head; //都从第一个结点出发
while (fast != null && fast.next != null) {
//如果不是循环链表,就退出
slow = slow.next;
fast = fast.next.next;
if (slow == fast) {
//相等了
fast = head; //从头开始
while (slow != fast) {
slow = slow.next;
fast = fast.next;
}
return slow;
}
}
return null;
}
十五、终极大招之两个单链表相交的一系列问题
题目:在本题中,单链表可能有环,也可能无环。给定两个单链表的头结点head1和head2,这两个链表可能相交,也可能不相交。
请实现一个函数,如果两个链表相交,请返回相交的第一个结点;如果不相交,返回null即可。
要求:如果链表1的长度为N,链表2的长度为M,时间复杂度请达到O(N+M),额外空间复杂度请达到O(1)。
出自《程序员代码面试指南》一书。
注:如果其中一个链表有环,另一个链表无环,那么这两个链表肯定不相交。
这道题我就留个大家自己研究啦,因为暂时还没找到OJ题,所以就不讲啦。我会将源码放到GitHub上。
好啦,各位朋友!本期更新就到此结束啦!链表题说难也不是很难,说简单也算不上。这毕竟是面试官必问的相关题,好好研究研究,赶快上手写代码吧!
下期见啦!!!拜拜