你好我是辰兮,很高兴你能来阅读,本篇是整理了索引基础学习的相关知识点,带你认识了解索引的数据结构,实现原理,分享获取新知,希望对你有帮助,一起加油,共同进步。
1.JAVA基础面试常考问题: JAVA面试基础常考题汇集2.JAVA面试SSM框架常考:JAVA框架面试题汇集
一、索引定义
MySQL官方定义:索引(Index)是帮助MySQL高效获取数据的数据结构。
作用: 可以提高查询效率。
关键词:数据结构 用来提高查询效率
二、索引分类
索引是在存储引擎中实现的,也就是说不同的存储引擎,会使用不同的索引。MyISAM和InnoDB存储引擎:只支持BTREE索引,也就是说默认使用BTREE,不能够更换。MEMORY/HEAP存储引擎:支持HASH和BTREE索引。
mysql的索引我们分为三大类来讲单列索引(普通索引,唯一索引,主键索引)、组合索引、全文索引。
| 索引名称 | 作用 |
|---|---|
| 主键索引 | 主键是一种唯一性索引,但它必须指定为PRIMARY KEY,每个表只能有一个主键 |
| 唯一索引 | 索引列的所有值都只能出现一次,即必须唯一,值可以为空 |
| 普通索引 | 基本的索引类型,值可以为空,没有唯一性的限制 |
| 全文索引 | 全文索引的索引类型为FULLTEXT |
- 全文索引可以在varchar、char、text类型的列上创建。可以通过ALTER TABLE或CREATE INDEX命令创建。
- 对于大规模的数据集,通过ALTER TABLE(或者CREATE INDEX)命令创建全文索引要比把记录插入带有全文索引的空表更快。
- 全文索引不支持中文需要借sphinx(coreseek)或迅搜<、code>技术处理中文。
- alter table 表名 add FULLTEXT(字段名);
三、索引原理
(1)为什么我们添加完索引后查询速度会变快?
- ①传统的查询方法,是按照表的顺序遍历的,不论查询几条数据,mysql需要将表的数据从头到尾遍历一遍
- ②在我们添加完索引之后,mysql一般通过BTREE算法生成一个索引文件,在查询数据库时,找到索引文件进行遍历(折半查找大幅查询效率),找到相应的键从而获取数据
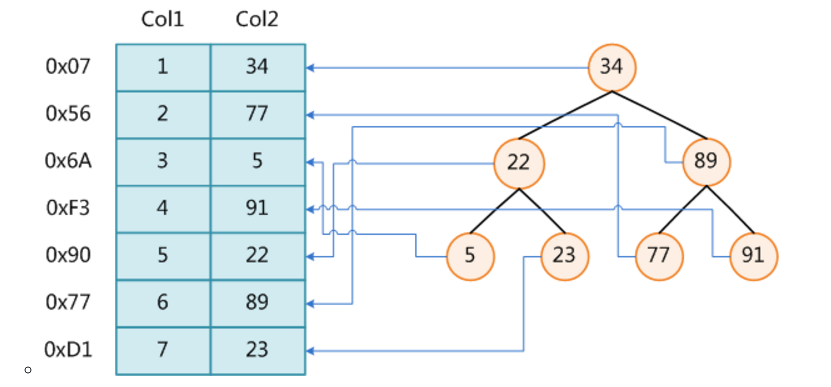
(2)索引的代价
- ①创建索引是会产生索引文件的,占用磁盘空间
- ②索引文件是一个二叉树类型的文件,可想而知我们的dml(增删改)操作同样也会对索引文件进行修改,所以性能会下降
(3)在哪些column上使用索引?
- ①较频繁的作为查询条件的字段应该创建索引
- ②唯一性太差的字段不适合创建索引(例如gender性别字段,尽管频繁作为查询条件)
- ③更新非常频繁的字段不适合作为索引
- ④不会出现在where子句中的字段不该创建索引
四、索引数据结构
实际的数据库系统几乎没有使用二叉查找树或其进化品种红黑树(red-black tree)实现的,目前大部分数据库系统及文件系统都采用B-Tree或其变种B+Tree作为索引结构。
(1)B-Tree
B树(Balance)是一种自平衡的树,能够保持数据有序。这种数据结构能够让查找数据、顺序访问、插入数据及删除的动作,都在对数时间内完成。
概括来说B树是一个一般化的二叉查找树(binary search tree),可以拥有多于2个子节点。B树为系统大块数据的读写操作做了优化。B树减少定位记录时所经历的中间过程,从而加快存取速度。
下面是一个B-Tree的数据结构:
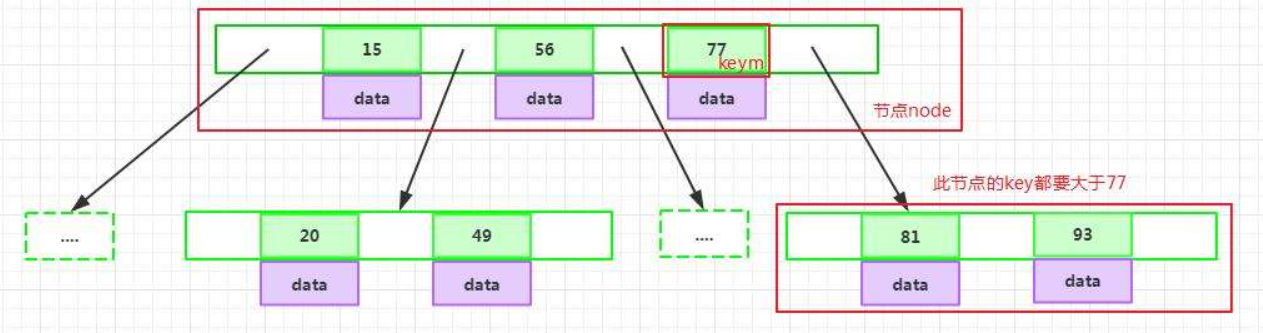
B-Tree是满足下列条件的数据结构:
- B-Tree的每个节点都是【指针+“键值对”】组成,key和指针互相间隔,节点两端是指针
- 每个非叶子节点由n-1个key和n个指针组成,每个叶子节点最少包含一个key和两个指针
- 每个指针要么为null,要么指向另外一个节点,叶子节点的指针均为null 一个节点中的key从左到右递减排列
- 指针指向的节点的所有key大于指针左边的key,小于指针右边的key 所有的叶子节点具有相同的深度,等于树高h(树高,就是树的层数)
在B-Tree中按key检索数据的算法:首先从根节点进行二分查找,如果找到则返回对应节点的data,否则对相应区间的指针指向的节点递归进行查找,直到找到节点或找到null指针,返回null则表示查找失败。
- 一个度为d的B-Tree,设其索引N个key,则其树高h的上限为logd((N+1)/2),检索一个key,其查找节点个数的渐进复杂度为O(logdN)。从这点可以看出,B-Tree是一个非常有效率的索引数据结构。
- 【度,用来约束一个节点key和指针的个数,每个非叶子结点由n-1个key和n个指针组成,其中d<=n<=2d,由于key的个数至少为1,所以d>=2】
(2)B+Tree
B+Tree是B树最常见的的一种变种(B-Tree有许多变种),MySQL就普遍使用B+Tree实现其索引结构。

与B-Tree相比,B+Tree有以下不同点:
- B+树的每个非叶子节点都是由
【key+指针】,B树是【键值对+指针】 B+树的每个叶子节点只包含键值对,B树的叶子节点【键值对+指针】B+树的每个非叶子节点的指针的数量等于key的数量,B树(指针数量=键值对数量+1)B+树的叶子节点包含所有的key
一般在数据库系统或文件系统中使用的B+Tree结构都在经典B+Tree的基础上进行了优化,增加了顺序访问指针。
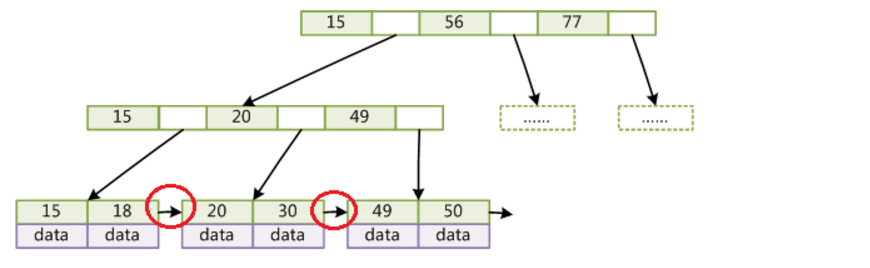
在B+Tree的每个叶子节点增加一个指向相邻叶子节点的指针,就形成了带有顺序访问指针的B+Tree。做这个优化的目的是为了提高区间访问的性能,例如图4中如果要查询key为从18到49的所有数据记录,当找到18后,只需顺着节点和指针顺序遍历就可以一次性访问到所有数据节点,极大提到了区间查询效率。
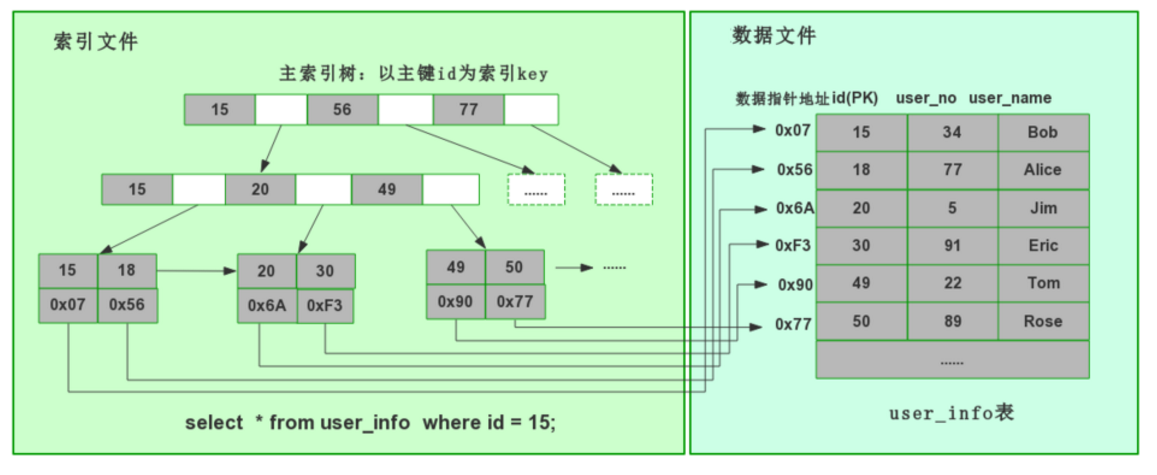
MySQL B+Tree索引解析图
The best investment is to invest in yourself

2020.06.12 记录辰兮的第80篇博客