目前,Apache Kafka 使用 Apache ZooKeeper 来存储它的元数据,比如分区的位置和主题的配置等数据就是存储在 ZooKeeper 集群中。在 2019 年社区提出了一个计划[1],以打破这种依赖关系,并将元数据管理引入 Kafka 本身。
所以 Apache Kafka 为什么要移除 Zookeeper 的依赖?Zookeeper 有什么问题?实际上,问题不在于 ZooKeeper 本身,而在于外部元数据管理的概念。
拥有两个系统会导致大量的重复。毕竟,Kafka 是一个分布式的发布-订阅消息系统,而 ZooKeeper 其实也是一个分布式日志系统,其上有一个文件系统 API。每种方法都有自己的网络通信、安全、监视和配置方法。如果同时使用这两个系统,则系统的总体复杂性大约会增加一倍,这导致了不必要的学习曲线,并增加了错误配置导致安全漏洞的风险。
同时,在外部存储元数据并不是很好的。我们至少需要运行三个额外的 Java 进程,有时甚至更多。事实上,我们经常看到具有与 Kafka 节点一样多的 ZooKeeper 节点的 Kafka 集群!此外,ZooKeeper 中的数据还需要缓存在 Kafka 控制器上,这导致了双重缓存。
更糟糕的是,在外部存储元数据限制了 Kafka 的可伸缩性。当 Kafka 集群启动时,或者一个新的控制器被选中时,控制器必须从 ZooKeeper 加载集群的完整状态。随着元数据数量的增加,加载过程需要的时间也会增加,这限制了 Kafka 可以存储的分区数量。
最后,将元数据存储在外部会增加控制器的内存状态与外部状态不同步的可能性。控制器的活动视图(位于群集中)也可以从 ZooKeeper 的视图中分离出来。
KIP-500
处理元数据(Handling metadata)
KIP-500 概述了在 Kafka 中处理元数据的更好方法。我们可以将其称为“ Kafka on Kafka”,因为它涉及将 Kafka 的元数据存储在 Kafka 本身中,而不是存储在 ZooKeeper 之类的外部系统中。
在实现了 KIP-500 的系统,元数据将存储在 Kafka 内的分区中,而不是存储在 ZooKeeper。控制器将成为该分区的 leader;除了 Kafka 本身,不需要配置和管理外部元数据系统。
我们将元数据视为日志。Brokers 如果需要最新的数据只能读取日志的末尾。这类似于需要最新日志条目的使用者仅需要读取日志的最后而不是整个日志的方式。Brokers 还可以在进程重新启动时持久化它们的元数据缓存。
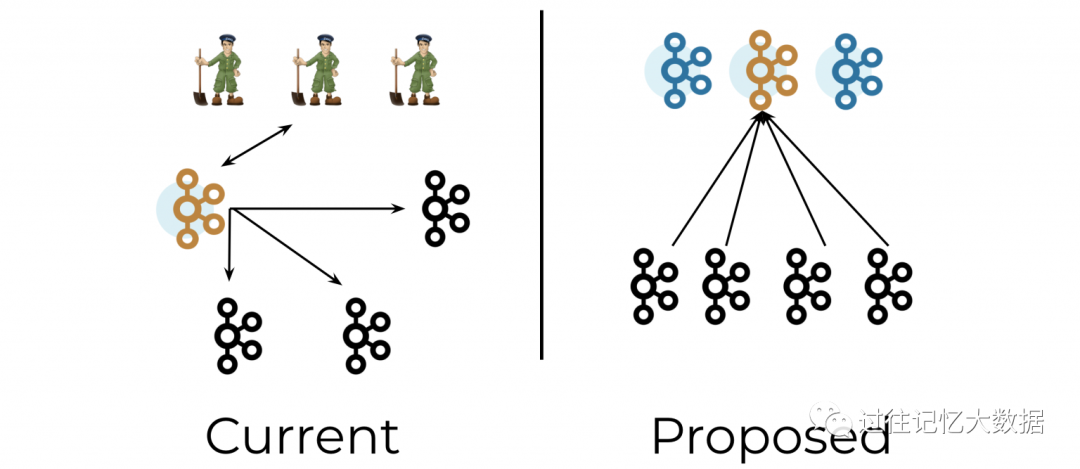
控制器体系结构
Kafka 集群选择一个控制器节点来管理分区 leaders 和集群的元数据。我们拥有的分区和元数据越多,控制器的可伸缩性就越重要。我们希望最小化与主题或分区数量成线性比例的时间的操作数量。
其中一个操作是控制器故障转移。当前,当 Kafka 选择新控制器时,它需要在继续之前加载整个集群的状态。随着集群元数据数量的增长,这个过程会花费越来越长的时间。
相比之下,在实现了 KIP-500 的系统,将会有几个备用控制器,随时准备在活动控制器挂掉时接管。这些备用控制器只是元数据分区的 Raft quorum 中的其他节点。这种设计确保了当选择一个新的控制器时,我们永远不需要经过漫长的加载过程。
KIP-500 将加快主题的创建和删除。当前,创建或删除主题时,控制器必须从 ZooKeeper 重新加载集群中所有主题名称的完整列表。这是必要的,因为当 ZooKeeper 通知我们集群中的主题集发生更改时,它不会确切地告诉我们添加或删除了哪些主题。相反,在完全实现了 KIP-500 之后,创建或删除主题只需要在元数据分区中创建一个新条目,这是 O(1)操作。
元数据可伸缩性是将来扩展 Kafka 的关键部分。我们期望单个 Kafka 集群最终将能够支持一百万个分区或更多。
Roadmap
从 Kafka 的管理工具中删除 ZooKeeper
Kafka 发行版中附带的一些管理工具仍然允许与 ZooKeeper 直接通信。更糟糕的是,仍然有一两个操作必须经过 ZooKeeper 的这种直接通信才能完成。
我们一直在努力缩小这些差距。不久之后,对于以前需要直接 ZooKeeper 访问的每个操作,将都有一个公共的 Kafka API。我们还将在 Kafka 的下一个主要版本中禁用或删除不必要的 ——zookeeper 标志。
自我管理的元数据仲裁
在实现 KIP-500 之后,Kafka 控制器会将其元数据存储在 Kafka 分区中,而不是存储在 ZooKeeper 中。但是,由于控制器依赖于该分区,因此分区本身不能依赖控制器来进行领导者选举之类的事情。所以管理此分区的节点必须实现自我管理的 Raft 仲裁。
KIP-595: A Raft Protocol for the Metadata Quorum[2] 概述了社区如何将 Raft 协议引入到 Kafka 中,以使能够在 Kafka 中更好的工作。这将涉及将 Raft 论文[3] 中描述的基于推的模型更改为基于拉的模型,这与传统的 Kafka 复制是一致的。其他节点将连接到这些节点,而不是将数据推送到其他节点。同样,我们将使用与 Kafka 一致的术语,使用 epochs 而不是原始 Raft 论文中的 terms 等等。
最初的实现将集中在支持元数据分区上。它不支持将常规分区转换为 Raft 所需的全部操作。但是,这是我们将来可能会谈到的话题。
KIP-500 mode
当然,该项目最令人兴奋的部分是在 “ KIP-500模式” 下无需 ZooKeeper 即可运行的能力。当 Kafka 在此模式下运行时,我们将使用 Raft 仲裁存储元数据,而不是ZooKeeper。
最初,KIP-500 模式将是实验性的。大多数用户将继续使用“传统模式”,即仍然使用 ZooKeeper。部分原因是因为 KIP-500 模式最初并不支持所有可能的功能。另一个原因是因为我们希望在将其设置为默认值之前,KIP-500 模式必须解决之前所有问题。最后,我们需要时间完善从传统模式到 KIP-500 模式的升级过程。
启用 KIP-500 模式的大部分工作将在控制器中进行。我们必须将控制器中与 ZooKeeper 交互的部分与实现更多通用逻辑(如复制集管理)的部分分离开来。
我们需要定义和实现更多的控制器API,以替换当前涉及 ZooKeeper 的通信机制。新的 AlterIsr API 就是一个例子。该 API 允许副本在不使用 ZooKeeper 的情况下将同步副本集中的更改通知控制器。
更新
KIP-500 引入了桥接发行版(bridge release)的概念,使用了这个功能使得 KIP-500 过渡期变得更好。Bridge 发行版非常重要,因为它们可以让用户升级时零停机。使用 Kafka 老版本的用户只需升级到 bridge 发行版即可。然后,再可以执行第二次升级到完全实现 KIP-500 的版本。正如它的名字所暗示的,桥接发行充当了通往新世界的桥梁。
总结
Kafka 是最活跃的 Apache 项目之一。在过去的几年里,它的架构发生了惊人的变化。正如 KIP-500 这样的 ISSUE 所显示的那样,这种进化还没有完成。我最喜欢KIP-500的地方在于,它简化了整个体系结构,无论对于管理员还是开发人员而言。它将允许我们使用事件日志的强大抽象来处理元数据,它最终会证明:Kafka 不需要管理员!