文章目录
1、命名空间
在C/C++中,变量、函数和后面要学到的类都是大量存在的,这些变量、函数和类的名称将都存在于全局作用域中,可能会导致很多冲突。使用命名空间的目的是对标识符的名称进行本地化,以避免命名冲突或名字污染,namespace关键字的出现就是针对这种问题的。
1.1命名空间的定义
定义命名空间,需要使用到namespace关键字,后面跟命名空间的名字,然后接一对{}即可,{}中即为命名空间的成员。
//1. 普通的命名空间
namespace N1 // N1为命名空间的名称
{
// 命名空间中的内容,既可以定义变量,也可以定义函数
int a;
int Add(int left, int right)
{
return left + right;
}
}
//2. 命名空间可以嵌套
namespace N2
{
int a;
int b;
int Add(int left, int right)
{
return left + right;
}
namespace N3
{
int c;
int d;
int Sub(int left, int right)
{
return left - right;
}
}
}
//3. 同一个工程中允许存在多个相同名称的命名空间,编译器最后会合成同一个命名空间中。
namespace N1
{
int Mul(int left, int right)
{
return left * right;
}
}
1.2命名空间的使用
//1.直接指定
int main()
{
printf("%d\n", N::a);
return 0;
}
//2.将b单独展开到全局域中
using N::b;
int main()
{
printf("%d\n", N::a);
printf("%d\n", b);
return 0;
}
//3.全部展开
using namespce N;
int main()
{
printf("%d\n", N::a);
printf("%d\n", b);
Add(10, 20);
return 0;
}
推荐在项目中不要全部展开,最好使用1或2。
2、 C++输入输出
- 使用cout标准输出(控制台)和cin标准输入(键盘)时,必须包含< iostream >头文件以及std标准命名空
间。
注意:早期标准库将所有功能在全局域中实现,声明在.h后缀的头文件中,使用时只需包含对应头文件即可,后来将其实现在std命名空间下,为了和C头文件区分,也为了正确使用命名空间,规定C++头文件不带.h;旧编译器(vc 6.0)中还支持<iostream.h>格式,后续编译器已不支持,因此推荐使用+std的方式。 - 使用C++输入输出更方便,不需增加数据格式控制,比如:整形–%d,字符–%c
#include<iostream>
using namespace std;
int main()
{
//1.相比printf/scanf,自动识别类型,控制输出格式
//2.一行连续输出
//3.(endl换行符等价于'\n')
cout<< "hello world\n";
int i = 1;
char ch = 48;
double d = 2.222;
cout << i<<endl;
cout << d << endl;
cout << ch << endl;
cout << &i << endl;
cin >> i;
cin >> ch >> d;
cout << i << "--" << ch << "--" << d << endl;
return 0;
}
struct Student
{
char name[10];
int age;
};
int main()
{
//实际使用角度,cin/cout和printf/scanf各有优势
//C++方便
int i;
double d;
//cin >> i >>d;
//cout<<i<<d<<endl;
//c方便
struct Student s = {
"peter", 18 };
printf("name:%s age:%d\n", s.name, s.age);
cout << "name:" << s.name << " "<< "age:" << s.age << endl;
return 0;
}
3. 缺省参数
缺省参数是声明或定义函数时为函数的参数指定一个默认值。在调用该函数时,如果没有指定实参则采用该默认值,否则使用指定的实参。
void TestFunc(int a = 0)
{
cout << a << endl;
}
int main()
{
TestFunc();//没有传参时,使用参数默认值
TestFunc(10);//传参时使用指定的参数
}
3.1全缺省
void TestFunc(int a = 10, int b = 20, int c = 30)
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl;
}
int main()
{
TestFunc();
TestFunc(1);
TestFunc(1,2);
TestFunc(1,2,3);
}
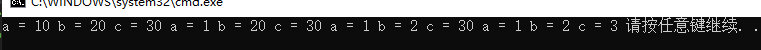
3.2 半缺省
//半缺省 (从左往右缺省)
void TestFunc(int a , int b , int c = 30)
{
cout << "a = " << a << " ";
cout << "b = " << b << " ";
cout << "c = " << c << " ";
}
int main()
{
TestFunc(1, 2);
TestFunc(1, 2, 3);
}
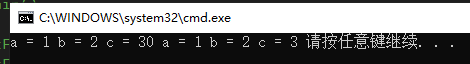
4、函数重载
4.1 面试题:
1.什么是函数重载?
函数重载:是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这些同名函数的形参列表(参数个数 或 类型 或 顺序)必须不同,常用来处理实现功能类似数据类型不同的问题
2.为什么c语言不支持重载,C++支持重载?
预处理 头文件展开/宏替换/条件编译/去掉注释。
编译 所要作得工作就是通过词法分析和语法分析,在确认所有的指令都符合语法规则之后,将其翻译成等价的中间代码表示或汇编代码。
汇编 把汇编代码转成二进制的机器码
链接 符号表的合并和符号表的重定位
把前期没有拿到地址的函数在其他目标文件的符号表中找到。如何找?使用函数名!因为C++重载函数,只要参数不同,修饰出来的名字就是不同的,那么就不会冲突,链接时就可以找到,因为C++是使用修饰后的名字去找。
如果是c语言,不支持同名函数,C++为了解决这个问题,支持同名函数,但是有要求,参数不同(个数不同or类型不同or顺序不同)
int Add(int left, int right)
{
return left + right;
}
double Add(double left, double right)//类型不同
{
return left + right;
}
long Add(long left, long right)
{
return left + right;
}
int main()
{
Add(10,20);
Add(10.0,20.0);
Add(10L, 20L);
return 0;
}
5.引用
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。
5.1 引用特性
int main()
{
int a = 10;
int &b = a;//b是a的别名,通过ab都可以修改a的值
a = 20;
b = 30;
int &c = a;//1.可以有多个别名
int &d = b;
//int&e; 错误,2.必须在定义时初始化
return 0;
}
3.引用一旦引用一个实体,再不能引用其他实体。
5.2 常引用
void func (const Type& x) --> func(a)
C++中以后会经常引用去做参数
1、引用做参数不需要拷贝。
2、如果func中不改变x,尽量加const
a、实参可以是变量,也可以是常量。
b、如果x和a之间存在隐式转换等,也可以传递。
int main()
{
//指针和引用在初始化赋值时,权限可以缩小不可以放大
const int a = 10;
// int &b = a;//编译时会出错
const int &b = a;
int c = 0;
const int& d = c;
const int& r = 10;//可以引用常量
//整形和浮点数之间互相隐式类型转换
double dd = 2.22;//
int i = dd;
//int& ri = dd;//不可以
const int& ri = dd;//可以
return 0;
}
5.3 引用的作用
1.引用做参数
void Swap(int* px, int* py)//传地址
{
int tmp = *px;
*px = *py;
*py = tmp;
}
void Swap(int& x, int& y)//引用
//思考:这里是否涉及到引用在定义时未初始化的问题?
//不涉及!形参只有在实参传给它的时候才会开辟空间。传参的过程就是定义
{
int tmp = x;
x = y;
y = tmp;
}
int main()
{
int a = 0, b = 1;
Swap(&a, &b);
Swap(a, b);
}
2.引用做返回值
//常用的传值返回
int count()
{
static int n = 0;
n++;
//...
return n;
}
//传值返回:这里将n拷贝给了临时变量,临时变量再拷贝给ret。
//相当于进行了两次拷贝。
int main()
{
int ret = count();
printf("%d\n", ret);
return 0;
}
//传引用返回
int& count()
{
static int n = 0;//static作用:延长n的生命周期,使n出了作用域还能存在
n++;
//...
return n;//[int&] = n;
}
//传引用返回:临时变量[int&]是n的引用,就没有拷贝。然后再把临时变量拷贝给ret。相当于只进行一次拷贝
int main()
{
int ret = count();
printf("%d\n", ret);
return 0;
}
5.4 引用和指针的不同点:
- 引用在定义时必须初始化,指针没有要求
- 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型
实体 - 没有NULL引用,但有NULL指针
- 在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32位平台下占
4个字节) - 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小
- 有多级指针,但是没有多级引用
- 访问实体方式不同,指针需要显式解引用,引用编译器自己处理
- 引用比指针使用起来相对更安全
6.内联函数
以inline修饰的函数叫做内联函数,编译时C++编译器会在调用内联函数的地方展开,没有函数压栈的开销,
内联函数提升程序运行的效率。
1.以空间换时间,代码很长(超过10行)、循环、递归函数不适合作为内联函数
2.inline不建议声明和定义分离,分离会导致链接错误,因为inline被展开,就没有函数地址了,链接就会找不到。
inline void Swap(int& a, int& b)
{
int tmp = a;
a = b;
b = tmp;
}
int main()
{
int x = 1, y = 2;
Swap(x, y);
return 0;
}
Swap函数就是一个频繁调用的函数,调用函数就要建立栈帧,建立栈帧是有空间和性能消耗的,如何解决?
C语言方式:宏函数。缺点:不方便调试、复杂容易出错。
C++方式:内联函数 intine函数,相对宏函数,inline函数完美解决问题。