1.http请求超时
收到线上告警短信:"消息中转服务"出现超时异常,请及时查看。业务负责人小张,看到短信后,心里犯着嘀咕:网路抖动了?消息处理服务负载增高?消息处理变慢了?中转服务请求超时时间设置的太短了?心里边想着,边打开电脑连接服务器进行查看。
小张一天的工作在一条短信提醒中开始了。
小张负责的业务是一个消息中转,上报的业务,具体架构如下图所示:
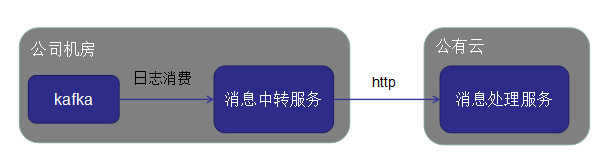
消息队列部署在公司内网中,消息处理服务部署在公有云上,为了方便消息的接收和处理,在消息队列和消息处理服务之间增加一个消息中转服务。消息中转服务的作用是从消息队列消费消息,然后在通过网络请求将消息发送消息处理服务中。
打开电脑后,小张逐一对自己的判断进行了验证:
1.查看了消息处理服务的负载情况,cpu和内存占用并不高。服务的gc也没有出现异常。消息处理服务负载高,导致消息变慢的问题可以排除。

2.查看了其他部署在该公有云上的服务,一切都正常,如果公司内网到公有云之间的网络有问题的话,那么其他服务也应该会有问题。网络抖动的问题基本可以排除。
3.查看中转服务 http请求相关的参数配置:
http.connectiontimeout = 2s
http.readtimeout = 2s看到这两个配置,小张盘算着:连接超时时间短一些倒没什么,一般来说,TCP三次握手建立连接需要的时间非常短,通常在毫秒级别最多也就1-2秒,除非网络出现了问题,如果3s都连不上,八成网络断了。那设置的再长一些意义也不大。但是这个读取数据的超时时间也太短了吧。消息处理服务处理耗时稍有波动,大概率会出现数读取超时。
为了进一步验证自己的想法,小张登录到了消息处理服务器上,查看了那段时间内,消息处理的耗时,的确,那段时间内消息处理耗时都在2s以上,有的还达到了3s,"看来是消息中转服务数据读取超时时间设置的太短导致的,不过消息处理服务处理消息,怎么这么耗时呢?”小张心里又泛起了嘀咕。
正准备继续刨根问底,一探究竟时,手机再次收到了,告警短信:"消息中转服务"出现超时异常,请及时查看”。
线上问题优先,既然问题定位到了,那就先把读取超时时间调大一些吧,但是设置多少呢,不清楚消息处理服务处理的耗时边长的原因,这个读出超时时间也不好设置啊,小张考虑了一下,先设置个比较大的超时时间,后面找到问题的原因后,再调整到合适的值吧。于是,小张对读取超时时间进行如下调整:
http.connectiontimeout = 2s
http.readtimeout = 10s果不其然,数据读取时间调长以后,的确超时问题没有了。此时自豪和成就感涌上小张心头。
2.消息积压了
暂时解决了,线上超时问题后,小张终于可以安心的排查消息处理耗时变长的问题了,于是,小张把消息处理服务中,消息处理耗时比较长的那段时间内的日志,下载了下来,准备一探究竟。
为了方便排查问题,消息处理服务记录的日志中,主要包含了以下内容:
(1)处理的消息内容:msg
(2)处理消息的方法签名:method
(3)消息处理耗时:processTime
(4)以及到达消息处理服务器的时间:receiveTime
msg:{actionTime:'2020-11-15 02:30:01',logId:'ef84d5es7h8ef598se',....} |
method:msgProcess |
processTime:1598ms |
receiveTime:2020-11-15 03:42:21
看到日志中,消息内容时,小张眼前一亮:
因为每条消息中都记录了,该条消息产生的时间 actionTime 。通常来说,消息产生的时间和到达消息处理服务的时间不会差太多。但是这个消息的产生时间却比消息处理时间早了一小时。难道消息积压了?
小张结合系统架构,对消息"延期"到达进行了分析:消息处理服务,就是一个简单http请求处理服务,即使消息处理服务中消息处理的逻辑比较复杂,那也仅仅会导致处理消息耗时比较长,可能是消息处理服务处理效率低,导致消息积压在上游,进而产生了"延期"到达的问题,消息应该堆在上游的服务中了。
3.服务器oom了
查看了消息队列的监控,kafka并没有堆积,消息中转服务在正常消费,消息速度15/s,和平常消费速度没有什么差异。那消息堆积在哪里了呢?
正当小张在沉思的时候,手机再次受到告警短信:"消息中转服务出现了oom的异常",看到这个异常,小张突然灵光一闪:难道消息积压在了消息中转服务的内存里了。
先不说消息为什么会堆积在内存了,既然堆积在了内存里面,那么服务一重启,内存中的消息不全都丢了吗,想起刚刚自己修改超时时间参数时候,已经重启过了一次服务,小张后背阵阵发凉,不过想到目前该套业务,还在线上试运行阶段,小张也不再那么惊慌,"不过等真正上线后,消息丢失问题还是要有一个应对方案",小张心里想。
事已至此,先重启服务再说吧。
4.找到了oom的元凶
重启完服务后,小张打开了消息中转服务jvm内存变化监控,内存占用的确在不断上升,看来消息真的堆积在了消息中转服务的内存里了。
既然消息堆积了,说明消息中转服务到消息处理服务之间存在性能瓶颈,要么中转服务发送请求效率低,要么消息处理服务处理的慢。
虽说消息处理服务,目前消息处理的耗时比较长,但是消息处理服务器的整体系统负载并不高,对于这种io密集型的任务处理,可以增加客户端并发度,来提升系统整体效率,小张心里盘算着。
此时小张 开始翻看消息中转服务的代码,寻找oom的原因,以及对自己结论的验证。
当看到 这段下面这段代码线程池代码的时候,小张差点气昏过去:
ExecutorService executorService = Executors.newFixedThreadPool(3);线程池用了jdk自带的一个线程个数只有3个,且任务队列是无界的FixedThreadPool实现。
消息堆积的原因:从消息队里消费的消息都积压在了无界队列里,http请求只有3个线程并行的发送,当消息处理服务器处理效率变慢时,线程从无界队列里取出消息的效率也会变慢。最终导致消息积压在了这个无界队列,时间久了,出现了oom。
5.小张失算了
问题找了,方案也就出来了。不再使用工具类提供的FixedThreadPool线程池,于是小张自定义一个线程池,为了提高消息中转服务发送消息的效率,小张决定把线程池中线程个数调大,但是调整多大呢?小张罗列出了当前系统中几个重要的消息处理速度指标值:
(1)消息队列kafka发送消息的效率:15个/s
(2)消息处理服务的处理耗时 2-3s左右.
要想保证消息不堆积,消息处理的速度要能达到消息发送的速度,但是现在消息服务处理消息的速度,明显小于消费发送的速度。为了平衡两者之间处理效率的差异,中间可以采用多线程处理。消息处理服务处理消息的速度按照3s算的话,要想达到每秒处理15个消息,线程个数至少要45个。经过计算之后,小张把最大线程池个数设置成了50,为了减少服务重启,造成数据丢失的影响,任务队列的大小设置为128,同时为了防止消息丢失,拒绝策略设置为:在提交任务的线程中执行。
ExecutorService messageThreadPool = new ThreadPoolExecutor(20,
50,
60,
TimeUnit.SECONDS,
new ArrayBlockingQueue<Runnable>(128),
new ThreadFactory() {
AtomicInteger index = new AtomicInteger(0);
@Override
public Thread newThread(Runnable r) {
return new Thread(r,"msgProcess-"+index.getAndAdd(1));
}
},new ThreadPoolExecutor.CallerRunsPolicy());核心线程数20,最大线程数50,超时等待时间为60s,同时该线程池创建的出的线程的的名字会以”msgProcess-”开头,便于线程的区分与问题排查,同时当线程达到最大线程个数后,执行的拒绝策略为在提交任务的线程池中执行。
修改后,重启了消息中转服务。服务启动后,小张观察片刻,中转服务的内存占用,经过缓慢的上升后,基本趋于稳定。"看来我的修改生效了"小张心中一阵暗喜。
忙活了一上午,终于可以安心的去吃午饭了。午饭后,小张再次打开了 中转服务的内存监控,服务内存占用和午饭前相比并没有太多的升高。小张得意的看着自己自定义的那个线程池,频频点头。
此时小张想起上午,没有排查完的问题-消息处理服务处理变慢的问题。于是,小张再次登上消息处理服务,下载最近一个小时的日志,进行查看。
看到日志,小张的眼睛都瞪圆了,消息处理时间和消息产生时间又差了近一个小时。消息又堆积了? 难道我的修改没有生效?
6.消息再次堆积的原因
查看了消息队列的监控,消息果然堆积了,黑人问号的表情,浮现的小张的大脑中。
小张又看了一下消息处理服务的负载情况和gc,都很正常。但是处理请求的qps仅仅只有个位数,难道消息中转服务配置的线程个数没有生效?看来问题是出在了消息中转服务上了。
小张仔细查看了检查了消息中转服务中自己写的那个线程池。发送请求的线程数有50个,但是消息处理服务接受请求接口的qps 却是个位数,按照每个请求处理时间3s计算的话,qps也应该能达到 17左右(50/3),难不成 这么多线程没有起作用? 小张仔细核查了项目中使用的HttpClient框架的参数配置:
defaultMaxPerRoute= 10
defaultMaxTotal=100用过HttpClient的小伙伴,应该都知道,defaultMaxPerRoute限制了client 向一个主机发送请求时最大可以获得的连接数,defaultMaxTotal限制了向所有服务器主机发送请求时最大可以获得的连接数。
因为目前消息处理服务只有一个服务器,也就是说虽然 发送请求的线程有50个,但是可以获得连接数只有10个,也就是同时只能有10个线程可以获得连接,其他40个线程都会阻塞等待获取可用的连接,有点千军万马过独木桥的感觉。
到这里,小张终于找到了原因,把defaultMaxPerRoute这个参数调整为100,同时为了加快把堆积消息处理掉,又把线程池最大线程个数调整为100,调整后,消息处理服务器处理消息的效率有了明显的增长,消息也逐渐的不在堆积。
但是小张明白,今天这些参数的调整,有些草率,这些线程池大小,连接数大小的调整,要结合服务的监控来进行调整,才能知道每次调整产生的效果怎么样,而且上游发送请求过多,会不会对下游服务产生太大的压力。现在这套服务的监控还不完善,问题排查也不方便。看来这套服务上线前还有很多工作要做,小张陷入了沉思