ArrayList
ArrayList整体架构
首先看一下ArrayList的类继承关系,源码中的签名为
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
public abstract class AbstractList<E> extends AbstractCollection<E> implements List<E>
public abstract class AbstractCollection<E> implements Collection<E>
public interface Collection<E> extends Iterable<E>
我们把以上继承关系可视化。

Collection和Iterable接口相信每个人都很熟悉,不用多说,他们指定了一系列Java集合的通用实现接口定义而不提供实现。我们从提供基本实现的抽象类AbstractCollection开始看。
AbstractCollection
AbstractCollection是顶层的集合抽象类,许多类都继承于此抽象类。通过IDEA的关系图可以观察继承关系为。

HashMap部分暂且不表,我们可以看出比较明显的是AbstractSet,AbstractList,AbstracQueue都继承了AbstractCollection类。
AbstractCollection具体都做了什么呢?通过研究源码可以发现,这个抽象类通过iterator()方法获取到集合的迭代器,然后对能通过迭代器进行迭代比较实现的contains,toArray,containsAll等等基础的方法提供了默认实现。很容易理解。
在AbstractCollection类中,有三个private级别的成员和方法引人注目。他们是MAX_ARRAY_SIZE,finishToArray,hugeCapacity。其具体实现如下。

我们结合注释来理解一下这几个函数的意思。首先看finishToArray。它是由toArray方法调用的。

toArray方法返回一个集合中的元素包含的数组。很容易理解,注释中提到,即使在迭代的过程中集合中元素数量发生了变化导致迭代器返回了超出预期或小于预期的数量的时候,该方法仍能保证正确返回数组。阅读源码来观察一下具体做法。
该方法首先假设数量是正确的并使用new Object[size()]来分配数组的内存,当小于预期的时候,使用Array.copyOf()来通过Arrays的原生方法切分多余的空间并返回一个新的包含正确元素的数组。在大于预期的时候则使用finishToArray方法。进入finishToArray方法,可以看到首先他获取了原数组的长度,并且进入循环首先进行一个扩容操作。确定新的容量的方法为newCap = cap + (cap >> 1) + 1,如果扩容后的大小大于MAX_ARRAY_SIZE则通过hugeCapacity(cap+1)获取一个新的容量。hugeCapacity方法首先判断扩容后的容量+1是否溢出变为负数,若溢出就直接抛出异常。如果没有溢出,则再次判断minCapacity和MAX_ARRAY_SIZE的大小,即与Integer.MAX_VALUE-8的关系,如果大于则直接返回Integer.MAX_VALUE,如果小于则返回MAX_ARRAY_SIZE。在进行扩容之后,在往里分配元素,如果元素等于上限之后,就再次走扩容逻辑。当分配完所有的元素之后,使用Arrays.copyOf对数组进行一个剪切,将扩容后无元素放入的无效区域剪切掉。
这里出现了一个问题,
为什么MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8?
这是一个比较复杂的问题,涉及到虚拟机规范,Java规范与具体实现之间的问题。
stackOverFlow上有相关讨论:https://stackoverflow.com/questions/35756277/why-the-maximum-array-size-of-arraylist-is-integer-max-value-8
要理解这个问题,首先要理解Java内存模型,具体内容可参考https://www.ibm.com/developerworks/java/library/j-codetoheap/index.html
由于位运算,扩容后的结果将总是8的倍数,所以传入此函数的参数的大小要么溢出,要么小于Integer.MAX_VALUE - 8,要么等于Integer.MAX_VALUE - 8,而由于Java规范中规定在实现具体的虚拟机时,可以限定数组的大小,不需要保证数组的最大下标上限是 Integer.MAX_VALUE。因此虚拟机在实现具体的JVM时,可能会使得数组的分配上限为Integer.MAX_VALUE - 8到Integer.MAX_VALUE中的一个区间,根据具体实现有所不同,而如果超出上限就可能会导致运行出现错误。这是模糊的,因为一般来说,不直接看JVM源码,我们无从得知具体是如何实现的。
虽然是这样,但是这个地方应该仅仅是属于一种边界优化行为,最大长度依然是Integer.MAX_VALUE,并不是Integer.MAX_VALUE-8,看最后三目运算符返回的值就知道了。如果大于如果确实碰到注释中说到的
/**
* The maximum size of array to allocate.
* Some VMs reserve some header words in an array.
* Attempts to allocate larger arrays may result in
* OutOfMemoryError: Requested array size exceeds VM limit
*/
这样的行为,那这样的数组已经扩张到非常接近上限的大小了,那若数组进一步扩大就直接OOM异常了,同样直接终止了这种异常行为。
AbstractList
AbstractList继承了AbstractCollection并实现了List接口。具体包含以下方法和对象。

AbstractList的Itr对象实现了Iterior接口,ListItr则继承于Itr对象并实现了ListIterator接口。聚焦于这两个接口,比较一下其方法,可以发现:

比较这两个方法截图就可以看出ListIterator比Iterator方法多出了set,add,previousIndex,nextIndex,previous,hasPrevious方法。从命名就可以大致推断出来,这是专为List数据结构设计的迭代器类。比起普通的迭代器它多出了设置值、添加值、前后移动的特性,是迭代器针对List的特化。
Iteator实现AbstractCollectior接口的方法,而ListIterator实现了List接口的方法。
继续看其他方法。
get方法留给子类去实现,是抽象方法,而set、add、remove方法直接抛出UnsupportedOperationException异常,需要子类重写。
indexOf和lastIndexOf方法利用遍历ListIterator方法进行了实现,clear方法委托给了rangeRemove方法,同样由ListIterator去进行具体操作。
addAll方法简单的使用forEach循环和add方法进行了实现。
subList方法返回一个subList子列表:

这里值得注意。因为subList并不被暴露为返回subList而是一个List类的对象,对于外部来说subList获取的对象和普通的List很难区分。日常操作中最好了解这个方法的具体内容,不然具体使用的时候很可能会踩坑。
先跳到SubList。
SubList
重点源码是SubList的构造。

SubList的源码很简单,仅仅是一种委托行为,这里只是设置了subList的大小和偏移量这也就意味着SubList并不是从原列表中deepClone一个新的列表出来,而是简单的根据传入的参数改变下标为原列表的下标,把操作委托给了原来的列表!这代表你操作的列表并非独立于原列表,而仅仅是原来列表的引用!
SubList就是这么简单。
此外还有RandomAccessSubList,这个就更简单了,RandomAccessSubList只是一个带有RandomAccess标志的SubList类而已,这样程序员就可以通过是否带有接口判断是否能这个List是否支持随机访问了。
此外还可以看一眼列表的equals方法和hashCode方法,很容易看出equals方法只是用==去比较所有的列表元素,而hashCode则是使用hashCode = 31+ (e==null ? 0 : e.hashCode())去根据所有的列表元素值计算出hash来。


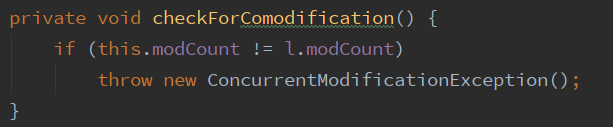
而剩下的modCount成员是一个为了防止迭代器迭代中修改了迭代器而引发bug的协助字段。即实现迭代器的快速失败(fast-fail)策略。checkForComodification方法就是一个检测是否出现此类异常行为并快速失败的方法。而如果你想实现一个子类,不需要快速失败的策略,只要忽略它就行了。这是一个很常见的字段,它需要被手动编写序列化代码,因此定义了transient标志,其他集合类中我们也可以见到这个成员。
![]()
重头戏: ArrayList
1.成员变量

成员变量一共有6个。
serialVersionUID
是用于反序列化时的一个UID,这个很常见,是序列化相关的知识,在这里不用多说。
DEFAULT_CAPACITY
是一个常量,指示了默认的初始化列表大小为10。
EMPTY_ELEMENTDATA、DEFAULTCAPACITY_EMPTY_ELEMENTDATA、elementData三个是同样的Object[] 类型的成员变量,他们各自的用处到底是什么呢?我们阅读一下注释。
EMPTY_ELEMENTDATA
用于空实例的共享空数组实例。
用人话来说,就是使用new ArrayList(0)的时候,就会调用elementData == EMPTY_ELEMENTDATA 。
DEFAULTCAPACITY_EMPTY_ELEMENTDATA
共享的空数组实例,用于默认大小的空实例。我们将其与EMPTY_ELEMENTDATA区别开来,以判断添加第一个元素时需要扩容多少。
用人话来说,就是使用new ArrayList()的时候,就会调用elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA 。
elementData
用于存储ArrayList元素的数组缓冲区。
ArrayList的容量是此数组缓冲区的长度。添加第一个元素时,任何具有elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA 的空ArrayList都将扩容为为DEFAULT_CAPACITY.
这是ArrayList的核心,一个object[]类型的数组。
Size
表示List元素的数量。
2.构造函数



构造函数有三种。带初始容量的构造器,传入一个集合的构造器,以及空值构造器。
一、带初始容量的构造器
如果容量大于0,就给elementData分配一个堆中的内存区域。如果等于0,就直接将EMPTY_ELEMENTDATA引用给elementData,不进行具体内存分配。这将在第一次add的时候发挥作用,到时候就知道了。
二、传入集合的构造器
使用集合的toArray方法,此为接口方法,任何实现Collection的类都会实现它,这样就获取了它的底层数据结构,通常都是Object[]。(非正常情况见JDK bug记录: https://bugs.java.com/bugdatabase/view_bug.do?bug_id=6260652)然后根据此数组的长度对size赋值,若长度大于0且为object[]的类型,直接用Arrays.copyOf方法把集合的底层数组复制到arrayList中。如果等于0就简单的将EMPTY_ELEMENTDATA引用给elementData,不进行具体内存分配。这和上个构造是同样的套路。
三、空值构造器
直接将DEFAULTCAPACITY_EMPTY_ELEMENTDATA引用给elementData,这与之前的EMPTY_ELEMENTDATA虽然都是空数组但是不是同一个成员,是JDK8的一种优化手段,在add元素的时候会根据此标志走不同的扩容策略。
3.重要的方法
一、add与扩容

在尾部添加一个元素。
非常关键的方法,继承于AbstractList,在此处进行实现。
扩容逻辑就是第一步。传入一个添加元素之后的size,去判断是否应该扩容。

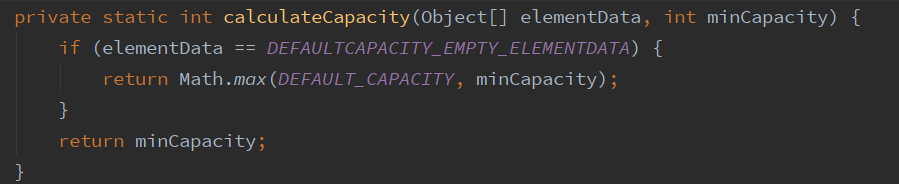
首先走一个calculateCapacity。在这里我们看见了熟悉的DEFAULTCAPACITY_EMPTY_ELEMENTDATA,可以看出若此时传入的minCapacity小于DEFAULT_CAPACITY即10,就直接返回10。否则就把minCapacity传回去。
在这里进行了扩容操作。可以看到若当前数组内元素数量小于add后大小,就会去走grow方法,grow是ArrayList的核心扩容逻辑,进一步读源码。


扩容机制很简单,就一句话,Arrays.copyOf,完了。Java中ArrayList的扩容为1.5倍,使用位运算实现,左移一即除2。newCapacity就是原容量的1.5倍。
第一个If出现的情况可能是防止位运算溢出等意外情况。此时扩容数量为size+1。第二个IF语句与AbstractList的判断一模一样,不用再多说,效果都一样!

add的重载方法,这里的add应该解释为插入。先检查进行范围检查,然后确定是否应扩容,然后调用arraycopy方法去移动数组内的内存数据,之后在下标插入数据,很明显这里的add方法复杂度为O(N)因为涉及到内存的复制!