大数据跟我学flink系列文章000-Flink问题集锦
——03.Flink 常用的 DataSet 和 DataStream API
介绍 Flink 的 DataSet 和 DataStream 的 API,并模拟了实时计算的场景,详细讲解了 DataStream 常用的 API 的使用
文章目录
前言
本文为拉勾课程《 42讲轻松通关 Flink》笔记,本着“只有亲身实践过并整理成体系才属于自己真正掌握的知识” 的理念写出本篇文章,后续每天更新,持续关注,欢迎留言讨论~。
提示:以下是本篇文章正文内容,下面案例仅供参考
一、Flink实操问题?
1.yarn
1)flink yarn-session的两种使用方式
spark,flink都能进行流处理和批处理。spark的文章写了好多,请在本博客中去搜索
flink on yarn模式中,flink yarn-session的两种使用方式分析
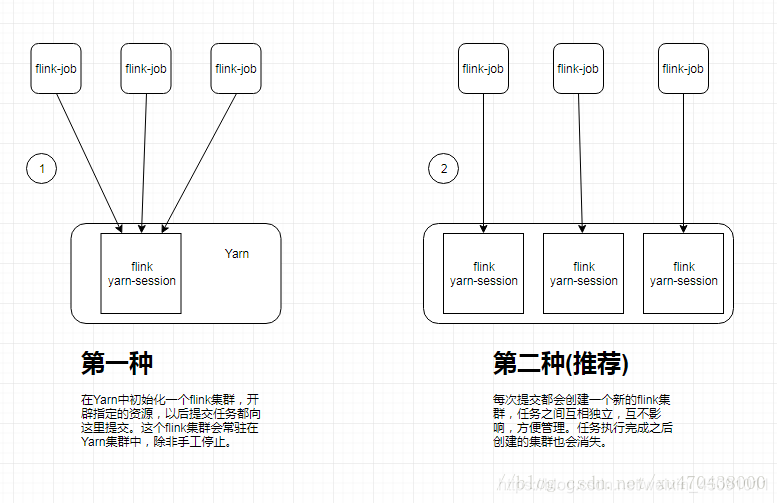
第一种:在yarn中初始化一个flink集群,开辟指定的资源,以后提交任务都向这里提交。这个flink集群会常驻在yarn集群中,除非手工停止。
第二种(推荐):每次提交都会创建一个新的flink集群,任务之间互相独立,互不影响,方便管理。任务执行完成之后创建的集群也会消失。
一,有常驻进程的flink(一直是running的进程),去执行任务
1,启动flink,并分配资源
./yarn-session.sh -n 2 -jm 1024 -tm 1024
./yarn-session.sh -id application_1584936998803_0066
上面是命令行模式下,启动并分配资源。也可以通过cloudera manager的管理后台,启动flink,启动后,就已经绑定了,flink的running进程,也就是绑定application id
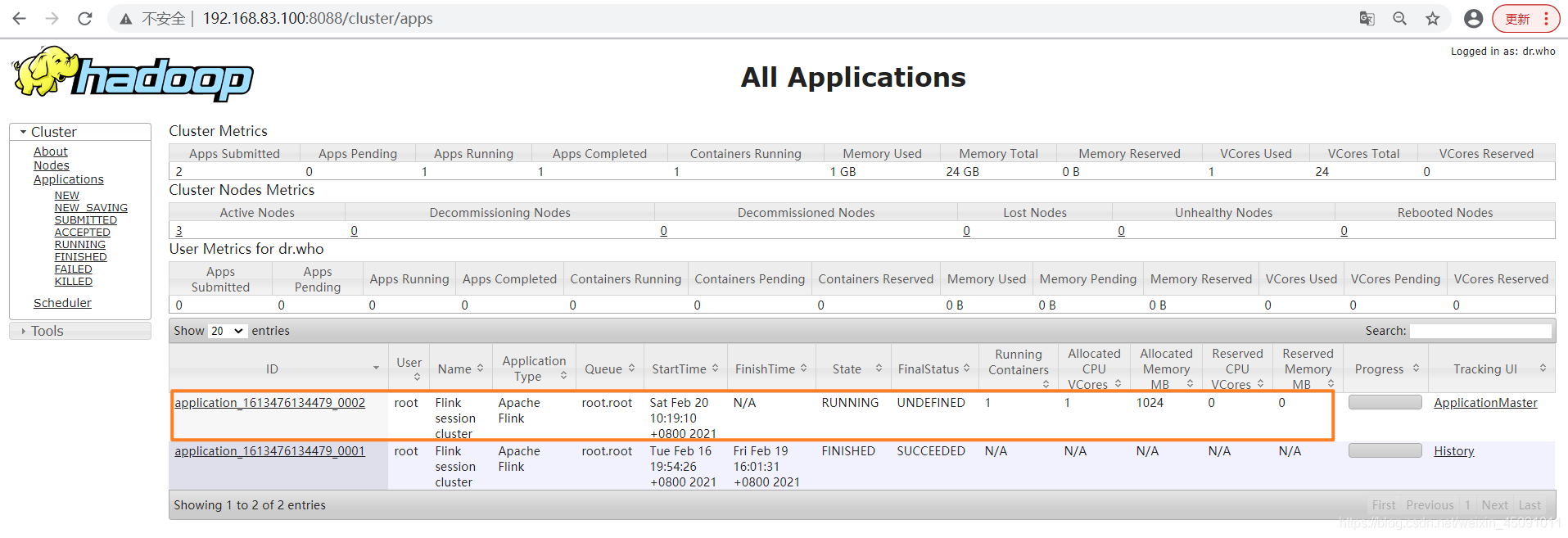
2,提交任务
yarn application -list
./flink run ../examples/streaming/WordCount.jar --input hdfs://bigdata1/test/word --output hdfs://bigdata1/test/word4

./flink run -yid application_1584936998803_0013 ../examples/streaming/WordCount.jar --input hdfs://bigdata/test/word --output hdfs://bigdata/test/word1
注意:在cloudera manager所在的机器一直提交不成功。datanode,namenode都可以提交成功。
查看application错误日志发现:
org.apache.flink.shaded.curator.org.apache.curator.ConnectionState - Authentication failed
该错误是因为,kerberos认证失败,cdh6,并没有启动kerberos。所以该错误可以忽略。但是如果已经开启动了kerberos,这个问题就要解决了。
3,指定application id提交任务
[root@bigserver5 bin]# ./flink run -yid application_1584936998803_0013 ../examples/streaming/WordCount.jar --input hdfs://bigdata1/test/word --output hdfs://bigdata1/test/word1
Setting HADOOP_CONF_DIR=/etc/hadoop/conf because no HADOOP_CONF_DIR was set.
2020-03-23 14:12:46,020 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2020-03-23 14:12:46,020 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2020-03-23 14:12:46,024 WARN org.apache.flink.yarn.AbstractYarnClusterDescriptor - Neither the HADOOP_CONF_DIR nor the YARN_CONF_DIR environment variable is set.The Flink YARN Client needs one of these to be set to properly load the Hadoop configuration for accessing YARN.
2020-03-23 14:12:46,065 INFO org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider - Failing over to rm188
2020-03-23 14:12:46,104 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Found application JobManager host name 'bigserver3' and port '8081' from supplied application id 'application_1584936998803_0013'
Starting execution of program
Program execution finished
Job with JobID 595d31cb57ded04387241090f1a7349c has finished.
Job Runtime: 11990 ms
指定了application id,在集群中的任何一台机器执行都可以。
二,提交flink任务时,再获取资源,这一点根spark-submit很像
1,停止flink的集群,也就是说,yarn application -list,没东西。这一步很重要。如果不做,任务提交不成功,会报以一下错误。
2020-03-23 13:49:43,510 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Deployment took more than 60 seconds. Please check if the requested resources are available in the YARN cluster
错误的原因:cloudera manager,所在的机器8030端口,已被running的application id占用。
2,提交任务
[root@bigserver2 bin]# ./start-cluster.sh //启动集群,不然报 拒绝连接: localhost/127.0.0.1:8081
[root@bigserver2 bin]# ./flink run -m yarn-cluster -yn 1 -yjm 1024 -ytm 1024 ../examples/streaming/WordCount.jar --input hdfs://bigdata1/test/word --output hdfs://bigdata1/test/word_res1
Setting HADOOP_CONF_DIR=/etc/hadoop/conf because no HADOOP_CONF_DIR was set.
2020-03-23 15:30:14,804 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2020-03-23 15:30:14,804 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2020-03-23 15:30:14,808 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - The argument yn is deprecated in will be ignored.
2020-03-23 15:30:14,808 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - The argument yn is deprecated in will be ignored.
2020-03-23 15:30:14,897 INFO org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider - Failing over to rm188
2020-03-23 15:30:14,930 WARN org.apache.flink.yarn.AbstractYarnClusterDescriptor - Neither the HADOOP_CONF_DIR nor the YARN_CONF_DIR environment variable is set. The Flink YARN Client needs one of these to be set to properly load the Hadoop configuration for accessing YARN.
2020-03-23 15:30:14,993 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Cluster specification: ClusterSpecification{
masterMemoryMB=1024, taskManagerMemoryMB=1024, numberTaskManagers=1, slotsPerTaskManager=1}
2020-03-23 15:30:15,305 WARN org.apache.flink.yarn.AbstractYarnClusterDescriptor - The configuration directory ('/opt/cloudera/parcels/FLINK-1.9.1-BIN-SCALA_2.12/lib/flink/conf') contains both LOG4J and Logback configuration files. Please delete or rename one of them.
2020-03-23 15:30:30,820 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Submitting application master application_1584936998803_0069
2020-03-23 15:30:31,071 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl - Submitted application application_1584936998803_0069
2020-03-23 15:30:31,072 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Waiting for the cluster to be allocated
2020-03-23 15:30:31,075 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Deploying cluster, current state ACCEPTED
2020-03-23 15:30:36,860 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - YARN application has been deployed successfully.
Starting execution of program
Program execution finished
Job with JobID 7a3b8837bcc214eab0732361e73b55a1 has finished.
Job Runtime: 24120 ms
2.zookeeper
zookeeper 权限

ZooKeeper设置ACL权限控制,删除权限
按照上面老铁的操作执行一遍,发现没有任何作用,仔细看了下子自己的的日志

同样是ZK的权限问题,这篇文章可能有点帮助

解决:zookeeper 3.4.6之后,在创建zk连接之前可以通过设置系统参数(zookeeper.client.sasl)为false来禁用sasl认证。
啥也别说了,升级吧:ZooKeeper 安装完整版——ZooKeeper3.4.6。
终于:在第一个问题yarn-session的提交上发现了这个问题,可以忽略了,因为网络原因,zk就不下了。

3)hadoop
