学习大数据的契机
原因
在学习之前的是一直在干java开发的,但是手头上有个比较大的项目,本来是到9月底的样子就应该结束的,但后面需求变更,导致系统需要大改,之前的那批人也都走的差不多了(几个团队一起开发),所以到后面系统的整体架构的任务就交到我手上来了。
刚开始还好,慢慢改整体逻辑架构,其中从其他人代码中也学到了很多东西,可是过了一个来月的开发周期,11月的时候,也开发的差不多了,后面很多都是简单的逻辑处理,而且写得我很安逸,几乎遇不到什么问题了,这个感觉很不爽,然后优化完一些sql,写了一些异步编排接口,但是还是很安逸,尝试优化代码架构,可是优化了部分觉得很多是重复工作,于是想学习一些新的东西了;
找资料阶段
所以我开始从晚上找资料,然后是在b站上面看到尚硅谷发了很多新的视频,hive3.1.2、spark3、数仓3.0等,然后就下决心开了大数据学习, 我从朋友那里借来谷粒学院的账号(这里面的视频在b站上大多数都有,只是在b站上看容易分心去看弹幕,我是喜欢开弹幕的那种),然后开始学习,从hadoop开始,大概学到一半,项目又进行迭代升级,我又又又去开发了,估计有三周左右的时间,天天加班,然后学习又停滞了,大概是快11月底的时候,我才狠下心来跟负责人说,我不想写代码了,可以做做运维,然后就交给其他人去写代码了,我只要复制指导一下就行;
学习周期
首先是根据资料文档+视频很快的过了一遍hadoop剩下的,把map、reduce那个阶段的东西学习了一下,然后就开始学习hive,关于hive-sql那里的很多东西跟sql语法很像,所以很多东西我没看,然后看了下数仓需要的技术点,发现很多东西之前都听过,所以直接开干,搞起了数仓的项目。
数仓的概念
数仓仓库(data warehouse):是为企业所有决策制定过程,提供所有系统数据支持的战略集合。通过数据仓库的分析可以帮助企业,改进业务流程、控制成本、提高产品质量等。
数据仓库并不是所有数据的存放地,而是为数据最终最终目的地做准备,这些准备包括:清洗、转义、分类、重组、合并、拆分、统计等等。
其大致流程:

项目的需求及架构
需求分析
整个数仓参考尚硅谷-谷粒学院的课程设计:
1. 用户行为的日志采集(通过设置埋点的方式)
2. 业务数据采集的平台搭建(将mysql中的数据导入到hdfs)
3. 数据仓库的维度建模(ods、dwd、dws、dwt、ads)
4. 分析(设备、用户、地区)等电商的核心主题,需要有近100个指标支持
5. 采用即席查询工具,随时进行指标分析(亚秒级、秒级的大数据量查询)
6. 整个集群系统的任务调度(特定的任务不需要任务去每天重复操作)
7. 集群的整体性能监控,并在异常的时候进行报警。
8. 元数据管理
项目架构
一、技术选型

二、系统数据流程设计
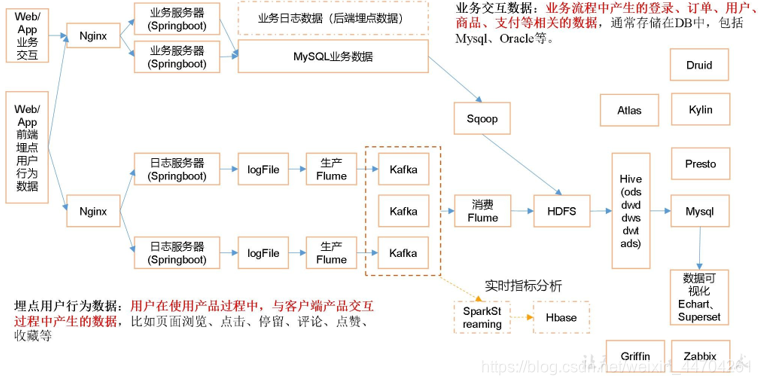
三、系统技术版本选择
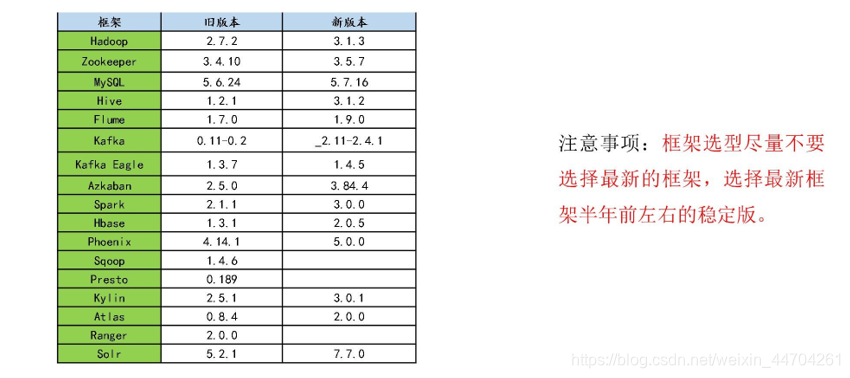
四、服务器选型

五、集群规划

数据来源
数据埋点
- 主流埋点方式(了解)
目前主流的埋点方式,有代码埋点(前端/后端)、可视化埋点、全埋点三种。
代码埋点是通过调用埋点 SDK 函数,在需要埋点的业务逻辑功能位置调用接口,上报埋点数据。例如,我们对页面中的某个按钮埋点后,当这个按钮被点击时,可以在这个按钮对应的 OnClick 函数里面调用 SDK 提供的数据发送接口,来发送数据。
可视化埋点只需要研发人员集成采集 SDK,不需要写埋点代码,业务人员就可以通过访问分析平台的“圈选”功能,来“圈”出需要对用户行为进行捕捉的控件,并对该事件进行命名。圈选完毕后,这些配置会同步到各个用户的终端上,由采集 SDK 按照圈选的配置自动进行用户行为数据的采集和发送。
全埋点是通过在产品中嵌入 SDK,前端自动采集页面上的全部用户行为事件,上报埋点数据,相当于做了一个统一的埋点。然后再通过界面配置哪些数据需要在系统里面进行分析。
- 埋点数据日志结构
我们的日志结构大致可分为两类,一是普通页面埋点日志,二是启动日志。
普通页面日志结构如下,每条日志包含了,当前页面的页面信息,所有事件(动作)、所有曝光信息以及错误信息。除此之外,还包含了一系列公共信息,包括设备信息,地理位置,应用信息等,即下边的 common 字段。
- 埋点数据上报时机
埋点数据上报时机包括两种方式。
方式一,在离开该页面时,上传在这个页面发生的所有事情(页面、事件、曝光、错误等)。优点,批处理,减少了服务器接收数据压力。缺点,不是特别及时。
方式二,每个事件、动作、错误等,产生后,立即发送。优点,响应及时。缺点,对服务器接收数据压力比较大
业务数据
一般就是数据库里面的数据
总结
上面是整个数据仓库的设计,从概念、需求、技术选型等着手考虑,完全适用于中小型企业的实际生产,接下来几篇博客会详细讲解整个数仓搭建过程;
感谢大家阅、互相学习;
感谢尚硅谷提供的学习资料;
有问题评论或者发邮箱;
gitee:很多代码仓库;
[email protected]