hadoop安装与搭建
集群规划
| 服务器 hadoop102 | 服务器 hadoop103 | 服务器 hadoop104 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | DataNode SecondaryNameNode |
| Yarn | NodeManager | Resourcemanager NodeManager | NodeManager |
环境准备
依旧是前面搭建jdk环境的三台主机,为了之后集群之间的文件传输,所以之后会使用集群分发脚本,可以参考这篇博客:大数据-集群分发脚本
将hadoop3.1.3压缩包解压到module模块:
/opt/module/hadoop-3.1.3
刚开始解压的时候是没有data和logs
然后开始修改配置文件:
配置 core-site.xml:
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置hdfs网页登录使用的静态用户为root -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 配置该 root 允许通过代理访问的主机节点 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<!-- 配置该 root 允许通过代理用户所属组 -->
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- 配置该 root 允许通过代理的用户 -->
<property>
<name>hadoop.proxyuser.root.users</name>
<value>*</value>
</property>
<!-- 对压缩的支持 -->
<property>
<name>io.compression.codecs</name>
<value>
org.apache.hadoop.io.compress.GzipCodec, org.apache.hadoop.io.compress.DefaultCodec, org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.SnappyCodec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec
</value>
</property>
<property>
<name>io.compression.codec.lzo.class</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
配置hdfs-site.xml文件:
<!-- nn web端访问地址 -->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- 2nn web端访问地址 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
<!-- 副本数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
配置yarn-site.xml文件:
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- YARN 容器允许分配的最大最小内存 -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<!-- yarn容器允许管理的物理内存的大小 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!-- 关闭yarn对物理内存和虚拟内存的限制检查 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- 保存的天数 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
配置mapred-site.xml文件:
<!-- 指定MR运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<!-- 历史服务器wbe端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>
然后分发文件:
xsync /opt/module/hadoop-3.1.3/
单点启动集群
- 如果集群是第一次启动,需要格式化NameNode
hadoop namenode -format
- 在hadoop102上启动NameNode
hadoop-daemon.sh start namenode
- 在hadoop102、hadoop103以及hadoop104上分别启动DataNode
hadoop-daemon.sh start datanode
群起集群
SSH无密登录配置
-
配置ssh
(1)基本语法
ssh另一台电脑的ip地址
(2)ssh连接时出现Host key verification failed的解决方法ssh 192.168.1.103 The authenticity of host '192.168.1.103 (192.168.1.103)' can't be established. RSA key fingerprint is cf:1e:de:d7:d0:4c:2d:98:60:b4:fd:ae:b1:2d:ad:06. Are you sure you want to continue connecting (yes/no)? Host key verification failed.(3)解决方案如下:直接输入yes
-
无密钥配置
(1)免密登录原理:
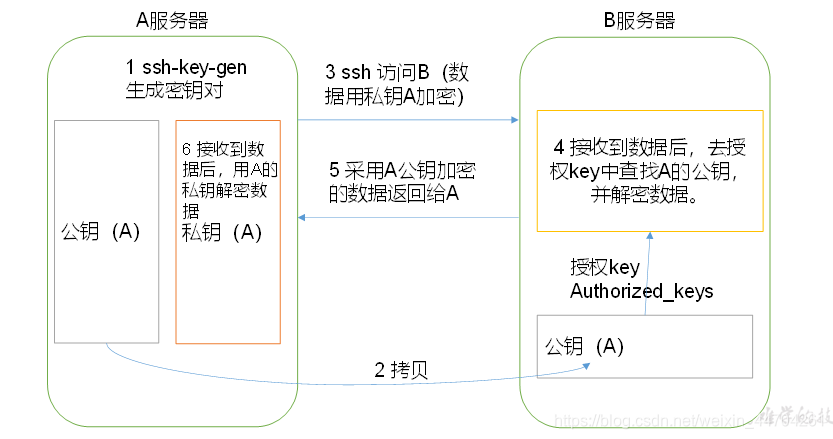
(2)生成公钥和私钥:ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
(3)将公钥拷贝到要免密登录的目标机器上
# 在hadoop102上
ssh-copy-id hadoop102
# 在hadoop103上
ssh-copy-id hadoop103
# 在hadoop104上
ssh-copy-id hadoop104
注意:
还需要在hadoop102上采用root账号,配置一下无密登录到hadoop102、hadoop103、hadoop104;
.ssh文件夹下(~/.ssh)的文件功能解释
| known_hosts | 记录ssh访问过计算机的公钥(public key) |
|---|---|
| id_rsa | 生成的私钥 |
| id_rsa.pub | 生成的公钥 |
| authorized_keys | 存放授权过得无密登录服务器公钥 |
群起集群配置
vim /opt/module/hadoop-3.1.3/etc/hadoop/slaves
在该文件中增加如下内容:
hadoop102
hadoop103
hadoop104
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
分发脚本:
xsync slaves
集群启动:
在hadoop102上启动:
sbin/start-dfs.sh
在hadoop103上启动yarn
sbin/start-yarn.sh
注意:NameNode和ResourceManger如果不是同一台机器,不能在NameNode上启动 YARN,应该在ResouceManager所在的机器上启动YARN。
测试集群
成功之后:http://hadoop102:9870/(windows上做了域名解析)
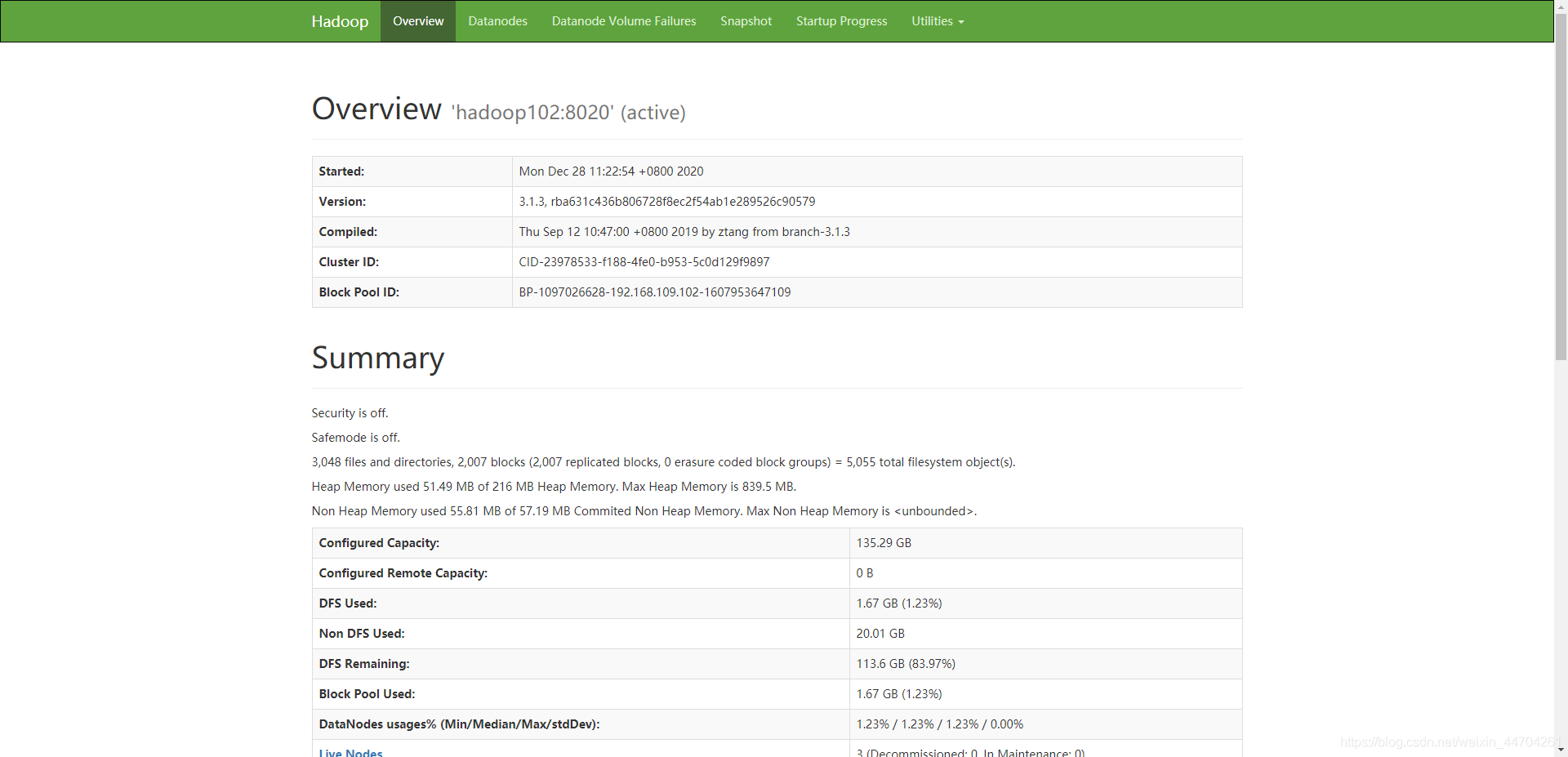
这里是hdfs的ui操作端:
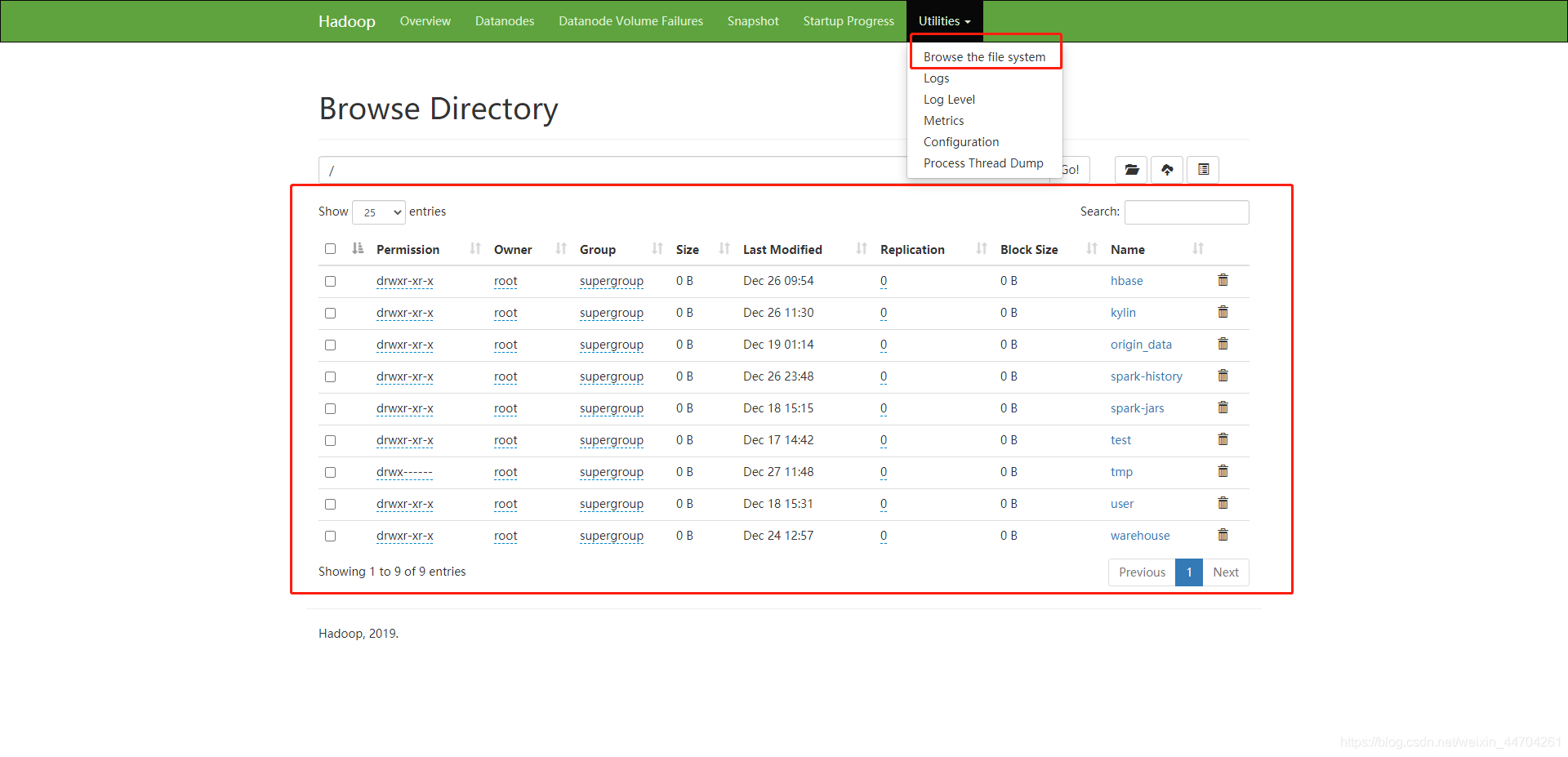
在hadoop3.1.3之后,可以直接在界面操作文件,增删改查之类的;
访问:http://hadoop103:8088/

这是整个集群的信息;这两个界面都能正常访问,那就证明整个集群成功启动;
hdfs的相关操作
基本命令
[root@hadoop102 hadoop-2.7.2]$ bin/hadoop fs
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] <localsrc> ... <dst>]
[-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] <path> ...]
[-cp [-f] [-p] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] <path> ...]
[-expunge]
[-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getmerge [-nl] <src> <localdst>]
[-help [cmd ...]]
[-ls [-d] [-h] [-R] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{
-b|-k} {
-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touchz <path> ...]
[-usage [cmd ...]]
基本命令实操
(0)启动Hadoop集群(方便后续的测试)
[root@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
[root@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
(1)-help:输出这个命令参数
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -help rm
(2)-ls: 显示目录信息
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -ls /
(3)-mkdir:在HDFS上创建目录
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir -p /sanguo/shuguo
(4)-moveFromLocal:从本地剪切粘贴到HDFS
[root@hadoop102 hadoop-3.1.3]$ touch kongming.txt
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -moveFromLocal ./kongming.txt /sanguo/shuguo
(5)-appendToFile:追加一个文件到已经存在的文件末尾
[root@hadoop102 hadoop-3.1.3]$ touch liubei.txt
[root@hadoop102 hadoop-3.1.3]$ vi liubei.txt
# 输入
san gu mao lu
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -appendToFile liubei.txt /sanguo/shuguo/kongming.txt
(6)-cat:显示文件内容
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -cat /sanguo/shuguo/kongming.txt
(7)-chgrp 、-chmod、-chown:Linux文件系统中的用法一样,修改文件所属权限
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -chmod 666 /sanguo/shuguo/kongming.txt
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -chown atguigu:atguigu /sanguo/shuguo/kongming.txt
(8)-copyFromLocal:从本地文件系统中拷贝文件到HDFS路径去
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -copyFromLocal README.txt /
(9)-copyToLocal:从HDFS拷贝到本地
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -copyToLocal /sanguo/shuguo/kongming.txt ./
(10)-cp :从HDFS的一个路径拷贝到HDFS的另一个路径
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -cp /sanguo/shuguo/kongming.txt /zhuge.txt
(11)-mv:在HDFS目录中移动文件
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -mv /zhuge.txt /sanguo/shuguo/
(12)-get:等同于copyToLocal,就是从HDFS下载文件到本地
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -get /sanguo/shuguo/kongming.txt ./
(13)-getmerge:合并下载多个文件,比如HDFS的目录 /user/atguigu/test下有多个文件:log.1, log.2,log.3,…
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -getmerge /user/root/test/* ./zaiyiqi.txt
(14)-put:等同于copyFromLocal
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -put ./zaiyiqi.txt /user/root/test/
(15)-tail:显示一个文件的末尾
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -tail /sanguo/shuguo/kongming.txt
(16)-rm:删除文件或文件夹
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -rm /user/root/test/jinlian2.txt
(17)-rmdir:删除空目录
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /test
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -rmdir /test
(18)-du统计文件夹的大小信息
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -du -s -h /user/root/test 2.7 K /user/atguigu/test
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -du -h /user/atguigu/test
1.3 K /user/atguigu/test/README.txt
15 /user/atguigu/test/jinlian.txt
1.4 K /user/atguigu/test/zaiyiqi.txt
(19)-setrep:设置HDFS中文件的副本数量
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -setrep 10 /sanguo/shuguo/kongming.txt
关于其他的一些操作,这里先不讲了,之后有时间在详细讲讲hadoop的其他相关的东西,namenode、datanode、服役新节点、退役纠结点、添加黑名单、白名单等;
hadoop使用的一些经验
项目经验之HDFS 存储多目录
-
查看服务器磁盘使用情况
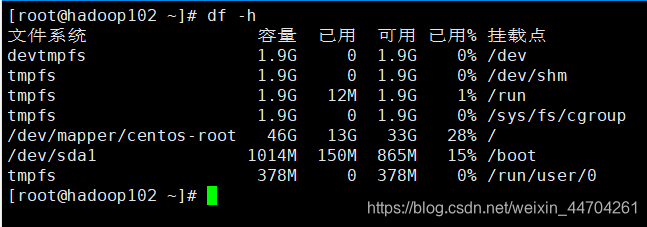
-
在 hdfs-site.xml 文件中配置多目录,注意新挂载磁盘的访问权限问题。
HDFS 的 DataNode 节点保存数据的路径由 dfs.datanode.data.dir 参数决定,其默认值为
file://${hadoop.tmp.dir}/dfs/data,若服务器有多个磁盘,必须对该参数进行修改。如服务器磁盘如上图所示,则该参数应修改为如下的值。
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///dfs/data1,file:///hd2/dfs/data2,file:///hd3/ dfs/data3,file:///hd4/dfs/data4</value>
</property>
项目经验之支持LZO 压缩配置
1. lzo环境的配置
- hadoop 本身并不支持 lzo 压缩,故需要使用 twitter 提供的 hadoop-lzo 开源组件。hadoop-lzo需依赖 hadoop 和 lzo 进行编译;可以在网上找已经编译好了的包;
- 将编译好后的 hadoop-lzo-0.4.20.jar 放入 hadoop-3.1.3/share/hadoop/common/
[root@hadoop102 common]$ pwd
/opt/module/hadoop-3.1.3/share/hadoop/common
[root@hadoop102 common]$ ls
hadoop-lzo-0.4.20.jar
- 同步文件
xsync hadoop-lzo-0.4.20.jar
- 然后在core-site.xml里面新增(上面已经写了):
<configuration>
<property>
<name>io.compression.codecs</name>
<value>
org.apache.hadoop.io.compress.GzipCodec, org.apache.hadoop.io.compress.DefaultCodec, org.apache.hadoop.io.compress.BZip2Codec, org.apache.hadoop.io.compress.SnappyCodec, com.hadoop.compression.lzo.LzoCodec, com.hadoop.compression.lzo.LzopCodec
</value>
</property>
<property>
<name>io.compression.codec.lzo.class</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
</configuration>
- 集群分发
xsync core-site.xml
然后重启集群
2. 项目经验之LZO 创建索引
- 创建 LZO 文件的索引,LZO 压缩文件的可切片特性依赖于其索引,故我们需要手动为LZO 压缩文件创建索引。若无索引,则 LZO 文件的切片只有一个。
hadoop -jar /path/to/your/hadoop-lzo.jar com.hadoop.compression.lzo.DistributedLzoIndexer big_file.lzo
项目经验之Hadoop 参数调优
1. HDFS 参数调优 hdfs-site.xml
The number of Namenode RPC server threads that listen to requests from clients. If dfs.namenode.servicerpc-address is not configured then Namenode RPC server threads listen to requests from all nodes.
NameNode 有一个工作线程池,用来处理不同 DataNode 的并发心跳以及客户端并发的元数据操作。
对 于 大 集 群 或 者 有 大 量 客 户 端 的 集 群 来 说 , 通 常 需 要 增 大 参 数
dfs.namenode.handler.count 的默认值 10。
<property>
<name>dfs.namenode.handler.count</name>
<value>10</value>
</property>
2. YARN 参数调优 yarn-site.xml
(1)情景描述:总共 7 台机器,每天几亿条数据,数据源->Flume->Kafka->HDFS->Hive面临问题:数据统计主要用 HiveSQL,没有数据倾斜,小文件已经做了合并处理,开
启的 JVM 重用,而且 IO 没有阻塞,内存用了不到 50%。但是还是跑的非常慢,而且数据量洪峰过来时,整个集群都会宕掉。基于这种情况有没有优化方案。
(2)解决办法:
内存利用率不够。这个一般是 Yarn 的 2 个配置造成的,单个任务可以申请的最大内存大小,和 Hadoop 单个节点可用内存大小。调节这两个参数能提高系统内存的利用率。
(a)yarn.nodemanager.resource.memory-mb
表示该节点上 YARN 可使用的物理内存总量,默认是 8192(MB),注意,如果你的节点内存资源不够 8GB,则需要调减小这个值,而 YARN 不会智能的探测节点的物理内存总量。
(b)yarn.scheduler.maximum-allocation-mb
单个任务可申请的最多物理内存量,默认是 8192(MB)。
总结
之前之后这些博客多以搭建环境为主(以完成数仓项目为主、或者说数仓的基本环境为主),详细的每个组件的学习,博客中不会写的很详细,但是可以在评论里问我,我会给出资料或者解答;
感谢大家阅、互相学习;
感谢尚硅谷提供的学习资料;
gitee:很多代码仓库;
[email protected]