redis有五种基本数据结构:字符串、hash、set、zset、list。
但是你知道构成这五种结构的底层数据结构是怎样的吗?
SDS是"simple dynamic string"的缩写。
redis中所有场景中出现的字符串,基本都是由SDS来实现的SDS长这样:
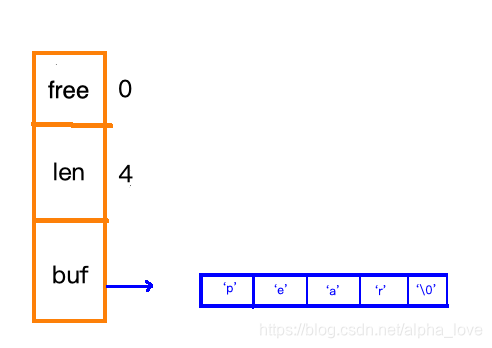
free:还剩多少空间 len:字符串长度 buf:存放的字符数组
空间预分配 ,为减少修改字符串带来的内存重分配次数,sds采用了“一次管够”的策略:

惰性空间释放
为避免缩短字符串时候的内存重分配操作,sds在数据减少时,并不立刻释放空间。
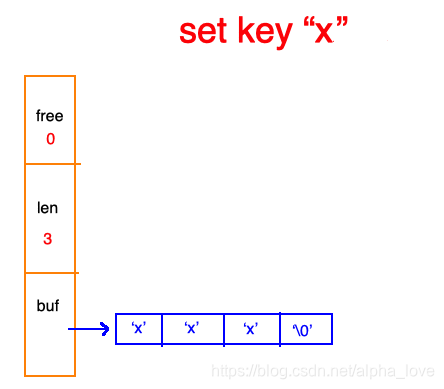
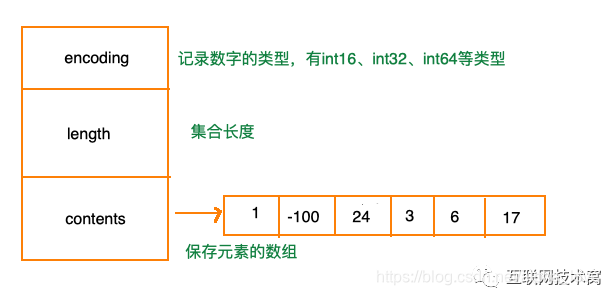
就是redis中存放的各种数字 包括以下这种,故意加引号“”的
长这样:
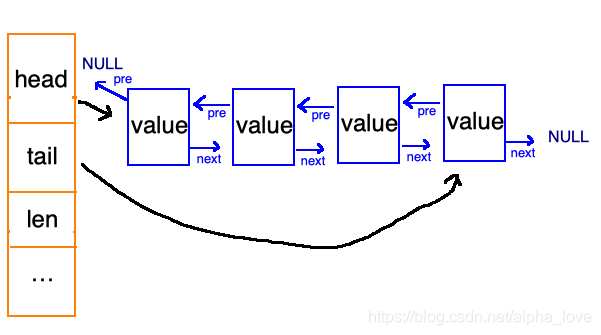
分两部分,一部分是“统筹部分”:橘黄色,一部分是“具体实施方“:蓝色。
主体”统筹部分“:
具体"实施方":一目了然的双向链表结构,有前驱 pre有后继 next
由 list和 listNode两个数据结构构成。
压缩列表。redis的列表键和哈希键的底层实现之一。此数据结构是为了节约内存而开发的。和各种语言的数组类似,它是由连续的内存块组成的,这样一来,由于内存是连续的,就减少了很多内存碎片和指针的内存占用,进而节约了内存。
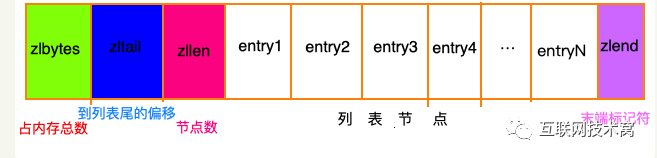
然后文中的 entry的结构是这样的:

元素的遍历
先找到列表尾部元素:
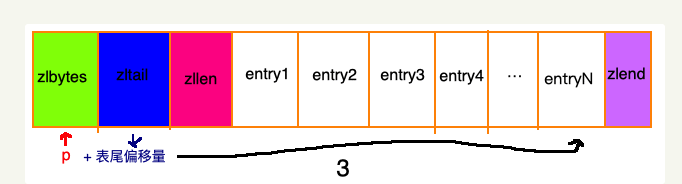
然后再根据ziplist节点元素中的 previous_entry_length属性,来逐个遍历:
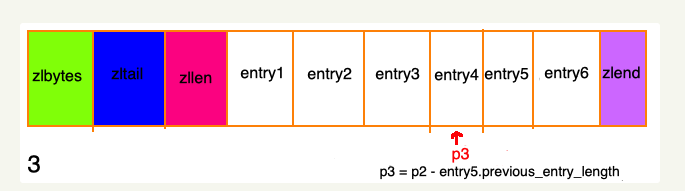
连锁更新
再次看看 entry元素的结构,有一个 previous_entry_length字段,他的长度要么都是1个字节,要么都是5个字节:
假设现在存在一组压缩列表,长度都在250字节至253字节之间,突然新增一新节点 new, 长度大于等于254字节,会出现:
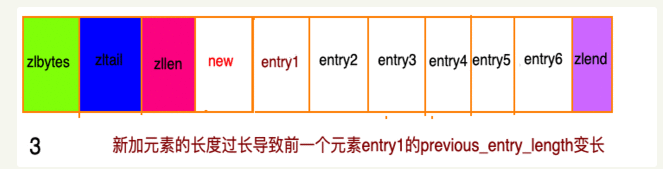
程序需要不断的对压缩列表进行空间重分配工作,直到结束。
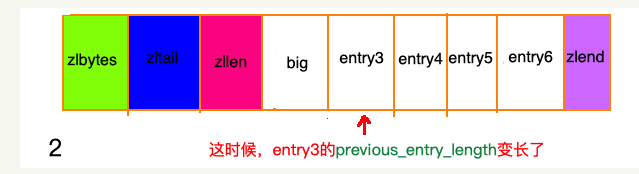
除了增加操作,删除操作也有可能带来“连锁更新”。请看下图,ziplist中所有entry节点的长度都在250字节至253字节之间,big节点长度大于254字节,small节点小于254字节。
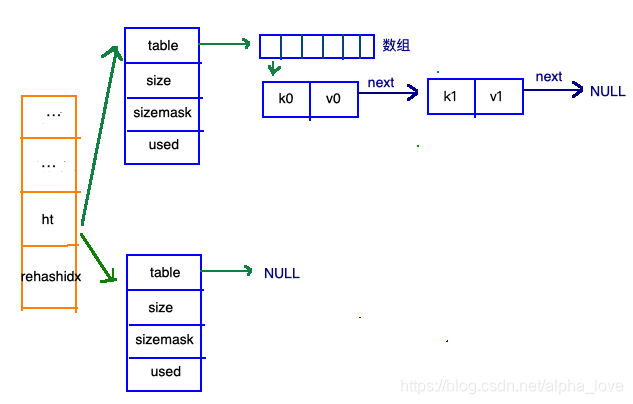
哈希表略微有点复杂。哈希表的制作方法一般有两种,一种是:开放寻址法,一种是 拉链法。redis的哈希表的制作使用的是 拉链法。
整体结构如下图:
也是分为两部分:左边橘黄色部分和右边蓝色部分,同样,也是”统筹“和”实施“的关系。具体哈希表的实现,都是在蓝色部分实现的。先来看看蓝色部分:
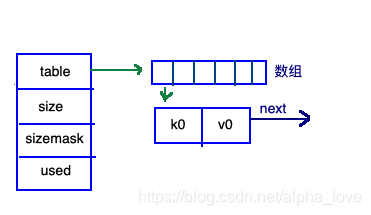
这也分为左右两边“统筹”和“实施”的两部分。
右边部分很容易理解:就是通常拉链表实现的哈希表的样式;数组就是bucket,一般不同的key首先会定位到不同的bucket,若key重复,就用链表把冲突的key串起来。
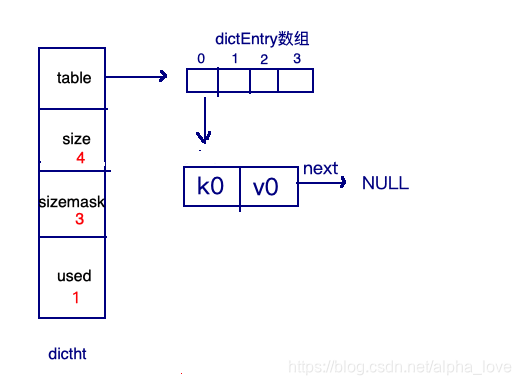
新建key的过程:
假如重复了:
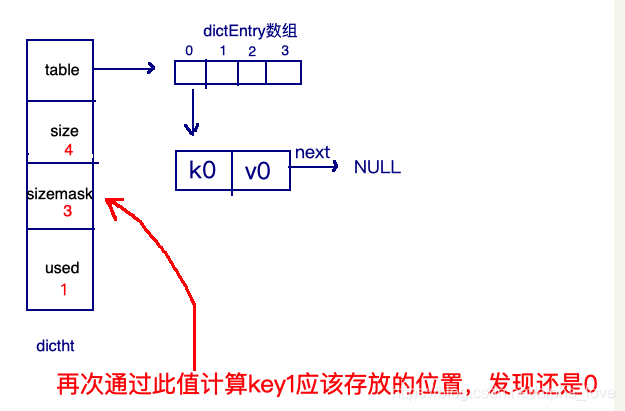
rehash
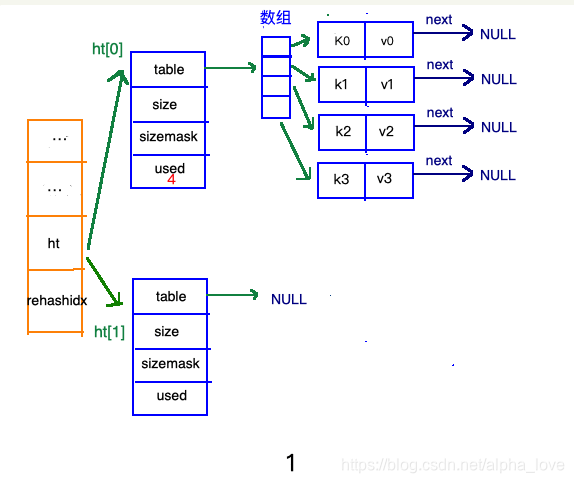
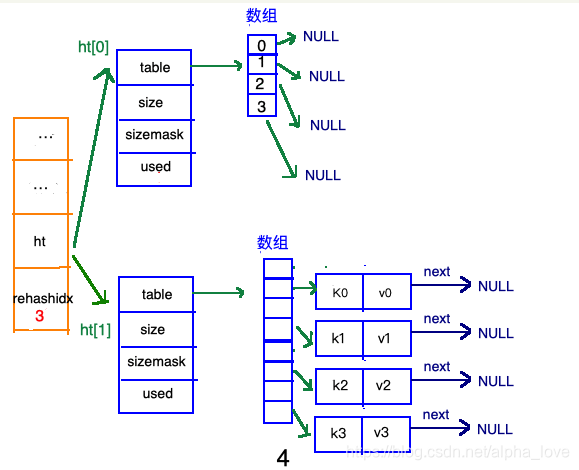
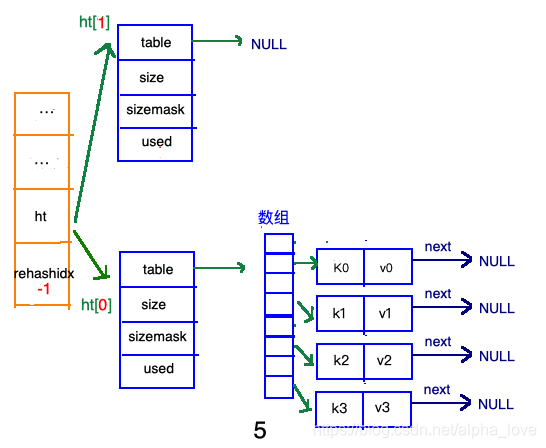
再来看看哈希表总体图中左边橘黄色的“统筹”部分,其中有两个关键的属性:ht和 rehashidx。ht是一个数组,有且只有俩元素ht[0]和ht[1];其中,ht[0]存放的是redis中使用的哈希表,而ht[1]和rehashidx和哈希表的 rehash有关。
rehash指的是重新计算键的哈希值和索引值,然后将键值对重排的过程。
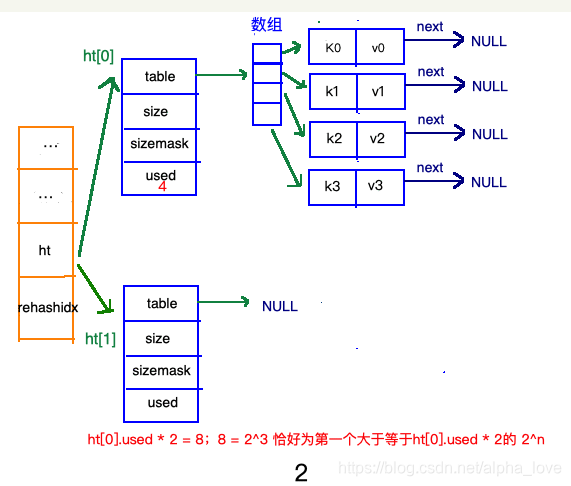
加载因子(load factor)=ht[0].used/ht[0].size。
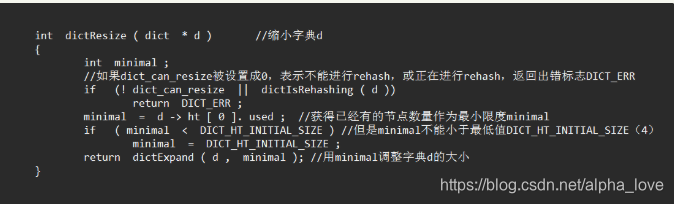
扩容和收缩标准
扩容:
收缩:
扩容和收缩的数量
扩容:
收缩:
(以下部分属于细节分析,可以跳过直接看扩容步骤)对于收缩,我当时陷入了疑虑:收缩标准是 加载因子小于0.1的时候,也就是说假如哈希表中有4个元素的话,哈希表的长度只要大于40,就会进行收缩,假如有一个长度大于40,但是存在的元素为4即( ht[0].used为4)的哈希表,进行收缩,那收缩后的值为多少?
我想了一下:按照前文所讲的内容,应该是4。但是,假如是4,存在和收缩后的长度相等,是不是又该扩容?翻开源码看看:
收缩具体函数:
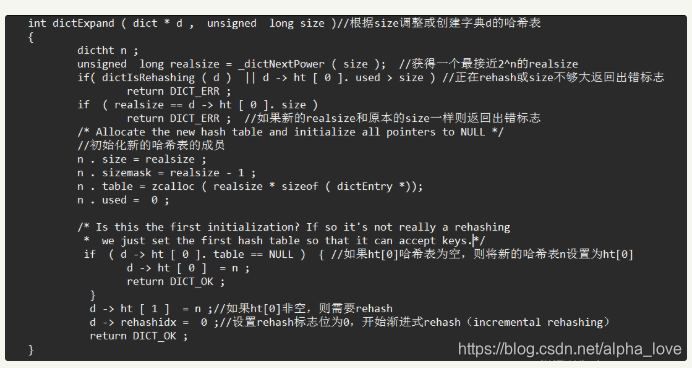
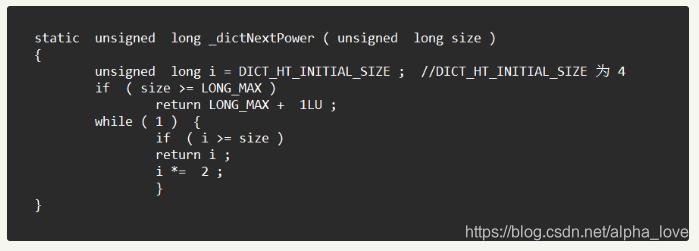
由代码我们可以看到,假如收缩后长度为4,不仅不会收缩,甚至还会报错。()
我们回过头来再看看设定:题目可能成立吗?哈希表的扩容都是2倍增长的,最小是4, 4 ===》 8 ====》 16 =====》 32 ======》 64 ====》 128
也就是说:不存在长度为 40多的情况,只能是64。但是如果是64的话,64 X 0.1(收缩界限)= 6.4 ,也就是说在减少到6的时候,哈希表就会收缩,会缩小到多少呢?是8。此时,再继续减少到4,也不会再收缩了。所以,根本不存在一个长度大于40,但是存在的元素为4的哈希表的。
扩容步骤
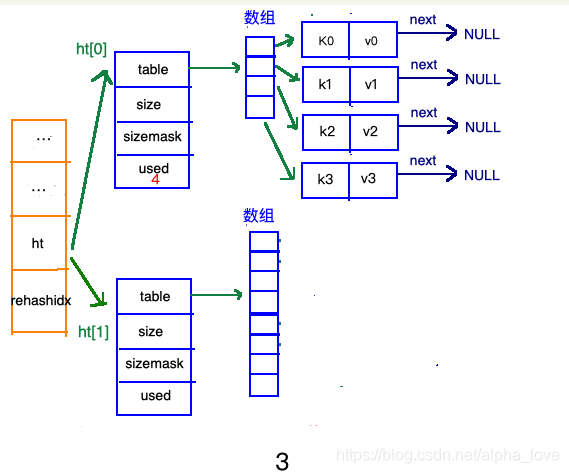
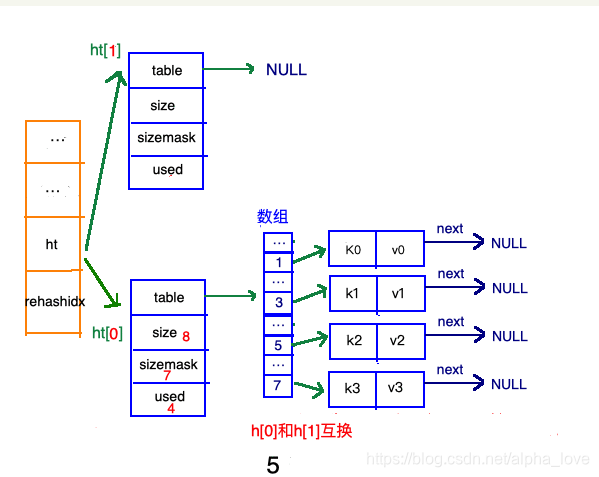
收缩步骤
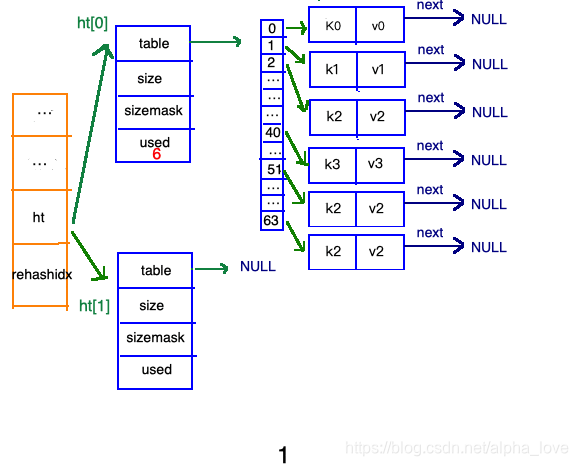
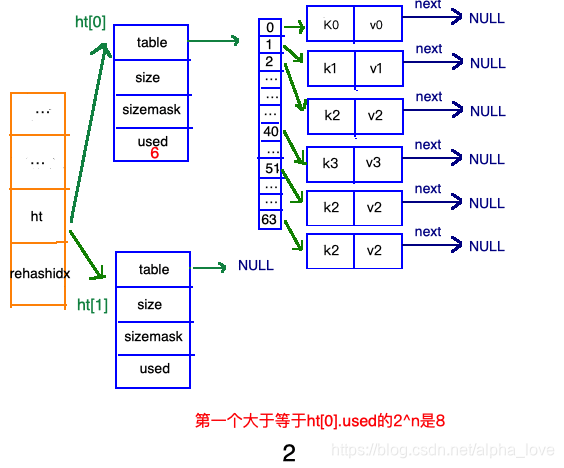
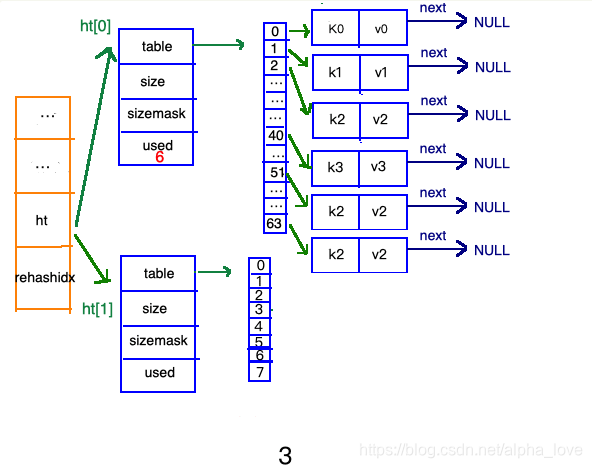
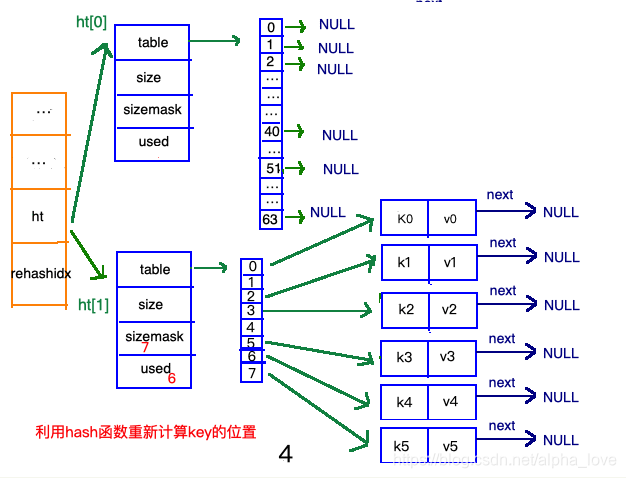
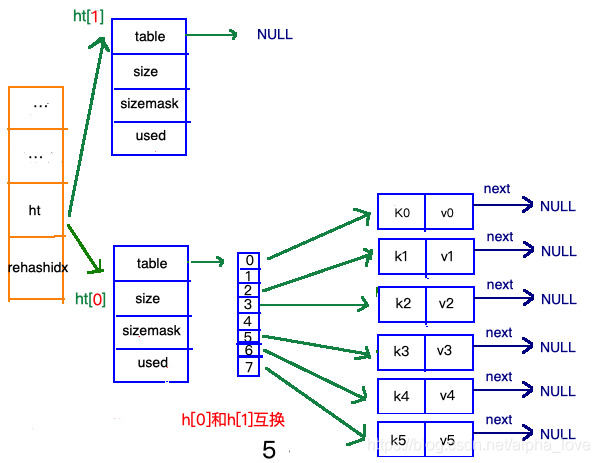
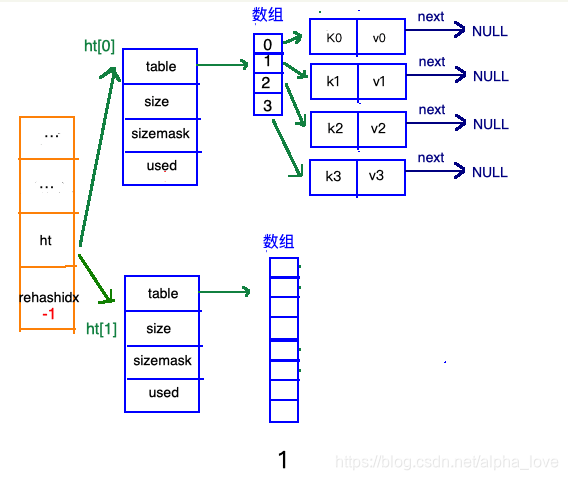
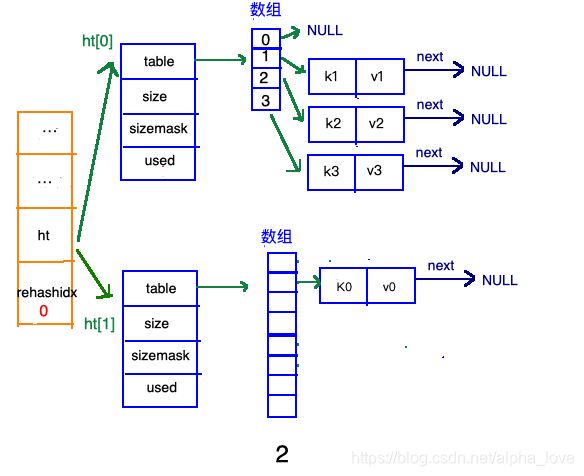
渐进式refresh
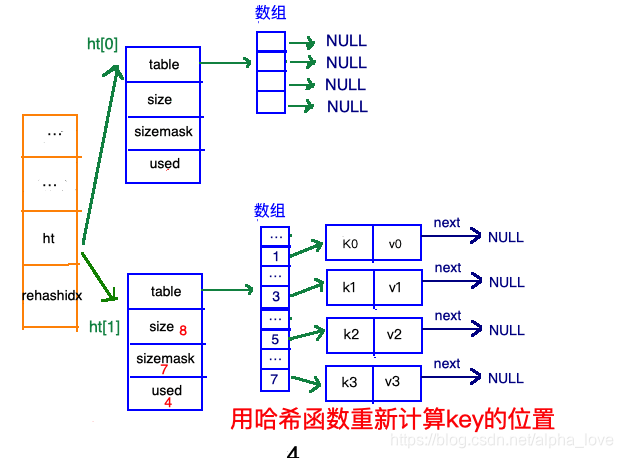
在"扩容步骤"和"收缩步骤" 两幅动图中每幅图的第四步骤“将ht[0]中的数据利用哈希函数重新计算,rehash到ht[1]”,并不是一步完成的,而是分成N多步,循序渐进的完成的。因为hash中有可能存放几千万甚至上亿个key,毕竟Redis中每个hash中可以存 2^32-1 键值对(40多亿),假如一次性将这些键值rehash的话,可能会导致服务器在一段时间内停止服务,毕竟哈希函数就得计算一阵子呢((#.#))。
哈希表的refresh是分多次、渐进式进行的。
渐进式refresh和下图中左边橘黄色的“统筹”部分中的 rehashidx密切相关:

甚至在进行期间,每次对哈希表的增删改查操作,除了正常执行之外,还会顺带将ht[0]哈希表相关键值对rehash到ht[1]。
以扩容步骤为例:

整数集合是集合键的底层实现方式之一。
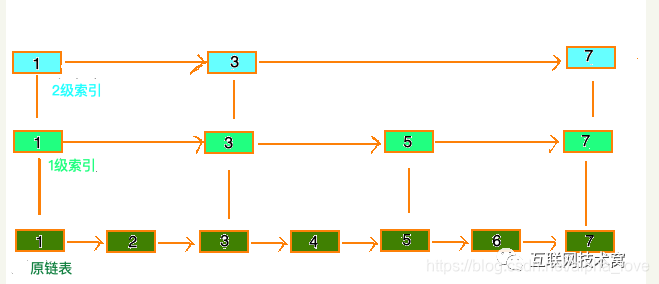
跳表这种数据结构长这样:
redis中把跳表抽象成如下所示:
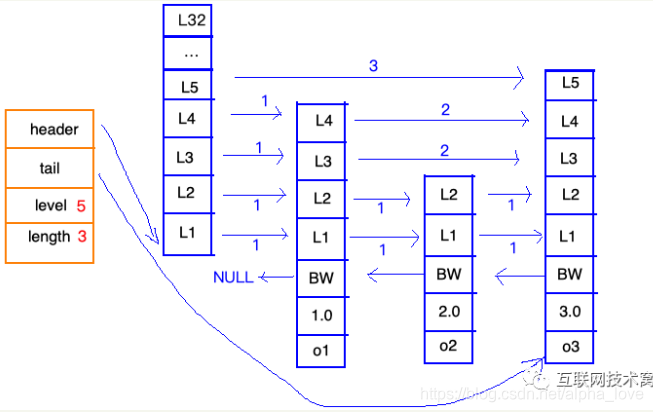
看这个图,左边“统筹”,右边实现。统筹部分有以下几点说明:
实现部分有以下几点说明:
redis对象
redis中并没有直接使用以上所说的各种数据结构来实现键值数据库,而是基于一种对象,对象底层再间接的引用上文所说的具体的数据结构。
结构如下图:

字符串
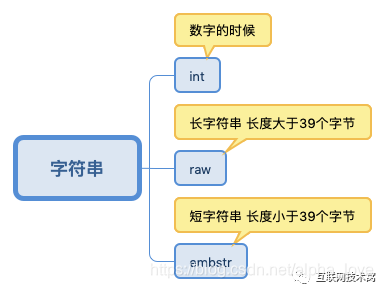
其中:embstr和raw都是由SDS动态字符串构成的。唯一区别是:raw是分配内存的时候,redisobject和 sds 各分配一块内存,而embstr是redisobject和raw在一块儿内存中。
列表
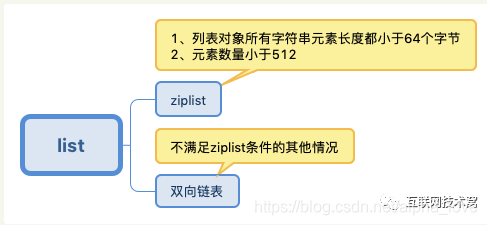
hash
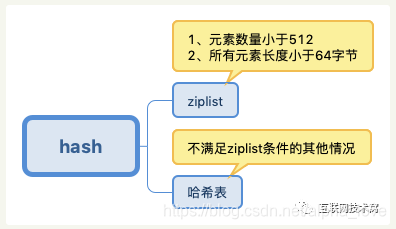
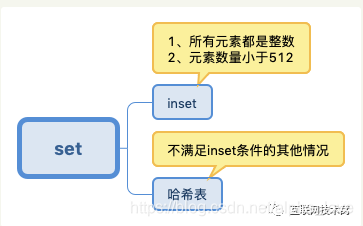
set
zset

1.参考资料
https://www.toutiao.com/i6766770175002804748/?tt_from=mobile_qq&utm_campaign=client_share×tamp=1615302317&app=news_article&utm_source=mobile_qq&utm_medium=toutiao_android&use_new_style=1&req_id=202103092305160101512090911B10B1FC&share_token=37214076-1a89-45fd-b09d-75ab4b3ed90f&group_id=6766770175002804748