一、页面分析
今天就说一些开场白了,直接进入主题。
首先,打开目标网址:网址传送门
(未成年人禁止入内嗷(手动滑稽))

结构和贴吧差不多呀,肯定要分两步。
第一步:通过主详情页,拿到各个子详情页的链接。

右击 页面进行检查,发现了每个子页面对应的article节点,点开一个article节点进行观察,很容易发现,里面有一个跳转链接。

目标一,get!
第二步,拿到每个图片的下载链接。
右击检查,也很容易发现,它们的下载链接,但同时也发现了,“干扰项”
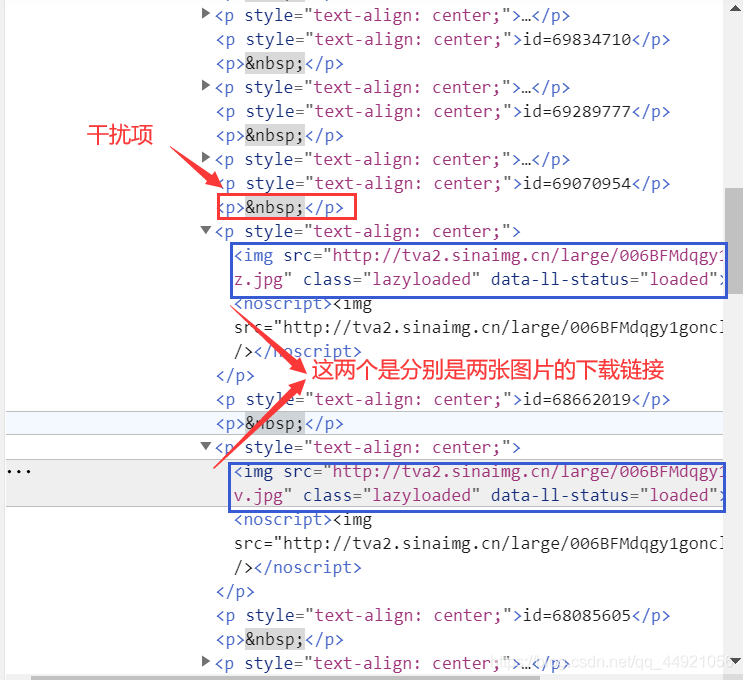
在获取链接的时候,首先要找到p节点,但是,p节点存在同名的干扰项,这时候就需要使用一些手法进行处理了。具体看代码。
二、完整代码
# -*- coding: UTF-8 -*-
"""
@Author :远方的星
@Time : 2021/3/20 7:44
@CSDN :https://blog.csdn.net/qq_44921056
@腾讯云 : https://cloud.tencent.com/developer/column/91164
"""
from fake_useragent import UserAgent
import requests
from lxml import etree
import bs4
import os
# 创建一个文件夹来报预保存图片
if not os.path.exists('D:/Animex动漫社'):
os.mkdir('D:/Animex动漫社')
# 创建随机请求头
ua = UserAgent(verify_ssl=False, path='fake_useragent.json')
# 用户输入爬取的页数
page = input('请输入想要爬取的页数')
page = int(page) + 1
# 使用for循环进行多页爬取
for i in range(1, page):
url = 'http://www.animetox.com/category/pic/pixiv/page/{}'.format(i)
# 获取页面内容
response_1 = requests.get(url).text
html = etree.HTML(response_1)
image_urls = html.xpath('//*[@id="main-contents"]/section[2]/div/div/article') # 找到各个article节点
for j in range(len(image_urls)):
# 提取每一组的图片的访问链接
image_url = image_urls[j].xpath('./a/@href')[0]
# 获取页面内容
response_2 = requests.get(image_url).text
html = response_2
soup = bs4.BeautifulSoup(html, 'html.parser')
# 获取指定的节点,排除掉p节点的干扰项
image_src_s = soup.select('.cps-post-main-box div p[style="text-align: center;"]')
# 定义num方便图片命名
num = 1
for k in range(len(image_src_s)):
# 获取指定节点下的节点
image_src = image_src_s[k].select('img')
# 即使排除了干扰项,但可能存在满足条件,但内容为空的情况,于是使用条件循环进行筛选
if image_src == []:
continue
else:
image_src = image_src[0]
# 获取图片链接
image_src = image_src.get('data-lazy-src')
# 得到图片内容
image_data = requests.get(image_src).content
# 图片名字
image_name = '{}_{}_{}.jpg'.format(i, j+1, num)
# 图片保存小路径名字
path_name = '{}_{}'.format(i, j+1)
# 大路径名字
path = 'D:/Animex动漫社/' + path_name
if not os.path.exists(path):
os.mkdir(path)
# 图片的保存路径
image_path = path + '/' + image_name
num += 1
# 保存文件
with open(image_path, 'wb') as f:
f.write(image_data)
print(image_name, '下载成功!')
f.close()
三、结果展示



图片名字含义:num1_num2_num3分别代表,主页面第几页_页面中第几个子页面_子页面中第几张图片。
四、Blogger’s speech
学废了咩,还不赶紧尝试尝试!
如有不足,还请大佬评论区留言或私信我,我会进行补充。
感谢您的支持,希望可以点赞,关注,收藏,一键三连哟。
作者:远方的星
CSDN:https://blog.csdn.net/qq_44921056
腾讯云:https://cloud.tencent.com/developer/column/91164
本文仅用于交流学习,未经作者允许,禁止转载,更勿做其他用途,违者必究。