一、页面分析
今天就说一些开场白了,直接进入主题。
首先,打开目标网址:P站
(未成年人禁止入内嗷(手动滑稽))
结构和贴吧差不多呀,肯定要分两步。
第一步:通过主详情页,拿到各个子详情页的链接。

右击 页面进行检查,发现了每个子页面对应的article节点,点开一个article节点进行观察,很容易发现,里面有一个跳转链接。
目标一,get!
第二步,拿到每个图片的下载链接。
右击检查,也很容易发现,它们的下载链接,但同时也发现了,“干扰项”

在获取链接的时候,首先要找到p节点,但是,p节点存在同名的干扰项,这时候就需要使用一些手法进行处理了。具体看代码。
二、完整代码
在这里还是要推荐下我自己建的Python学习群:705933274,群里都是学Python的,如果你想学或者正在学习Python ,欢迎你加入,大家都是软件开发党,不定期分享干货(只有Python软件开发相关的),包括我自己整理的一份2021最新的Python进阶资料和零基础教学,欢迎进阶中和对Python感兴趣的小伙伴加入!
三、结果展示
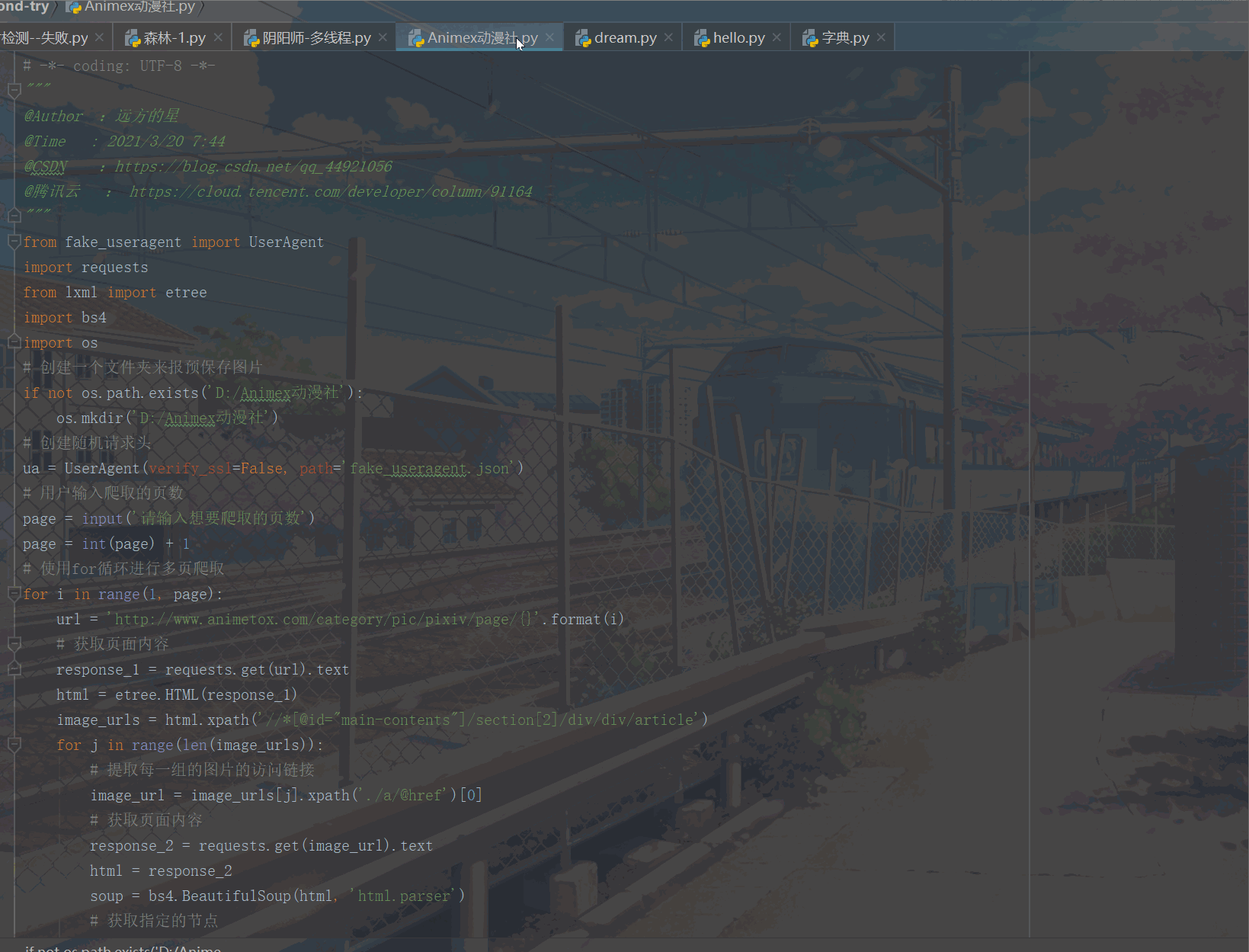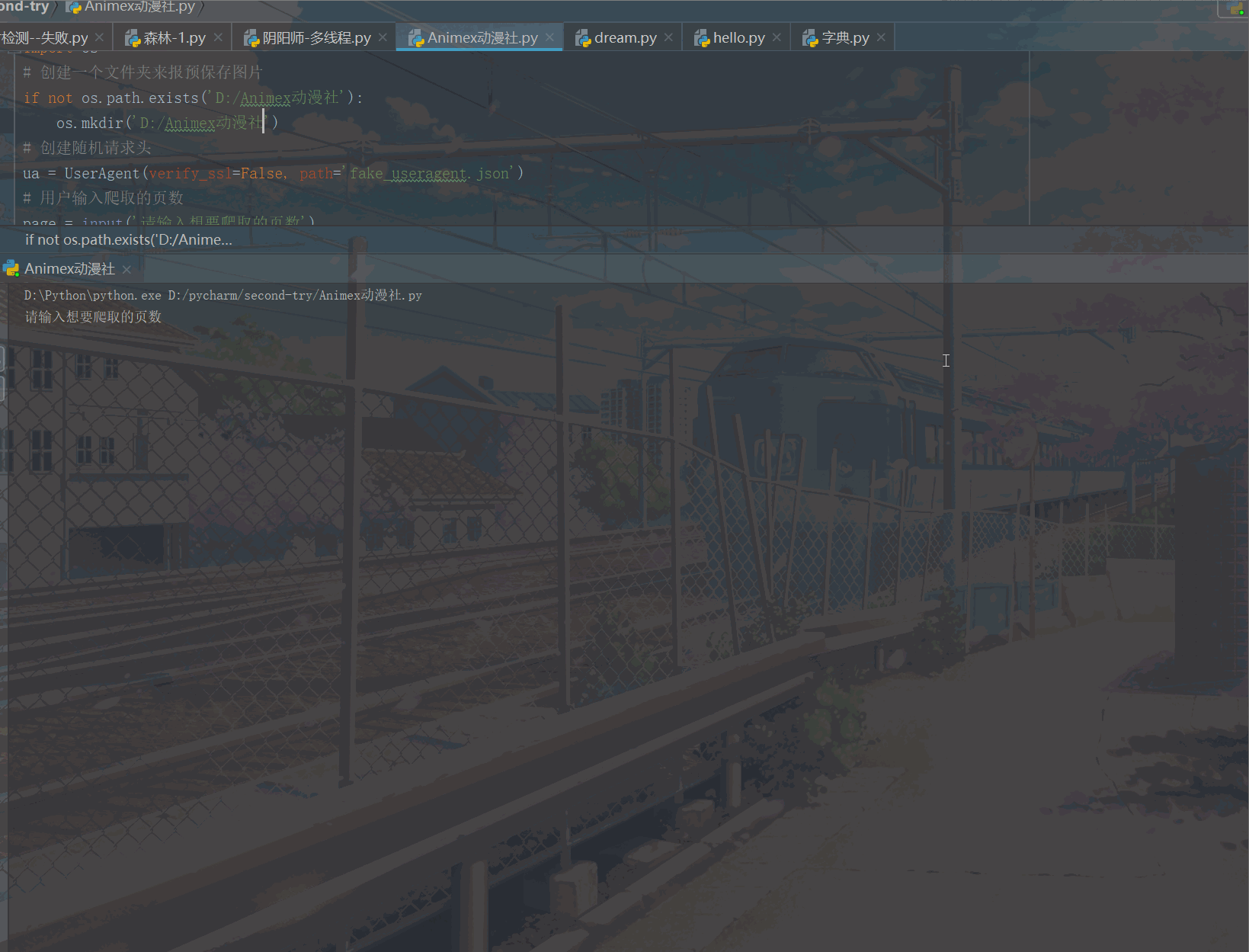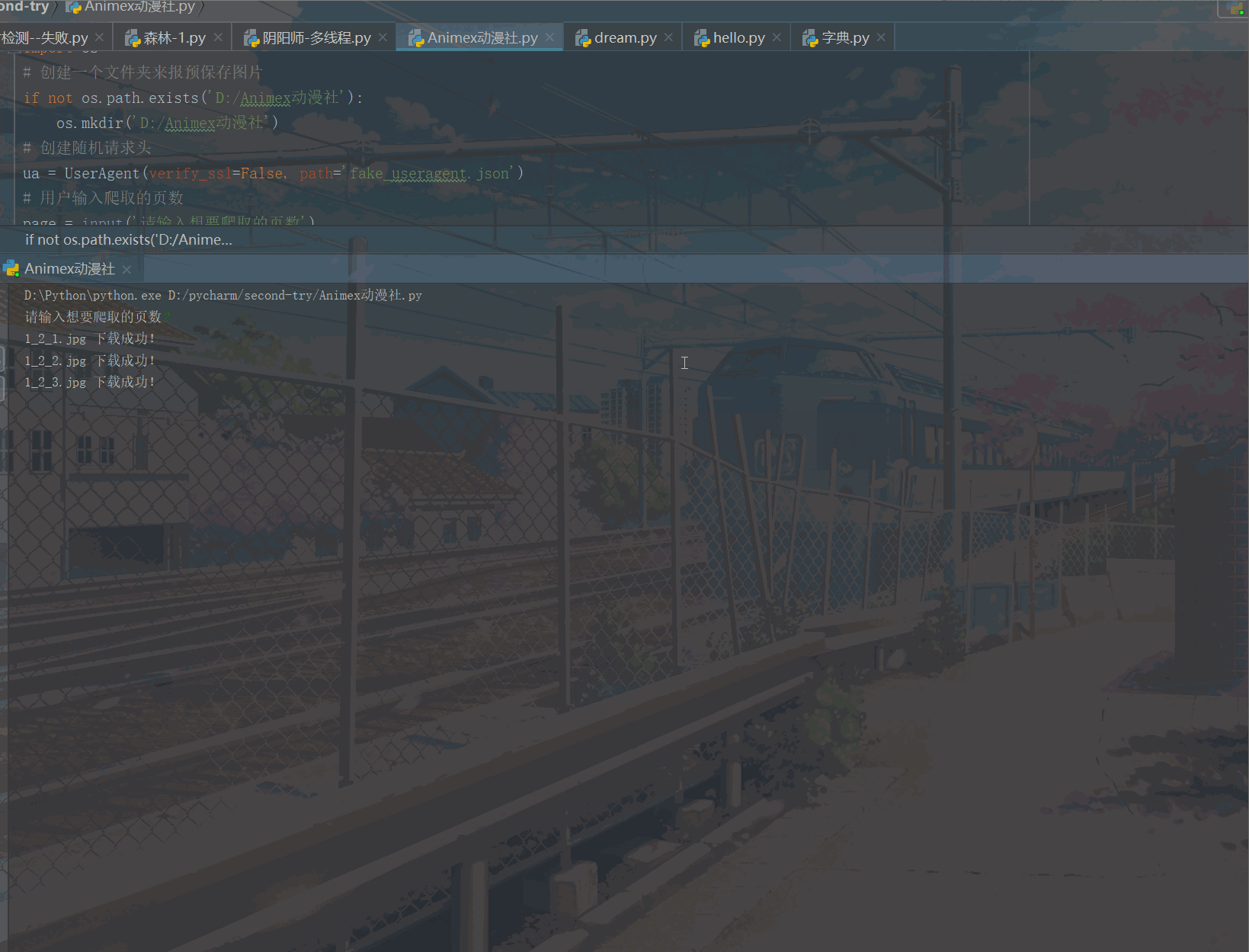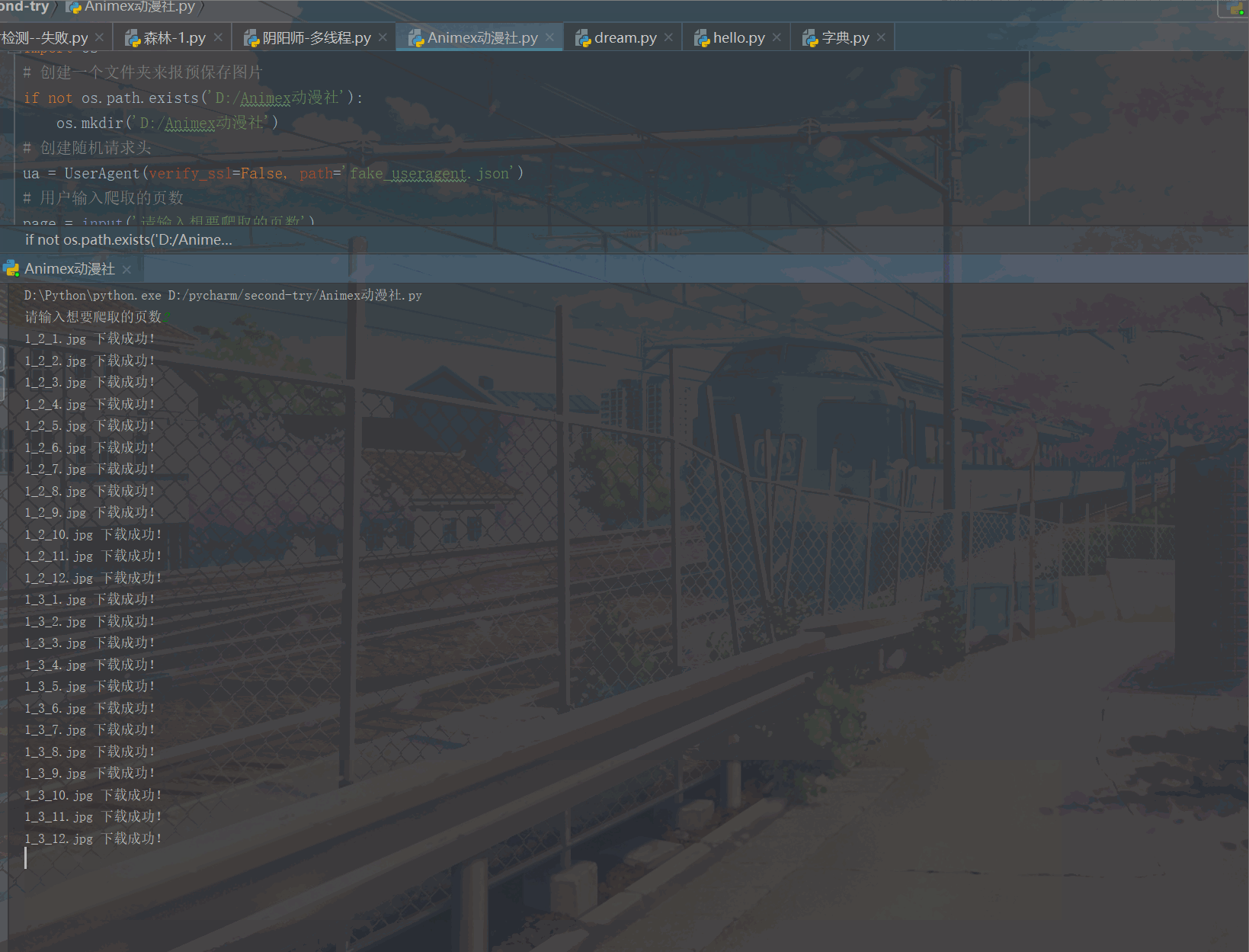


图片名字含义:num1_num2_num3分别代表,主页面第几页_页面中第几个子页面_子页面中第几张图片。
四、Blogger’s speech
学废了咩,还不赶紧尝试尝试!
如有不足,还请大佬在评论区留言或私信我,我会进行补充。
感谢您的支持,希望您可以点赞,关注,收藏,一键三连哟。