
【Python笔记】NumPy数组
【DA】数据可视化matplotlib
【Python笔记】pandas常用函数图码总结
SciPy的统计模块是scipy.stats,其中有一个类是连续分布的实现,一个类是离散分布的实现。此外,该模块中还有很多用于统计检验的函数。
# 导入包
from scipy import stats
import matplotlib.pyplot as plt
# 1.使用`scipy.stats`包按正态分布生成随机数
generated = stats.norm.rvs(size=900)
# 2.用正态分布去拟合生成的数据,得到其均值和标准差
print("Mean", "Std", stats.norm.fit(generated))
# Mean Std (-0.027757190138192445, 0.9967355589828278)
# 3.偏度(skewness)描述的是概率分布的偏斜(非对称)程度。我们来做一个偏度检验。
# 该检验有两个返回值,其中第二个返回值为p-value,即观察到的数据集服从正态分布的概率,取值范围为0~1。
print("Skewtest", "pvalue", stats.skewtest(generated))
# Skewtest pvalue SkewtestResult(statistic=-0.4227102833216121, pvalue=0.6725066519280437)
# 因此,该数据集有67%的概率服从正态分布。
# 4.峰度(kurtosis)描述的是概率分布曲线的陡峭程度。我们来做一个峰度检验。该检验与
# 偏度检验类似,当然这里是针对峰度。
print("Kurtosistest", "pvalue", stats.kurtosistest(generated))
# Kurtosistest pvalue KurtosistestResult(statistic=0.6422156432448409, pvalue=0.5207331773445296)
# 5.正态性检验(normality test)可以检查数据集服从正态分布的程度。我们来做一个正态性
# 检验。该检验同样有两个返回值,其中第二个返回值为p-value。
print("Normaltest", "pvalue", stats.normaltest(generated))
# Normaltest pvalue NormaltestResult(statistic=0.5911249160542223, pvalue=0.7441129374456706)
# 6.使用SciPy我们可以很方便地得到数据所在的区段中某一百分比处的数值
print("95 percentile", stats.scoreatpercentile(generated, 95)) # 95 percentile 1.6419459784929902
# 7.将前一步反过来,我们也可以从数值1出发找到对应的百分比
print("Percentile at 1", stats.percentileofscore(generated, 1)) # Percentile at 1 84.44444444444444
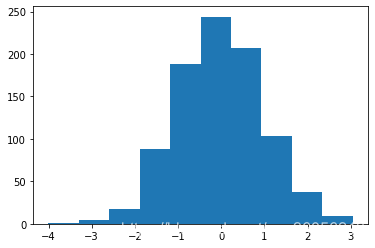
# 8.使用Matplotlib绘制生成数据的分布直方图。
plt.hist(generated)
plt.show()
我们经常会遇到两组数据样本,它们可能来自不同的实验,但互相有一些关联。统计检验可以进行样本比对。scipy.stats模块中已经实现了部分统计检验。
另一种笔者喜欢的统计检验是scikits.statsmodels.stattools中的Jarque-Bera正态性检验。SciKits是Python的小型实验工具包,它并不是SciPy的一部分。此外还有pandas, 它是scikits.statsmodels 的分支。