RoBERTa模型详解和实践
Robustly optimized BERT approach.
内容介绍:
- RoBERTa改进思路和原文详解
- bert4keras工具使用
- 基于RoBERTa的2020语言与智能技术竞赛-阅读理解任务实战
代码:基于RoBERTa的2020语言与智能技术竞赛-阅读理解任务实战(Colab)
工具:bert4keras
论文:https://arxiv.org/pdf/1907.11692.pdf
CLUE阅读理解排行榜:https://www.cluebenchmarks.com/rc.html
1. 介绍
文章由Facebook和华盛顿大学于2019年7月发表,发表于arxiv。 文章简介:BERT 模型在各个自然语言处理任务中展现出 SOTA 的效果,文章在 BERT模型的基础上提出了 BERT 模型的改进版 RoBERTa,使其获得了更好的自然语言任务处理 效果,并在 GLUE,SQuAD,RACE 三个榜上取得最好的SOTA。
2. 文章贡献:
- 提出了一套重要的 BERT 设计选择和训练策略,并引入了能够提高下游任务性能的备选方案;
- 使用一个新的数据集CCNEWS,并确认使用更多的数据进行预训练可以进一步提高下游任务的性能;
- 本文的训练改进表明,在正确的设计选择下,预训练的 masked language model 与其 他所有最近发表的方法相比都更具有竞争力。 同时发布了在 PyTorch 中实现的模型、预训 练和微调代码。
3. 模型细节
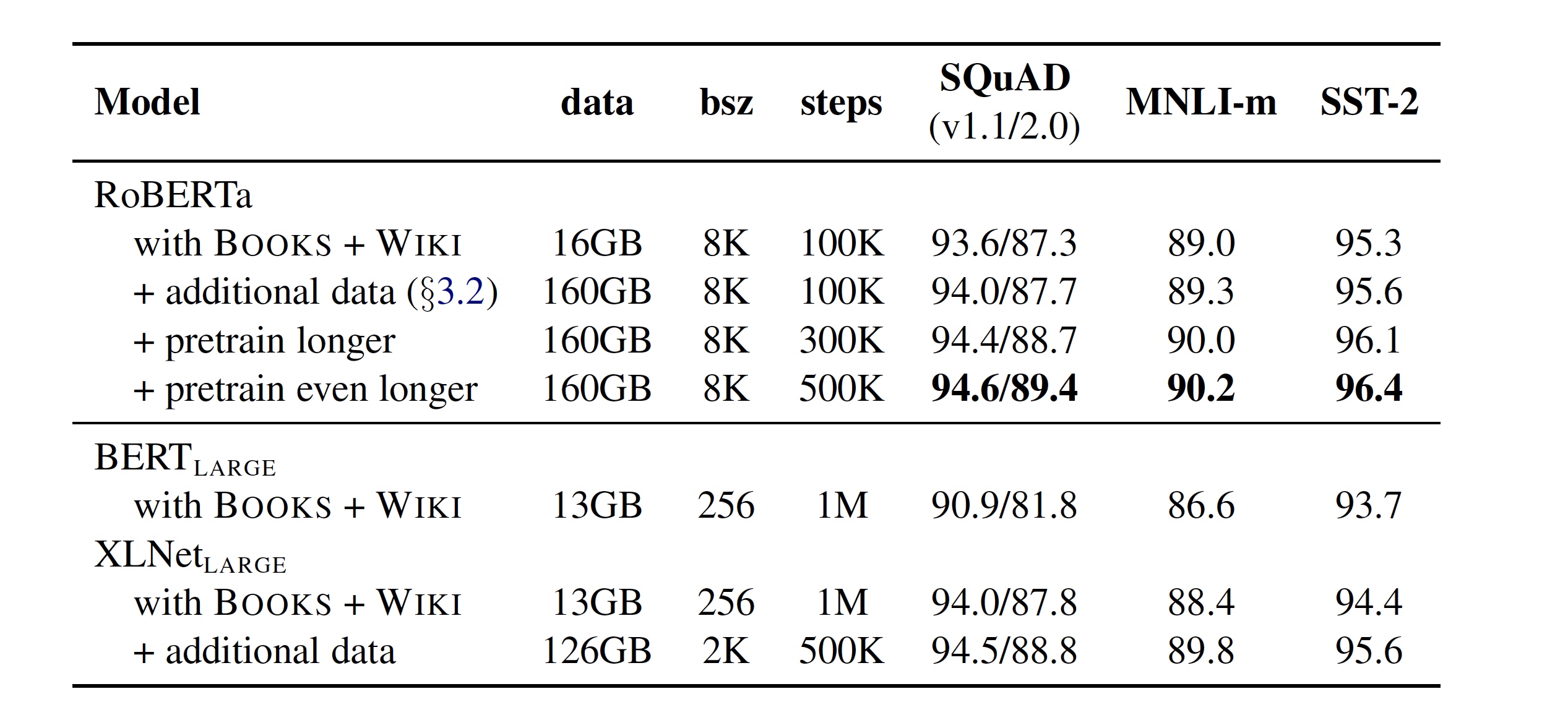
3.1 更多数据(More Data)
文章基于 BERT 提出了一种效果更好的预训练模型训练方式,其主要的区别如下: 训练数据上,RoBERTa 采用了 160G 的训练文本,而 BERT 仅使用 16G 的训练文本, 其中包括:
- Books Corpus + English Wikipedia (16GB):BERT原文使用的之数据
- CC-News(76GB): 自 CommonCrawl News 数据中筛选后得到数据,约含6300万篇新闻,2016年9月-2019年2月。
- OpenWebText(38GB):该数据是借鉴GPT2,从Reddit论坛中获取,karma取点赞数大于3的内容。
- Storie(31GB):同样从CommonCrawl获取,属于故事类数据,而非新闻类。
XLNet:
- BooksCorpus + English Wikipedia (13GB)
- Giga5 (16GB)
- ClueWeb 2012B (19GB)
- Common Crawl (78GB)
数据量更大,RoBERTa有160+GB,而 XLNet却只有126GB。
3.2 更多训练(More Steps)
最多达 500 K 500K 500K步
3.3 更大批次(Large Batch)
批量(batch),常规设置128,256等等便可,如 BERT则是256,RoBERTa 在训练过程中使用了更大的批数量。研究人员尝试过从 256 到 8000 不等的批数量。

3.4 Adam优化
Adam借鉴了Kingma等人的改进,使用 β 1 = 0.9 \beta_{1}=0.9 β1=0.9、 β 2 = 0.999 \beta_{2}=0.999 β2=0.999、 ϵ = 1 e − 6 \epsilon=1 \mathrm{e}-6 ϵ=1e−6 并且 L 2 L_2 L2的衰减权重设置为0.01,在前 10000 steps 是warmed up学习率是 1 e − 4 1e-4 1e−4,并且是线性的衰减。
所有层和Attention权重的dropout=0.1,预训练模型训练1,000,000 steps,最小batch 256 最大batch 512
此操作类似于Transformer训练时候的学习率变化,下图是训练时候的优化器代码。
3.5 Next Sentence Prediction
Next Sentence Prediction (NSP)
数据生成方式和任务改进:取消下一个句子预测,并且数据连续从一个文档中获得

作者进行了多组实验:
- 真实句子对 + NSP
- 成对句子段 + NSP ( BERT )
- 连续长句拼接,句子可跨文档 (无NSP)
- 同上,句子不可跨文档 (无 NSP)
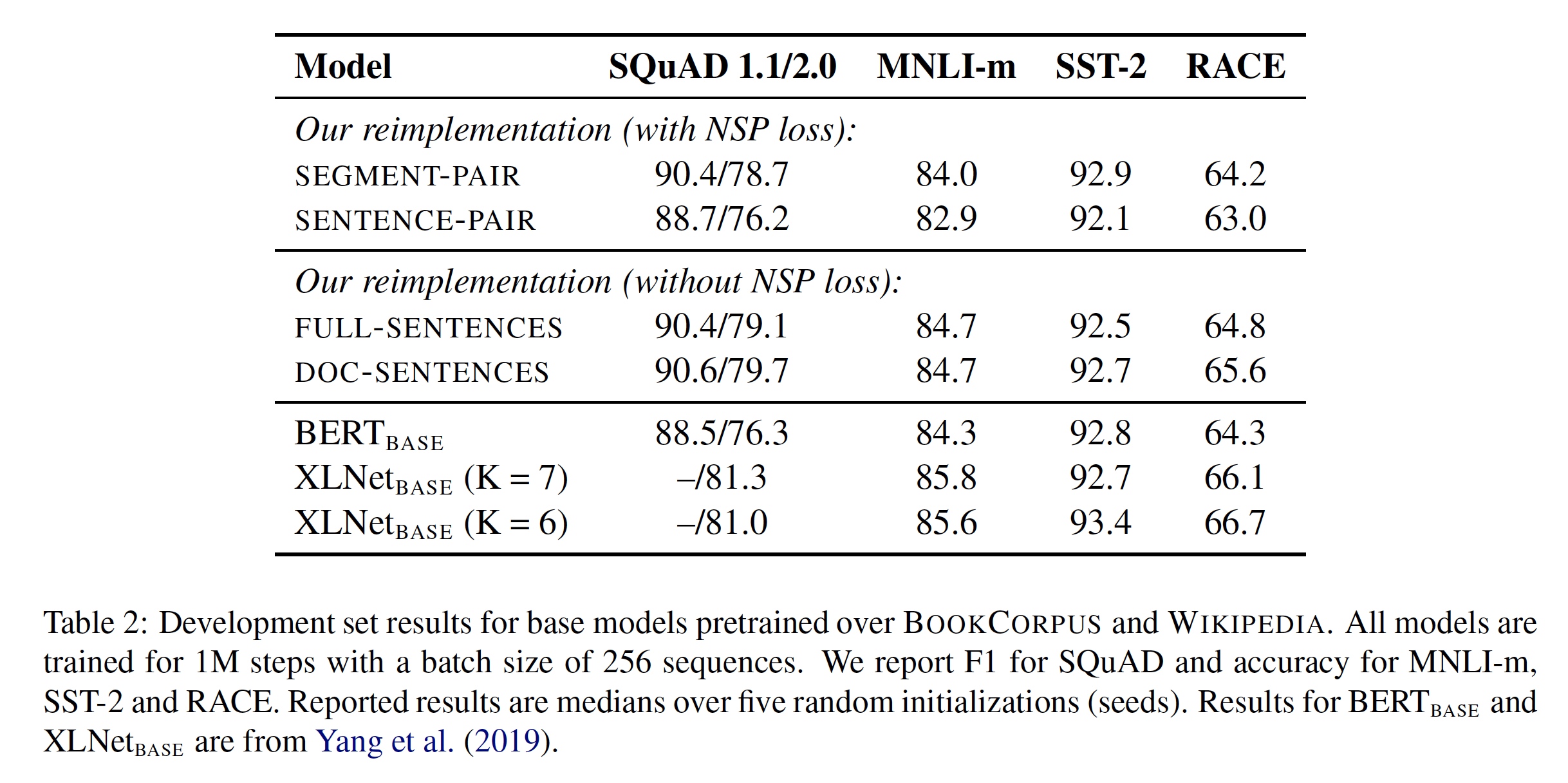
总体效果就是 1<2<3<4
- 真实句子过短,不如拼接成句子段
- 无NSP任务,略好过有NSP
- 不跨文档好过跨文档
3.6 Text Encoding
Byte-Pair Encoding(BPE)是字符级和词级别表征的混合,支持处理自然语言语料库中的众多常见词汇。
原版的 BERT 实现使用字符级别的 BPE 词汇,大小为30K,是在利用启发式分词规则对输入进行预处理之后学得的。Facebook 研究者没有采用这种方式,而是考虑用更大的byte级别BPE词汇表来训练BERT。roberta使用unicode的bytes进行编码,用于学习高频字节的组合,添加到原有词表中。词表总50M大小,比 b e r t b a s e bert_{base} bertbase增加了15M, B e r t l a r g e Bert_{large} Bertlarge增加了20M。且没有对输入作任何额外的预处理或分词。
因为Unicode其实不是一种编码, 而是定义了一个表, 表中为世界上每种语言中的每个字符设定了统一并且唯一的码位 (code point),以满足跨语言、跨平台进行文本转换的要求。在表示一个Unicode的字符时,通常会用“U+”然后紧接着一组十六进制的数字来表示这一个字符
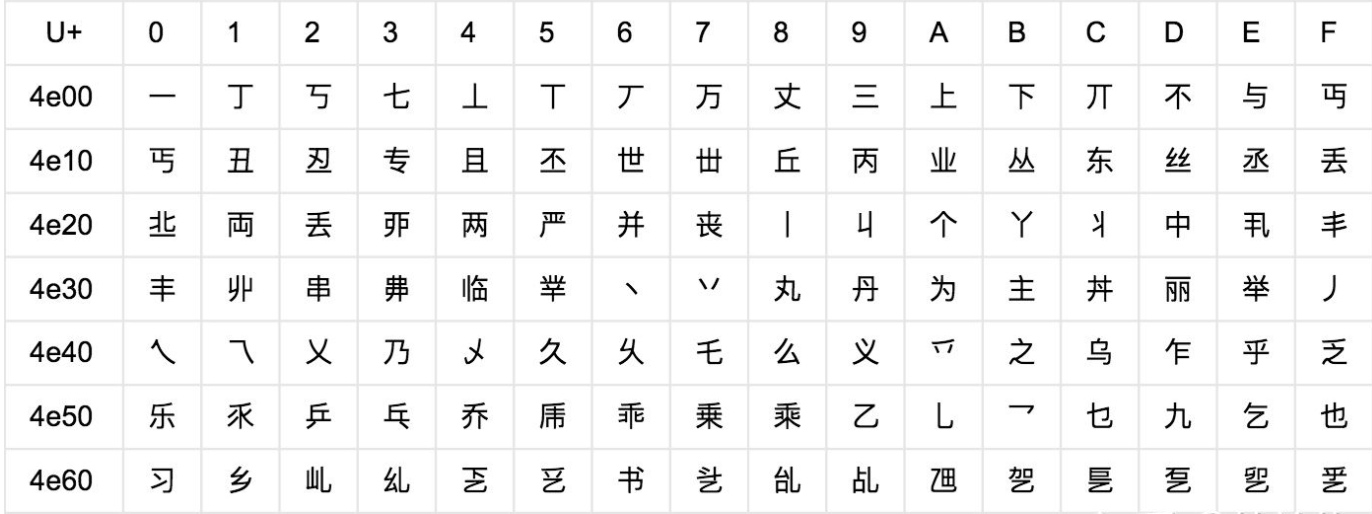

详情可以阅读unicode编码简介
3.7 Masking
3.7.1 全词Masking(Whole Word Masking)
Whole Word Masking (wwm),暂翻译为全词Mask或整词Mask,是谷歌在2019年5月31日发布的一项BERT的升级版本,主要更改了原预训练阶段的训练样本生成策略。
简单来说,原有基于WordPiece的分词方式会把一个完整的词切分成若干个子词,在生成训练样本时,这些被分开的子词会随机被mask。
在全词Mask中,如果一个完整的词的部分WordPiece子词被mask,则同属该词的其他部分也会被mask,即全词Mask。
需要注意的是,这里的mask指的是广义的mask(替换成[MASK];保持原词汇;随机替换成另外一个词),并非只局限于单词替换成[MASK]标签的情况。
更详细的说明及样例请参考:#4
同理,由于谷歌官方发布的BERT-base, Chinese中,中文是以字为粒度进行切分,没有考虑到传统NLP中的中文分词(CWS)。
我们将全词Mask的方法应用在了中文中,使用了中文维基百科(包括简体和繁体)进行训练,并且使用了哈工大LTP作为分词工具,即对组成同一个词的汉字全部进行Mask。
下述文本展示了全词Mask的生成样例。
注意:为了方便理解,下述例子中只考虑替换成[MASK]标签的情况。

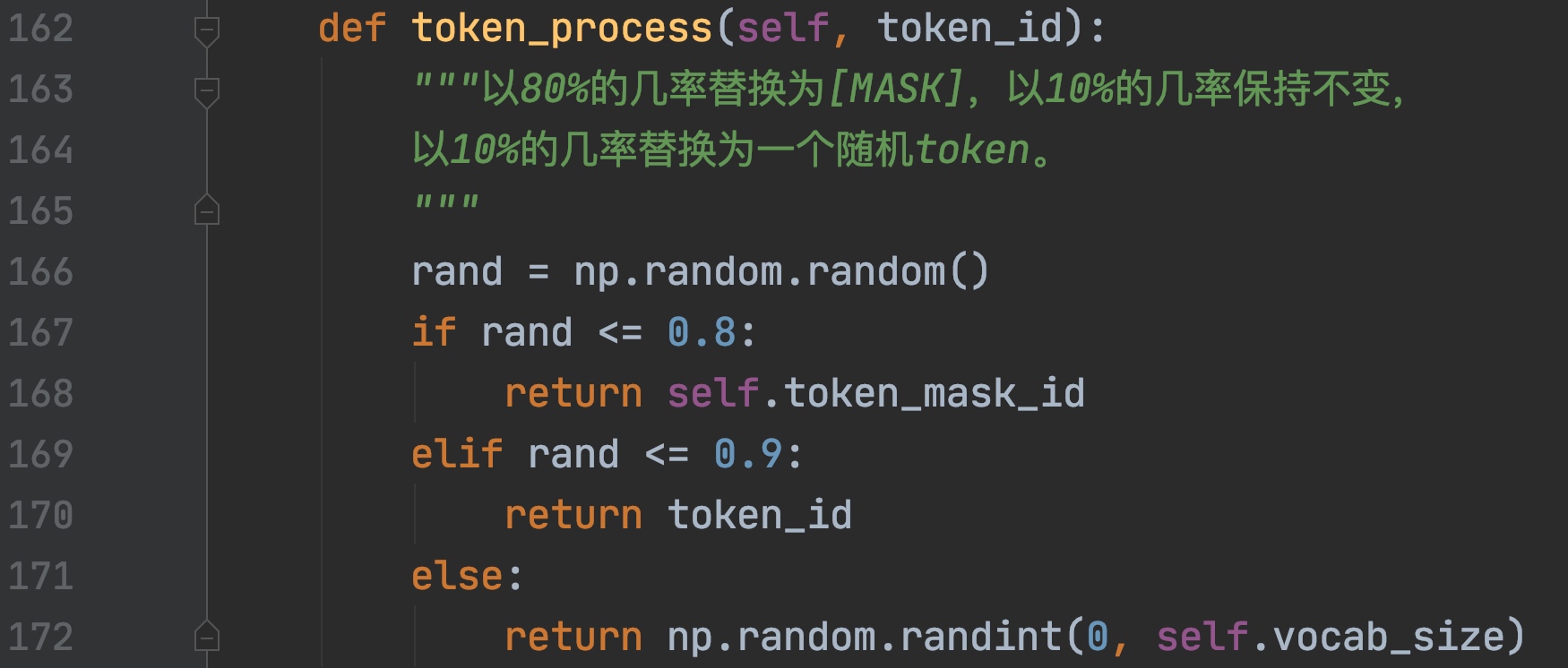
3.7.2 动态 Mask(dynamic masking)
听起来似乎很是厉害,然而却只是一个很简单改进。
BERT依赖随机掩码和预测token。原版的BERT实现在数据预处理期间执行一次掩码,得到一个静态掩码。而RoBERTa使用了动态掩码:每次向模型输入一个序列时都会生成新的掩码模式。这样,在大量数据不断输入的过程中,模型会逐渐适应不同的掩码策略,学习不同的语言表征。
4. 模型评估
模型主要基于三个基准来评估:
- GLUE 通用语言理解评估(GLUE)
- SQuAD 斯坦福问题答疑数据集(SQuAD)
- RACE 考试的重新理解(RACE)
4.1 训练时间
GPU(原文)
L = 24 L=24 L=24, H = 1024 H=1024 H=1024,参数 A = 16 , 355 M A=16, 355M A=16,355M, 100 K 100K 100K Steps
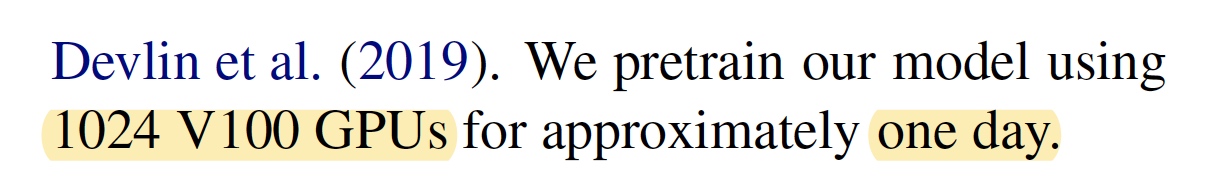
TPU(复现)
总共训练了近 20 万,总共见过近 16 亿个训练数据 (instance); 在 Cloud TPU v3-256 上训练了 24 小时,相当于在 TPU v3-8(128G 显存) 上需要训练一个月
4.2 实验
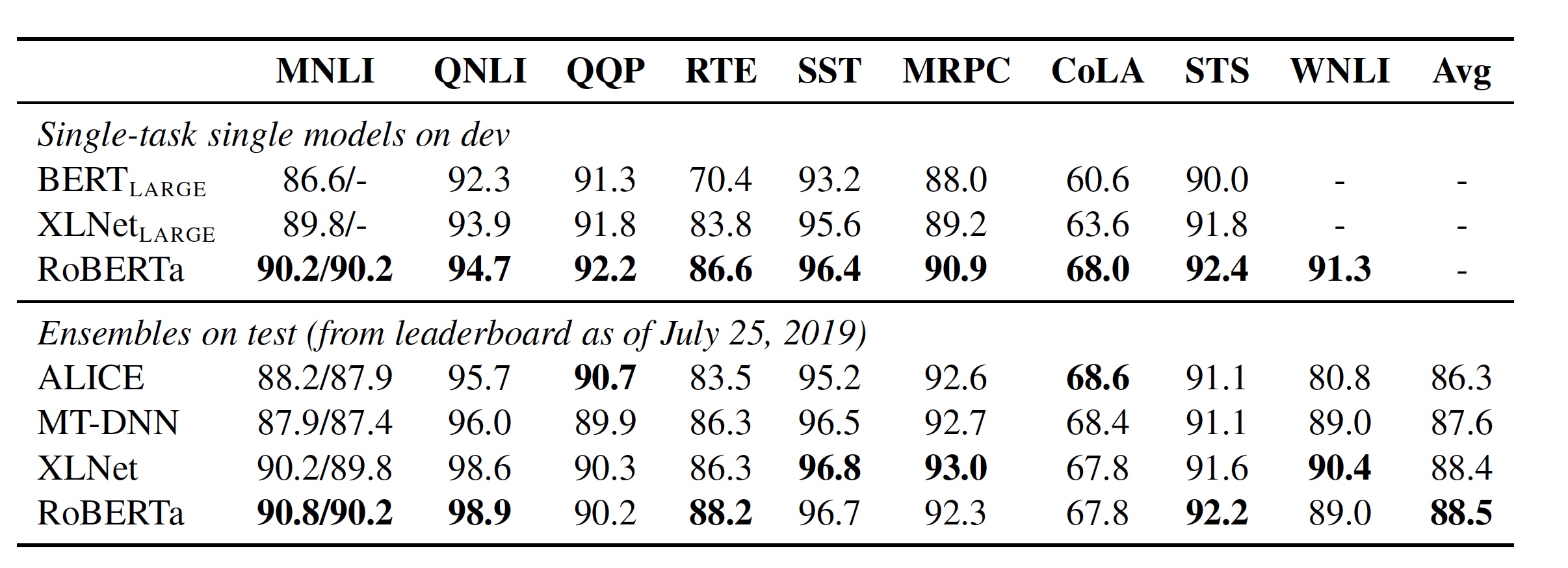
最后的 GLUE 的实验结果如下图所示:
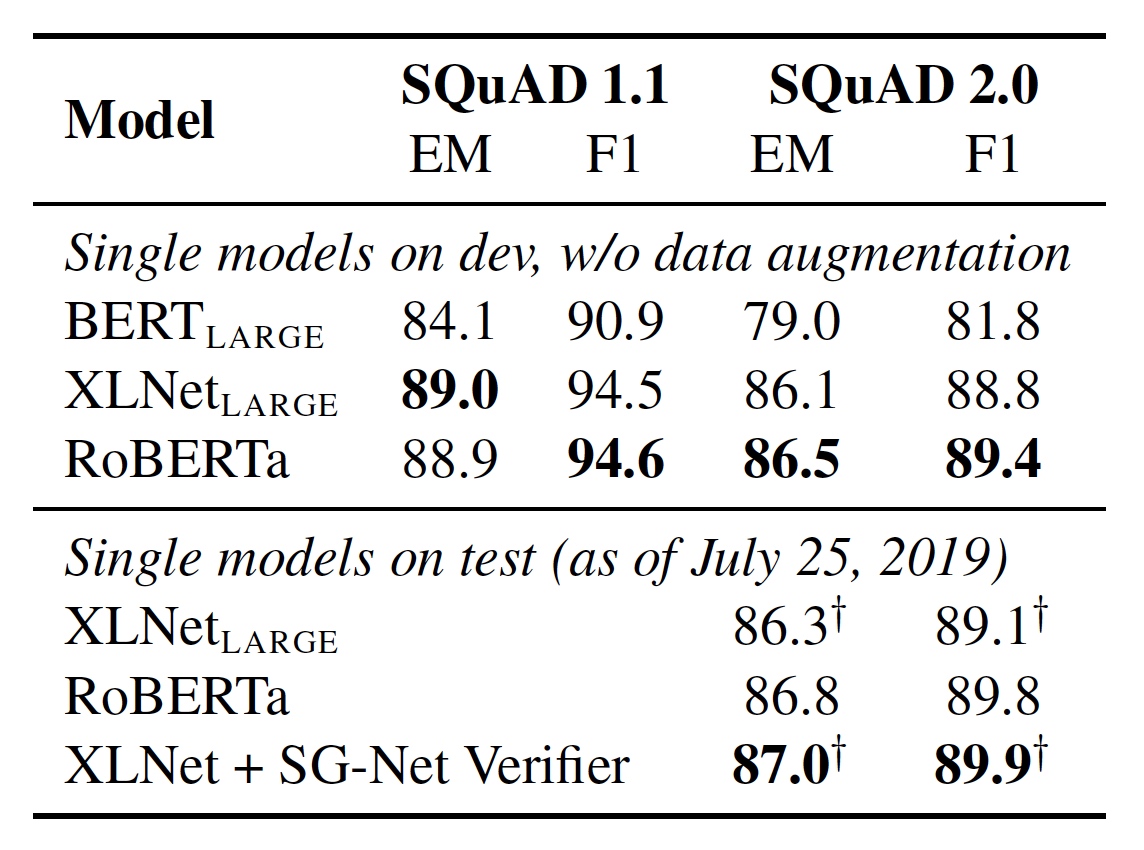
SQuAD 的结果如下图所示:
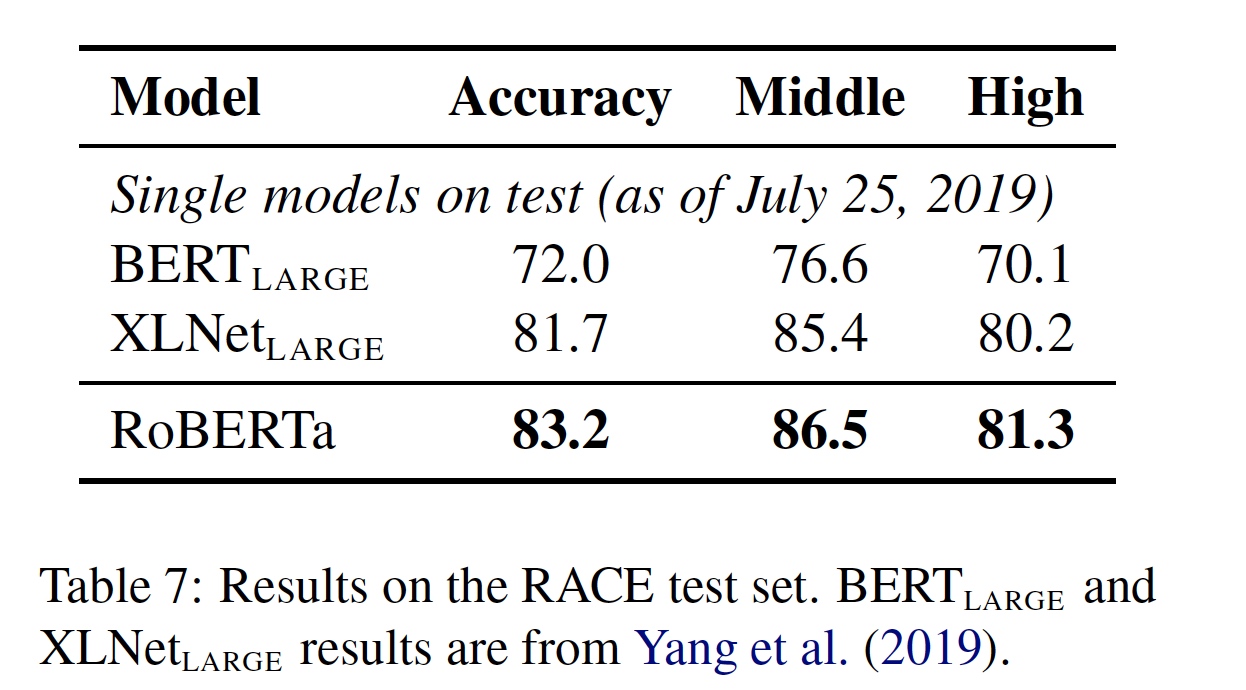
RACE 的结果如下图所示:
实验汇总
RoBERTa (Robustly optimized BERT approach)
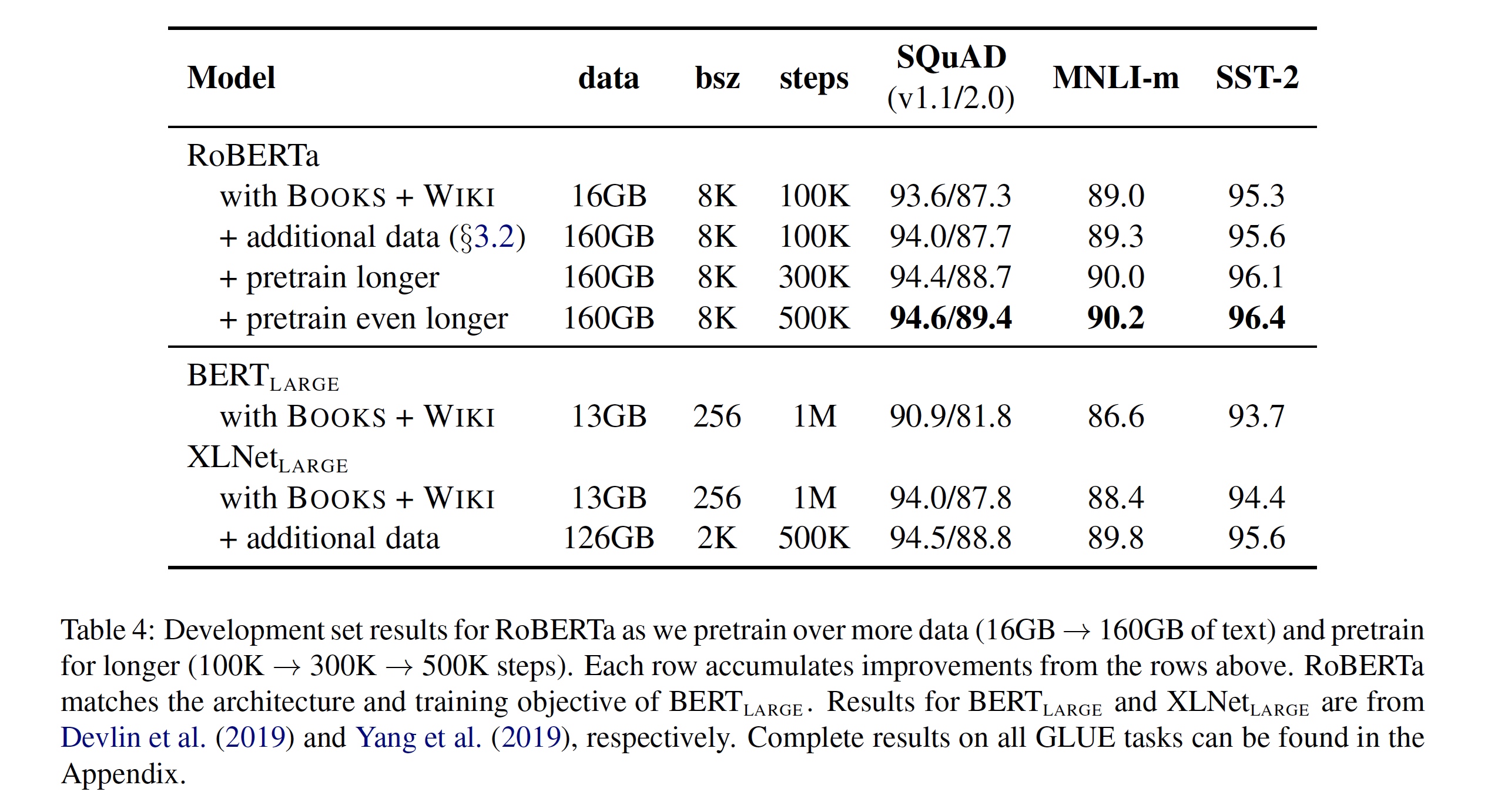
首先看RoBERTa,BERT,XLNet 对比,三个模型均在Books + Wiki 数据集上进行训练,通过对比可以发现,改进后的RoBERTa相比于BERT有很大的提升,想必是larger batch,dynamic masking,与 no next sentence prediction等带来的增益。并且与XLNet模型相比,也有一定的提升,但是个人认为XLNet用相同数据和方法训练,效果应该更好。横向看XLNet与RoBERTa大批量与多步数对比,由于训练条件不同,效果很难比较。纵向看, 训练越多,性能越好。
总结
RoBERTa包括如下改进
- 数据生成方式和任务改进:取消下一个句子预测,并且数据连续从一个文档中获得。
- 更大更多样性的数据:使用 30G 中文训练,包含 3 亿个句子,100 亿个字 (即 token)。由于新闻、社区讨论、多个百科,保罗万象,覆盖数十万个主题,共160+G数据。
- Byte-Pair Encoding(BPE)是字符级和词级别表征的混合。
- 训练更久:超过500k steps
- 更大批次:使用了超大(8k)的批次 batch size。
- 调整优化器的参数。
- 使用全词 mask(whole word mask)和动态的mask。