目录
(1)window多流合并
在Flink中支持窗口上的多流合并,即在一个窗口中按照相同条件对两个输入数据流进行关联操作,需要保证输入的Stream要构建在相同的Window上,并使用相同类型的Key作为关联条件。


(2)Window join


Windows类型的join都是利用window的机制,先将数据缓存在Window State中,当窗口触发计算时,执行join操作;interval join也是利用state存储数据再处理,区别在于state中的数据有失效机制,依靠数据触发数据清理;
(2.1)Tumbling Window Join详解
滚动窗口关联数据操作是将滚动窗口中相同的Key的两个Datastream数据集中的元素进行关联,并应用用户自定义的JoinFunction计算关联结果。

Tumbling Window Join代码开发
MySource:
package com.aikfk.flink.base;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
public class MySource implements SourceFunction<String> {
@Override
public void cancel() {
}
@Override
public void run(SourceContext<String> ctx) throws Exception {
String[] datas = {
"a,1575159390000",
"a,1575159402000",
"b,1575159427000",
"c,1575159382000",
"b,1575159407000",
"a,1575159302000"
};
for (int k = 0; k < datas.length; k++) {
Thread.sleep(100);
ctx.collect(datas[k]);
}
}
}
MySource2:
package com.aikfk.flink.base;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
public class MySource2 implements SourceFunction<String> {
@Override
public void cancel() {
}
@Override
public void run(SourceContext<String> ctx) throws Exception {
String[] datas = {
"a,1575159381300",
"a,1575159399000",
"d,1575159397000",
"f,1575159384000"
};
for (int k = 0; k < datas.length; k++) {
ctx.collect(datas[k]);
}
}
}
WindowJoin:
window join之前必须要生成WM,即实现assignTimestampsAndWatermarks方法
package com.aikfk.flink.datastream.window;
import com.aikfk.flink.base.MySource;
import com.aikfk.flink.base.MySource2;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.JoinFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple4;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import java.time.Duration;
/**
* @author :caizhengjie
* @description:TODO
* @date :2021/3/25 1:57 下午
*/
public class WindowJoin {
public static void main(String[] args) throws Exception {
// 1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2.生成dataStream1,window join之前必须要生成WM,即实现assignTimestampsAndWatermarks方法
DataStream<Tuple2<String,Long>> dataStream1 = env.addSource(new MySource()).map(new MapFunction<String, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(String s) throws Exception {
String[] words = s.split(",");
return new Tuple2<>(words[0] , Long.parseLong(words[1]));
}
})
.assignTimestampsAndWatermarks(WatermarkStrategy
.<Tuple2<String,Long>>forBoundedOutOfOrderness(Duration.ofMinutes(1L))
.withTimestampAssigner(new SerializableTimestampAssigner<Tuple2<String,Long>>() {
@Override
public long extractTimestamp(Tuple2<String,Long> input, long l) {
return input.f1;
}
}));
// 3.生成dataStream2,window join之前必须要生成WM,即实现assignTimestampsAndWatermarks方法
DataStream<Tuple2<String,Long>> dataStream2 = env.addSource(new MySource2()).map(new MapFunction<String, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(String s) throws Exception {
String[] words = s.split(",");
return new Tuple2<>(words[0] , Long.parseLong(words[1]));
}
}).assignTimestampsAndWatermarks(WatermarkStrategy
.<Tuple2<String,Long>>forBoundedOutOfOrderness(Duration.ofMinutes(1L))
.withTimestampAssigner(new SerializableTimestampAssigner<Tuple2<String,Long>>() {
@Override
public long extractTimestamp(Tuple2<String,Long> input, long l) {
return input.f1;
}
}));
// TumblingEvent window join
dataStream1.join(dataStream2)
.where(key -> key.f0)
.equalTo(key -> key.f0)
.window(TumblingEventTimeWindows.of(Time.minutes(1L)))
.apply(new JoinFunction<Tuple2<String, Long>, Tuple2<String, Long>, Object>() {
@Override
public Object join(Tuple2<String, Long> t1, Tuple2<String, Long> t2) throws Exception {
return new Tuple4<>(t1.f0,t1.f1,t2.f0,t2.f1);
}
})
.print();
env.execute("Window WordCount");
}
}
运行结果:
11> (a,1575159390000,a,1575159381300)
11> (a,1575159390000,a,1575159399000)
11> (a,1575159402000,a,1575159381300)
11> (a,1575159402000,a,1575159399000)
(2.2)Sliding Window Join详解
两个Datastream数据元素在单个窗口中根据相同的Key进行关联,且关联数据会发生重叠同时滑动窗口关联也是基于内连接,如果一个窗口中只出现了一个Datastream中的Key,则不会输出关联计算结果。


(2.3)Session Window Join详解
会话窗口是根据Session Gap将数据集划分成不同的窗口,会话窗口关联对两个Stream的数据元素进行窗口关联操作,窗口中含有两个数据集元素,并且元素具有相同的Key,则输出关联计算结果。

(3)Interval join
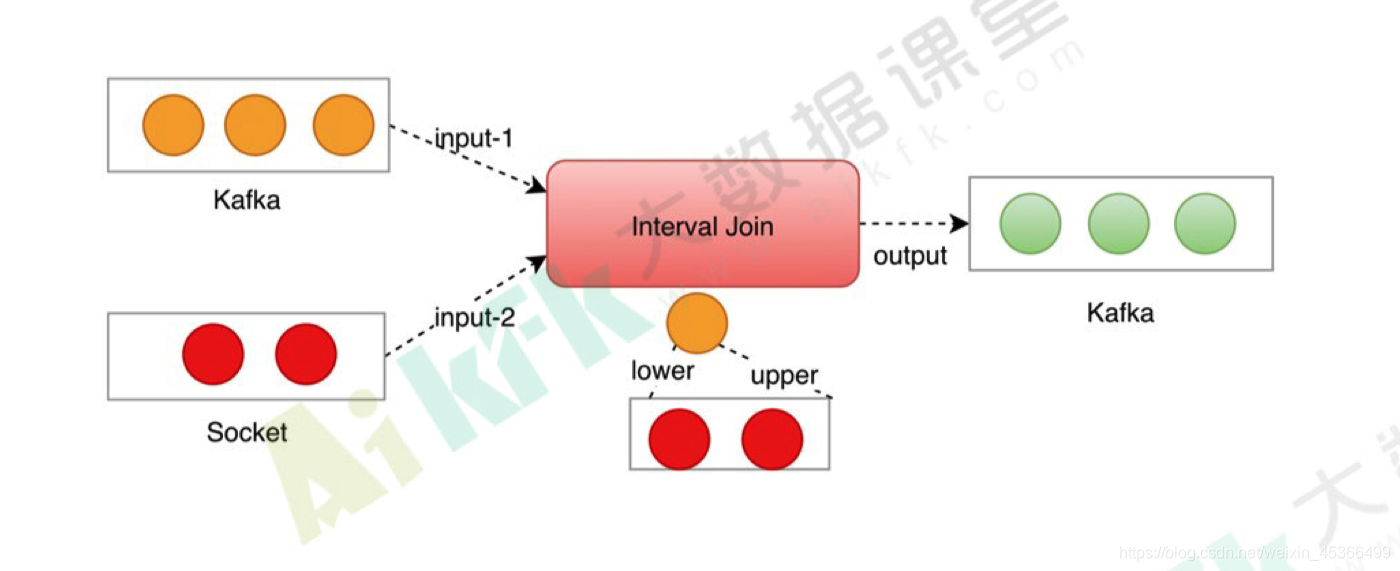
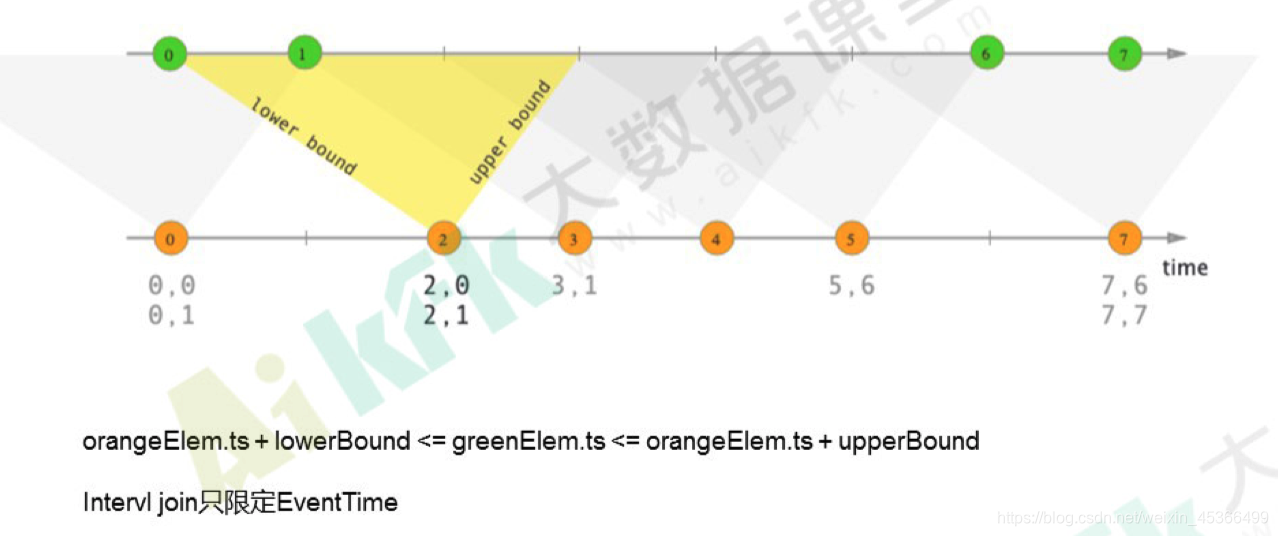
Interval join代码开发:
interval join之前必须要生成WM,即实现assignTimestampsAndWatermarks方法
package com.aikfk.flink.datastream.window;
import com.aikfk.flink.base.MySource;
import com.aikfk.flink.base.MySource2;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple4;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.ProcessJoinFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
import java.time.Duration;
/**
* @author :caizhengjie
* @description:TODO
* @date :2021/3/25 1:57 下午
*/
public class IntervalJoin {
public static void main(String[] args) throws Exception {
// 1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2.生成dataStream1,interval join之前必须要生成WM,即实现assignTimestampsAndWatermarks方法
DataStream<Tuple2<String,Long>> dataStream1 = env.addSource(new MySource()).map(new MapFunction<String, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(String s) throws Exception {
String[] words = s.split(",");
return new Tuple2<>(words[0] , Long.parseLong(words[1]));
}
})
.assignTimestampsAndWatermarks(WatermarkStrategy
.<Tuple2<String,Long>>forBoundedOutOfOrderness(Duration.ofMinutes(1L))
.withTimestampAssigner(new SerializableTimestampAssigner<Tuple2<String,Long>>() {
@Override
public long extractTimestamp(Tuple2<String,Long> input, long l) {
return input.f1;
}
}));
// 3.生成dataStream2,interval join之前必须要生成WM,即实现assignTimestampsAndWatermarks方法
DataStream<Tuple2<String,Long>> dataStream2 = env.addSource(new MySource2()).map(new MapFunction<String, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(String s) throws Exception {
String[] words = s.split(",");
return new Tuple2<>(words[0] , Long.parseLong(words[1]));
}
}).assignTimestampsAndWatermarks(WatermarkStrategy
.<Tuple2<String,Long>>forBoundedOutOfOrderness(Duration.ofMinutes(1L))
.withTimestampAssigner(new SerializableTimestampAssigner<Tuple2<String,Long>>() {
@Override
public long extractTimestamp(Tuple2<String,Long> input, long l) {
return input.f1;
}
}));
// interval join
dataStream1.keyBy(key -> key.f0)
.intervalJoin(dataStream2.keyBy(key -> key.f0))
.between(Time.seconds(0L),Time.seconds(2L))
.process(new ProcessJoinFunction<Tuple2<String, Long>, Tuple2<String, Long>, Object>() {
@Override
public void processElement(Tuple2<String, Long> t1,
Tuple2<String, Long> t2,
Context context, Collector<Object> collector) throws Exception {
collector.collect(new Tuple4<>(t1.f0,t1.f1,t2.f0,t2.f1));
}
}).print();
env.execute("Window WordCount");
}
}
(4)几个流合并区别
join , coGroup , connect, union的区别
join :
- 可用于DataStream和DataSet。只能2个DataStream一起join,或者2个DataSet一起join
- 用于DataStream时返回是JoinedStreams,用于DataSet时返回是Join0peratorSets
- 用于DataStream时需要与窗口同时使用,语法是:join where equalTo window apply,用于DataSet时的语法是:join where equalTo with (where是指定第一个输入的分区字段,equalTo是指定第二个输入的分区字段,这2个字段类型需要一致)
- 与SQL中的inner join同义,只输出2个实时窗口内或2个数据集合内能匹配上的笛卡尔积,不能匹配上的不输出。
- apply方法中或with方法中均可以使用JoinFunction或FlatJoinFunction处理匹配上的数据对(用于DataStream和DataSet时均可)
- 侧重对2个输入里的数据对进行处理,join方法的入参是单个数据
- 可以join2个类型不同的流或join2个类型不同的数据集(比如Tuple2<String, Long> join Tuple2<Long, String>),但是匹配的key或field类型要一致,不然报错(比如where中的String与equalTo中的String匹配才行)
coGroup :
- 可用于DataStream和DataSet。只能2个DataStream一起coGroup,或者2个DataSet一起coGroup
- 用于DataStream时返回是CoGroupedStreams,用于DataSet时返回是CoGroup0peratorSets
- 用于DataStream时需要与窗口同时使用,语法是:coGroup where equalTo window apply,用于DataSet时的语法是: coGroup where equalTo with
- 把2个实时窗口内或2个数据集合内key相同的数据分组同一个分区,key不能匹配上的数据(只在一个窗口或集合内存在的数据)也分组到另一个分区上。
- apply方法中或with方法中均可以使用CoGroupFunction对数据分组(用于DataStream和DataSet时均可,无FlatCoGroupFunction)
- 侧重对2个输入的集合进行处理,coGroup方法的入参是Iterable类型
- 可以coGroup2个类型不同的流或coGroup2个类型不同的数据集(比如Tuple2<String, Long> join Tuple2<Long,String>),但是匹配的key或field类型要一致,不然报错(比如where中的String与equalTo中的String匹配才行)
connect:
- 只能用于DataStream,返回是ConnectedStreams。不能用于DataSet.
- 只能2个流一起connect(stream1.connect(stream2))
- connect后可以对2个流分别处理(使用CoMapFunction或CoFlatMapFunction)
- 可以connect2个类型不同的流(比如Tuple2<String,Long> connect Tuple2<Long,String>)
union:
- 可以多个流一起合并(stream1.union(stream2, stream3, stream4)),合并结果是一个新Datastream;只能2个DataSet一起
- 用于DataStream时,返回是Datas tream;用于DataSet时,返回是DataSet;"2
合并,合并结果是一个新DataSet - 无论是合并Datastream还是合并DataSet,都不去重,2个源的消息或记录都保存。
- 不可以union 2个类型不同的流或union 2个类型不同的数据集
以上内容仅供参考学习,如有侵权请联系我删除!
如果这篇文章对您有帮助,左下角的大拇指就是对博主最大的鼓励。
您的鼓励就是博主最大的动力!