MySQL深入(一)
文章目录
MySQL的事务隔离
MySQL有四类隔离级别:
- Read Uncommitted(读取未提交内容)
- Read Committed(读取提交内容)
- Repeatable Read(可重读)
- Serializable(可串行化)
事务隔离强度
隔离强度从上到下逐渐增强,如图:

- Read Uncommitted :在该隔离级别,所有事务都可以看到其他未提交事务的执行结果。也就是说基本没有任何事务隔离性,其他事务的没进行事务提交的修改和回滚都有可能影响其他事务的执行结果。
- Read Committed :在该隔离级别,一个事务只能看见已经提交事务所做的改变。也就是说该级别下,一个事务对某数据的多次读取操作仍然可以出现前后读取不一致的情况。假设事务A对数据Data进行进行三次查询,而有事务B,C分别前后对数据进行了修改并提交了,那么事务A可能会读到三个不同的数据。
- Repeatable Read :MySQL的默认事务隔离级别,在该隔离级别,同一事务的多个实例在并发读取数据时,会看到同样的数据,但其他事务的插入数据是可以看见的。也就是说,事务A在事务中读取的数据不会因为其他事务的提交了的修改,而导致出现读取结果被修改的现象。但是,假设其他事务有插入操作,并且插入的数据刚好符合事务A中查询条件的范围,那么事务A可能会读取到其他事务插入的数据,导致读取数据的数量前后不一致,也就是所谓的幻读。
- Serializable :这是最高的隔离级别,它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。通过共享锁实现。也就是说,假设事务A要读取某三行数据,那么这三行就被事务A占有,并且只占有这三行数据,也就是说事务A整个过程中看见的就这三行数据,其他事务无法对这三行数据进行任何操作。但这也导致了性能的问题,
脏读
发生条件: 在事务级别Read Uncommitted下,多事务读取修改情况下。
导致脏读的主要原因是所有事务都可以看到其他未提交事务的执行结果,假设有事务A,并且事务A在事务中有多次读取的情况,现有事务B对事务A读取的数据进行修改并且没有进行提交,而且可能失败并发生回滚现象。那么事务A可能读取到的数据可能是B没有提交的修改后的数据,也可能是B事务失败后回滚的数据。
脏写
发生条件: 在事务级别Read Uncommitted下,多事务读取修改情况下。
和脏读类似,主要原因是所有事务都可以看到其他未提交事务的执行结果。
假设有两事务A,B对数据Data进行修改,在事务A之前有事务B对数据Data修改,然后事务A在进行修改并提交了,但是事务B因为某些原因导致事务失败并进行回滚,那么事务B回滚到的数据是其操作之前的状态,那么事务A的修改就被事务B回滚的数据覆盖了。结果就导致了事务A提交的修改无效了。
不可重复读
发生条件: 在事务级别Read Uncommitted,Read Committed下,多事务读取修改情况下。
可以说是脏读的缩小版,在Read Committed事务级别下,一个事务只能已经提交事务所做的改变,但这无法完全避免事务读取数据的前后一致。
假设事务A对数据Data进行进行三次查询,而有事务B,C分别前后对数据进行了修改并提交了,那么事务A可能会读到三个不同的数据。这就是不可重复读。虽然B,C事务都提交了,但是这个提交结果可能会导致其他事务的读取结果。
幻读
发生条件: 在事务级别Read Uncommitted,Read Committed,Repeatable Read下,多事务情况读取插入删除情况下。
幻读一般是因为,事务的插入和删除导致的,幻读就如其命一样,在一个多次读取的事务中,前后读取到的数据个数不一样,这就是幻读,如同幻觉一般,数据会突然出现和消失。
假设事务A有多次读取操作,并且有事务B,C分别进行插入删除操作,在A第一次读取后,事务B对表进行插入操作,插入的数据刚好符合A的查询条件,那么A再次读取数据,就会发现读取的数据中多出了几行数据,如同出现幻觉一般。在A再次读取后面,C把多条数据进行了删除,并且删除的数据刚好符合A中查询的条件,那么A再次读取时,A就无法读取完整的数据了。
解决脏读,脏写,不可重复读和幻读现象
开启事务级别Serializable,serializable下会完全锁定字段,若一个事务来查询同一份数据就必须等待,直到前一个事务完成并解除锁定为止。是完整的隔离级别。但这也导致了一些并发性能的问题,多个事务对同一行数据查询操作,为了安全,那么就只能逐个事务排队对数据进行操作,效率上大打折扣。
变量
系统变量:全局变量,会话变量
自定义变量:用户变量,局部变量
#参看当前会话系统变量
show session variables;
#参考全局系统变量
show global variables;
show global variables like '%';
#查看指定系统变量命
select @@global.变量命
#设置全局系统变量
set global 变量名 = 值;
set @@global.变量名=值;
#设置用户变量
set @用户变量=值;
#申明局部变量
declare 变量命 类型;
#设置局部变量
SET 局部变量命=值;
mysql存储过程
存储过程是为了完成特定功能的SQL语句集,经编译创建并保存在数据库中,用户可通过指定存储过程的名字并给定参数(需要时)来调用执行。
mysql的存储过程的写法跟一般语言的函数写法很相似,主要还是声明,方法体和返回值组成。
存储过程中的三种传递参数
传递参数主要分三大种:IN,OUT,INOUT。分别是输入参数,输出参数和输入输出参数。
在创建存储过程中IN和INOUT可以作为存储过程的传入值使用,而OUT是作为输出值使用,类似于函数中的return。
创建存储过程
#创建名为sp_name的存储过程
CREATE PROCEDURE sp_name(IN p_in int)
BEGIN
#编写SQL语句
END;
#创建一个有权限的存储过程
CREATE DEFINER = {username} PROCEDURE sp_name(IN p_in int)
BEGIN
#编写SQL语句
END;
#创建一个包含查询语句的存储过程
#delimiter用来声明语句的结束符号从分号;临时改为$,主要为了区分存储体中的SQL结束和存储过程的结束符
delimiter $
CREATE PROCEDURE check_user(IN user_id int,IN password int,OUT result int)
BEGIN
#这里是通过OUT变量来传递放回值
SELECT count(*) INTO result
FROM USERTable
WHERE id=user_id AND Password=password;
END$
调用存储过程
存储过程的调用使用call关键字,并且在通过传递的参数来获得放回值。
#存储过程的调用使用call关键字
#通过用户变量@userchecke_result获取放回值
set @userchecke_result=0
call check_user(5,123456,@userchecke_result)
删除存储过程
使用drop删除
DROP PROCEDURE sp_name;
函数
MySQL 有很多内置的函数,但是我们也可以定义属于自己的函数。
创建函数
CREATE FUNCTION fun_name(id int,pwd int) RETURN INT
BEGIN
DECLARE result INT DEFAULT 0;
SELECT count(*) INTO result
FROM userTable
WHERE use_id=id AND password=pwd;
RETURN result;
END $
调用函数
函数的调用直接使用即可
SELECT fun_name(5,123456);
删除函数
DROP FUNCUTION sp_name;
MySQL的一些关键文件
logbin文件:二进制日志文件
logerror文件:错误日志文件
my.ini文件:MySQL配置文件
MySQL逻辑框架
分层
MySQL逻辑框架分4层:
- 连接层
- 服务层
- 存储引擎层
- 存储层
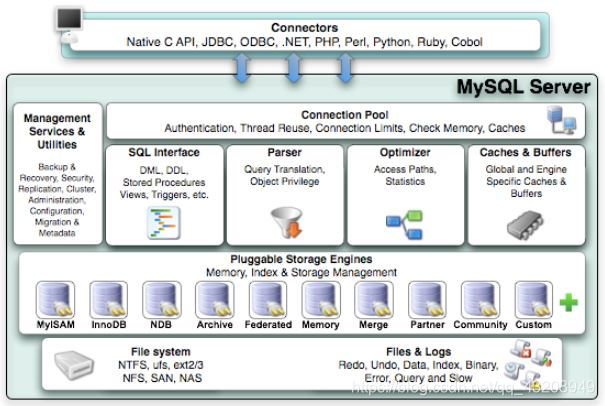
- 连接层:负责客户端和连接服务,该层上引入了线程池地 概念,为通过认证通过安全接入的客户端提供线程。
- 服务层:主要完成大部分的核心服务功能,如SQL接口,并完成缓存查询,SQL的分析和优化及部分内置函数的执行。
- 存储引擎层:存储引擎真正的负责了MySQL中数据的存储和提取,服务器通过api和存储引擎进行通信。不同的存储引擎拥有不同的存储功能。
- 数据存储层:主要将数据存储与运行在裸设备的文件存储系统之上,并完成与存储引擎的交互。
查看MySQL引擎
#查看所有引擎
show engine;
#查看使用引擎
SHOW VARIABLES LIKE 'storage_engine';
InnoDB存储引擎(默认引擎)
InnoDB是事务型数据库,支持事务安全表(ACID),支持行锁定和外键。支持 行锁设计、MVCC、外键、提供一致性非锁定读 。
InnoDB主要特性
- 为MySQL提供了具有提交、回滚和崩溃恢复能力的事物安全(ACID兼容)存储引擎。
- InnoDB存储引擎为在主内存中缓存数据和索引而维持它自己的缓冲池。
- InnoDB支持外键完整性约束
InnoDB体系

内存池 :负责维护缓存磁盘上的数据,重做日志缓冲,维护内部数据等。
后台线程:负责刷新内存池的数据,保证缓存的是最新的数据;将内存数据刷新到磁盘中等。
InnoDB的后台线程
InnoDB是一个单进程多线程的模型,后台不同的线程负责不同的任务。
Master Thread :负责将缓冲池中的数据异步刷新到硬盘中,保证数据一致性,包括脏页的刷新、合并插入、UNDO页的回收等。
IO Thread :InnoDB引擎中大量使用异步IO来处理IO请求。可以通过系统变量查看io线程的个数:
SHOW VARIABLES LIKE 'innodb_%io_threads';
Purge Thread:事务被提交后,undolog不再需要,需要Purge Thread回收。
Page Cleaner Thread:将脏页刷新操作放入单独的线程中完成。
Innodb内存

InnoDB 存储引擎是基于磁盘存储的,也就是说数据都是存储在磁盘上的,由于 CPU 速度和磁盘速度之间的鸿沟, InnoDB 引擎使用缓冲池技术来提高数据库的整体性能。
缓冲池中缓存的数据页类型有: 索引页、数据页、 undo 页、插入缓冲、自适应哈希索引、 InnoDB 的锁信息、数据字典信息等 。在InnoDB中,缓冲池中的页大小默认为16KB。
LRU List、Free List 和 Flush List
- Free List(空闲链表):用于保存内存中空闲的内存页。
- LRU List:InnoDB通过LRU(Latest Recent Used,最近最少使用)算法来管理缓冲池。而LRU List就是用来保存最近使用过的数据位置的链表。当缓冲池放不下新读取的页时,就会释放LRU列表尾端的页。
- Flush List:在LRU List 中的页被修改后,称该页为 脏页(dirty page) 。脏页存储于 Flush List,表示缓冲池中的页与磁盘页不一致,等待被调度刷新。
undo log和redo log
- redo log :redo log是InnoDB存储引擎层的日志, **用于记录事务操作的变化,记录的是数据修改之后的值。**InnoDB 将重做日志首先写入 redo buffer cache,之后通过一定频率写入到重做日志(redo logo)中。
- undo log :保存了事务发生之前的数据的一个版本,可以用于回滚,同时可以提供多版本并发控制下的读(MVCC)。
bin log
用于复制,在主从复制中,从库利用主库上的binlog进行重播,实现主从同步。
log和redo log
- redo log :redo log是InnoDB存储引擎层的日志, **用于记录事务操作的变化,记录的是数据修改之后的值。**InnoDB 将重做日志首先写入 redo buffer cache,之后通过一定频率写入到重做日志(redo logo)中。
- undo log :保存了事务发生之前的数据的一个版本,可以用于回滚,同时可以提供多版本并发控制下的读(MVCC)。
bin log
用于复制,在主从复制中,从库利用主库上的binlog进行重播,实现主从同步。