本系列是七月算法机器学习课程笔记
文章目录
1 从LR到决策树
1.1 决策树
决策树出现是模仿了人类自己做判断的一个过程。
例如一个相亲案例。要考查的数据维度可能有:身高、财富积累、长相、是不是潜力股、品德如何。根据逻辑回归的决策过程是下图这样。计算出的概率高,就去相亲。

但是人做决策可能是下面这样。例如年龄>30,不见。年龄<30,长得丑不见。
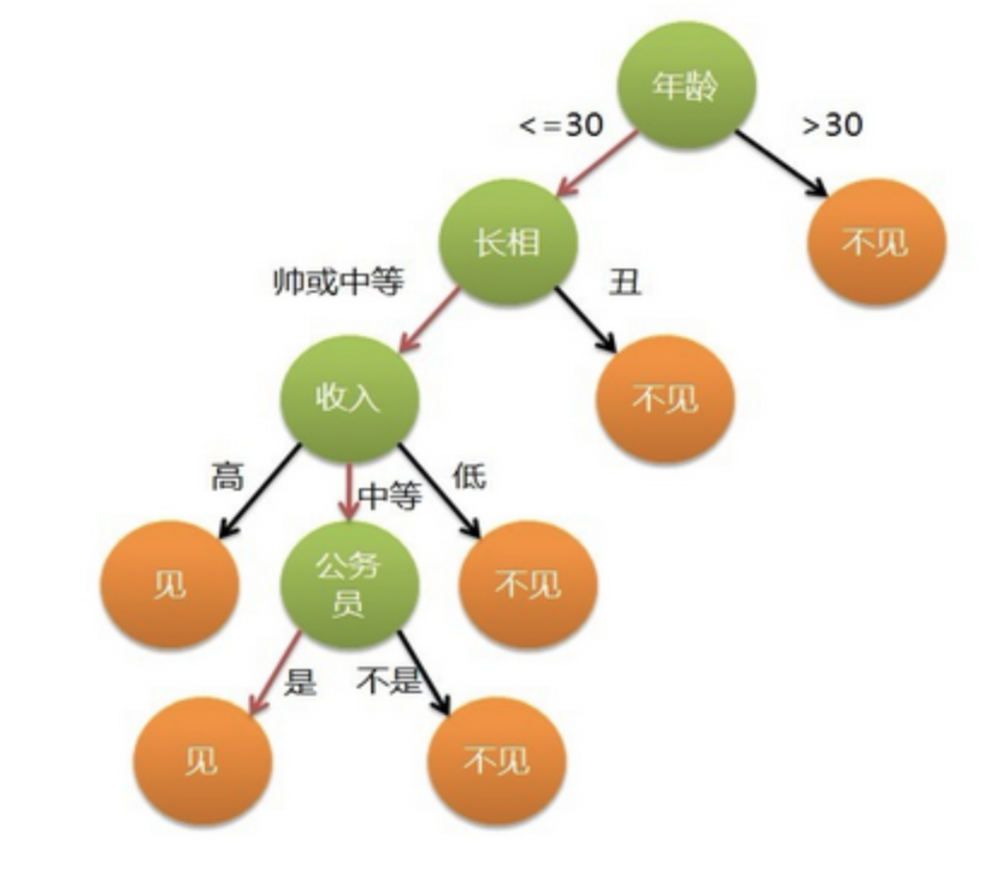
这样的决策过程,简单,逻辑清晰,可解释性好。上面的图就是一颗决策树。
每个绿色的节点,称为内部节点,对应于某一个属性。年龄、长相、收入、是否公务员都是属性。
每个分支对应于一种取值。
每个叶子节点对应一种结果。
学习过程:通过对训练样本的分析确定“划分属性”。例如女孩看韩剧,学习哪些属性重要,以及怎么划分。
预测过程:将测试样本从根节点开始,沿着划分属性构成的“判断测试序列”走到叶子节点。
1.2 决策树的终止条件
决策树构建过程中遇到以下三种情况就可以停止构建了。
第一种情况:当前节点包含的样本属于同一类别,无需划分。例如当前节点下所有样本的结果都是相亲。那就无需划分下去了。
第二种情况:当前属性集为空,或者所有样本在所有属性上取值相同,无法划分。例如集合中只有2个样本。一个样本身高=180,长相=帅,结果=相亲;一个样本身高=180,长相=帅,结果=不相亲。所有条件都一样(属性值都相同),但结果不同。这个时候就不划分了。
第三种情况:当前节点包含的样本集合为空,不能划分。
1.3 决策树划分依据
1.3.1 信息熵
信息熵是度量样本集合信息“纯度”的一个指标。例如一个样本集合中全是黑球,一个人伸手拿出一个球是黑球的概率是100%。这就是纯度很高的一种情况。如果样本集合中有100个球,有100种颜色,那拿出一个球是黑球的概率就是 1 100 \dfrac{1}{100} 1001。这就是非常混乱的一种情况。不利于人做出决策。
决策树不断递进的过程是一个信息熵不断较小的过程,因为我们是要做出决策的。
如果样本集合集合中第k类样本的所占比例为 p k p_k pk,那样本信息熵的定义为 E n t ( D ) = − ∑ k = 1 ∣ y ∣ p k ∗ l o g 2 p k Ent(D)=-\sum_{k=1}^{|y|}p_k*log_2p_k Ent(D)=−∑k=1∣y∣pk∗log2pk, p k = 0 , 则 l o g 2 p k = 0 p_k=0,则log_2p_k=0 pk=0,则log2pk=0
Ent(D)越小,样本集合纯度越高。
1.3.2 信息增益
信息增益直接以信息熵计算为基础,计算当前划分对信息熵造成的变化。
离散属性a的取值有 a 1 , a 2 , a 3 . . . a V {a^1,a^2,a^3...a^V} a1,a2,a3...aV
信息增益是以属性a对数据集D进行划分所获得的的信息增益为: G a i n ( D , a ) = E n t ( D ) − ∑ v = 1 V ∣ D v ∣ ∣ D ∣ E n t ( D v ) Gain(D,a)= Ent(D) - \sum_{v=1}^{V}\dfrac{|D^v|}{|D|}Ent(D^v) Gain(D,a)=Ent(D)−∑v=1V∣D∣∣Dv∣Ent(Dv)
|D|表示数据集D的样本数量
∣ D v ∣ |D^v| ∣Dv∣表示数据集D中a= a v a^v av的样本数量

E n t ( D v ) Ent(D^v) Ent(Dv)表示划分后的信息熵
具体例子参考周老师的西瓜书。


1.3.3 ID3模型
根据信息增益选择属性,形成决策树的模型称为ID3。
在上面例子中可以用同样的方法计算出其他属性的信息增益。

发现按纹理的信息增益最大。那么就选择纹理这个属性做划分。形成下面这棵树。

接着以每一个节点为一个新的数据集计算其中每个属性的信息增益。以纹理清晰这个节点为例。该结点包含的样例集合 D1 中有编号为 {1,2, 3, 4, 5, 6, 8, 10, 15} 的 9 个样例,可用属性集合为{色泽,根蒂,敲声,脐部7 触感}.基于 D1 计算出各属性的信息增益:
Gain(D1, 色泽) = 0.043; Gain(D1,根蒂) = 0.458; Gain(D1,敲声) = 0.331; Gain(D1,脐部) = 0.458; Gain(D1,触感) = 0.458.
“根蒂”、 “脐部”、 “触感” 3 个属性均取得了最大的信息增益,可任选其中之一作为划分属性。类似这样的继续划分下去,直到遇到上面那三种情况,不再划分。例子的具体信息可以查看西瓜书第四章。
1.3.4 信息增益率
根据信息增益增益率选择属性,形成决策树的模型称为C4.5。
例如在上面例子中,如果将编号作为一个属性。那它可以将每个样本分到不同的桶内,就不能再继续划分下去,但是这种划分显然没有任何意义。怎么避免选择这样的属性呢?使用信息增益率。
信息增益率: G r a i n _ r a t i o ( D , a ) = G a i n ( D , a ) I V ( a ) Grain\_ratio(D,a)=\dfrac{Gain(D,a)}{IV(a)} Grain_ratio(D,a)=IV(a)Gain(D,a)
I V ( a ) = − ∑ v = 1 V ∣ D v ∣ ∣ D ∣ l o g 2 ∣ D v ∣ ∣ D ∣ IV(a)=-\sum_{v=1}^V\dfrac{|D^v|}{|D|}log_2\dfrac{|D^v|}{|D|} IV(a)=−∑v=1V∣D∣∣Dv∣log2∣D∣∣Dv∣
IV(a)其实是属性a在数据集上的信息熵。属性a的可能取值越多,IV(a)越大。
ID3 模型会偏好选择属性数目多的属性,C4.5会偏好选择属性数目少的属性。在实际应用中先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
1.3.5 基尼指数
根据基尼指数选择属性,形成决策树的模型称为CART。
G i n i ( D ) = 1 − ∑ k = 1 ∣ y ∣ p k 2 Gini(D)=1-\sum_{k=1}^{|y|}p_k^2 Gini(D)=1−∑k=1∣y∣pk2
基尼指数反应了从D中随机抽取两个样例,其类别标识不一样的概率。
基尼指数越小,数据集D的纯度越高。
例如样本集中有黑球和白球两种。基尼指数反应了两次取到的球颜色不一样的概率。
属性a的基尼指数: G i n i _ i n d e x ( D , a ) = ∑ v = 1 V ∣ D v ∣ ∣ D ∣ G i n i ( D ) Gini\_index(D,a)=\sum_{v=1}^V\dfrac{|D^v|}{|D|}Gini(D) Gini_index(D,a)=∑v=1V∣D∣∣Dv∣Gini(D)
在候选属性集中,选择那个划分后基尼指数最小的属性。
1.3.6 信息熵与基尼指数
对函数f(x)=-lnx在x=1处展开一阶泰勒展开,得到 f ( x ) ≈ 1 − x f(x)\approx1-x f(x)≈1−x
信息熵 E n t ( D ) = − ∑ k = 1 ∣ y ∣ p k ∗ l o g 2 p k ≈ ∑ k = 1 ∣ y ∣ p k ( 1 − p k ) Ent(D)=-\sum_{k=1}^{|y|}p_k*log_2p_k\approx\sum_{k=1}^{|y|}p_k(1-p_k) Ent(D)=−∑k=1∣y∣pk∗log2pk≈∑k=1∣y∣pk(1−pk)这个式子和基尼指数是等价的。
也就是说基尼指数和信息熵从数学公式上来讲,约等于。
根据属性选择的标准不同决策树分为三类:ID3、C4.5和CART。
1.3.7 连续值属性
还有一个问题是关于连续值属性的分割问题。
连续属性的取值数量不再有限制。此时需要连续属性离散化。最简单的策略是采用二分法。
给定样本集 D 和连续属性 α,假定 α在 D 上出现了 η个不同的取值,将这些值从小到大进行排序,记为 α 1 α 2 . . , a n {α^1 α^2..,a^n} α1α2..,an。对于属性值相邻的两个样本 a i a^i ai和 a i + 1 a^{i+1} ai+1来说,可以选择 T a = a i + a i + 1 2 T_a=\dfrac{a^i+a^{i+1}}{2} Ta=2ai+ai+1作为分割点。
例如在一个数据集中有4个样本,年龄分别为25,35,21,28。将属性值标在数轴上:21,25,28,35。在第一个和第二个元素之间使用23作为分割点。小于等于23的是一部分,大于23的是一部分。同理,在第二个元素和第三个元素使用26.5作为分割点,在第三个和第四个元素之间用31.5作为分割点。
(以上内容来自西瓜书)。
2 回归树
回归树是决策树用于解决回归类问题的应用。经典案例是用运动员的从业年限和表现,预测运动员的工资。

回归树背后的含义是:
对空间做划分,拿着一把刀垂直于坐标轴砍一刀,将整个平面分为不同的矩形。
例如图中R1={X|Years<4.5} , R2={X|Years>4.5, Hits<117.5},R3={X|Years>4.5,Hits>=117.5}
如果说逻辑回归是产出一条边界完成分类,那么决策树就是拿起一把刀,垂直于坐标轴砍一刀,把平面分成一个一个的小矩形。
2.1 回归树构建方法
把整个空间切分成J个没有重叠的区域 R 1 , R 2 . . . R J R_1,R_2...R_J R1,R2...RJ
其中每一个区域 R j R_j Rj中的样本都给一样的预测结果: = 1 n ∑ j ∈ R j y j =\dfrac{1}{n}\sum_{j \in R_j}y_j =n1∑j∈Rjyj 也就是区域内所有样本的y值的平均值。
目标函数 R S S = ∑ j = 1 J ∑ i ∈ R j ( y i − y ~ ) 2 RSS=\sum_{j=1}^J\sum_{i \in R_j}(y_i-\tilde{y})^2 RSS=∑j=1J∑i∈Rj(yi−y~)2,要是的RSS最小。
求解最小值的方法是:探索式的递归二分。自顶向下:不断从当前位置把样本切到2个分支中。贪婪:每次选择当前最优切割方法。
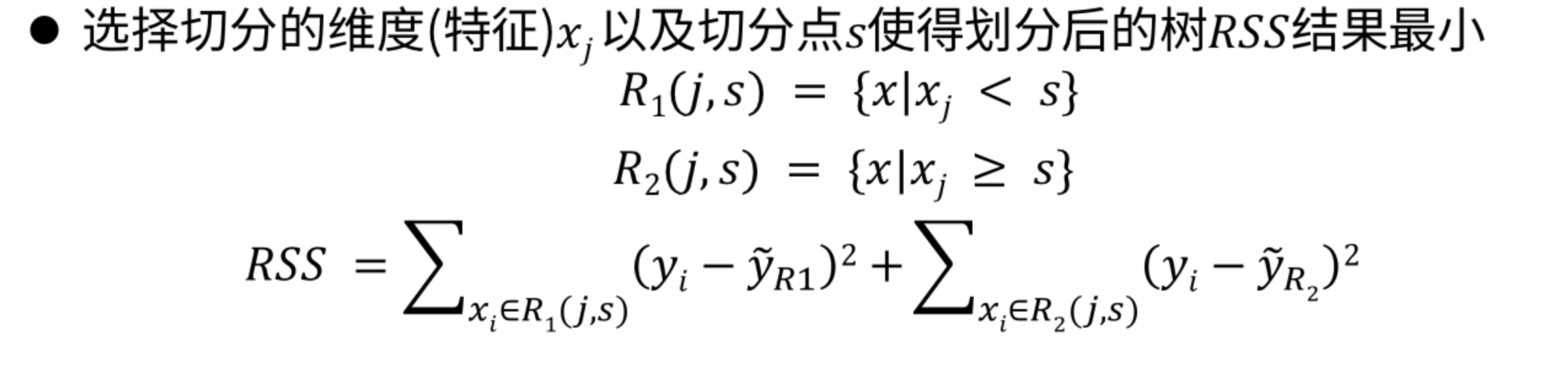
如果我把平面一直切,切到最后一个区域只要一个元素,这就发生了过拟合。而且这样的切分毫无意义。
为了防止过拟合,引入正则化项。
T a {T_a} Ta是生成树的叶子节点个数。 α \alpha α是正则化系数。

3 从决策树到随机森林
过拟合的本质是样本数据中是有噪声的。类比于练习册的答案是有错误的,全部按照答案去学,是不能拿到高分的。
3.1 bagging思想
bagging是每次从样本集中抽取一部分样本进行学习。根据抽取出的样本做学习。

对于t=1,2…T
1)对训练集进行第t次随机采样,共采集m次,得到一个样本量为m的采样集 D m D_m Dm
2)用采样集 D m D_m Dm训练第m个学习器 G m ( x ) G_m(x) Gm(x)。
对于分类场景,则T个学习器投票,票数最多的结果为最终类别。对于回归场景,T个学习器得到的结果进行算数平均得到的值为最终输出结果。
3.2 随机森林
随机森林(random forest)是一种基于树模型的bagging优化版本。不同之处是:
RF选择CART树作为基学习器。
对于t=1,2…T
1)对训练集进行第t次随机采样,共采集m次,得到一个样本量为m的采样集 D m D_m Dm
2)用采样集 D m D_m Dm训练第m个学习器 G m ( x ) G_m(x) Gm(x)。在训练决策树模型节点的时候,选择所有特征中的一部分特征,进行训练,在这些随机选择的特征中选择一个最优的特征来做决策树左右子树划分。