本系列是七月算法nlp就业班学习笔记。
5 NLP中的卷积神经网络
RNN的问题:
1 时间复杂度高
2 最后一个向量包含所有信息。有点不可靠
CNN可以通过卷积核捕捉局部特征,那是不是可以用于句子,表示特定长度的词序列呢?
例如句子:他 毕业 于 上海 交通 大学。
如果长度设定为3,那么CNN应该可以捕获
他 毕业 于
毕业 于 上海
于 上海 交通
上海 交通 大学
这样一些词序列的特征
5.1 卷积
卷积操作:窗口内的每个元素与卷积核做元素乘,然后加起来的值作为卷积之后的特征值。

import numpy as np
m1 = np.matrix('0.2,0.1,-0.3,0.4;0.5,0.2,-0.3,-0.1;-0.1,-0.3,-0.2,0.4')
m2 = np.matrix('3,1,2,-3;-1,2,1,-3;1,1,-1,1')
m3 = np.multiply(m1,m2)
print(m3)
value = np.sum(m3)
print(value)
value就是-1.0
这个卷积操作是一个一维的,也就是说卷积核的大小为nxk(k是词向量的维度)。这个卷积之后相当于一个ngram的词模型。
5.2 多通道
卷积核大小变的是n的大小。
输入经过一个3xk的卷积核得到一个3gram的词序向量。
输入经过一个4xk的卷积核得到一个4gram的词序向量。
输入可以经过多个卷积核,得到多个特征。
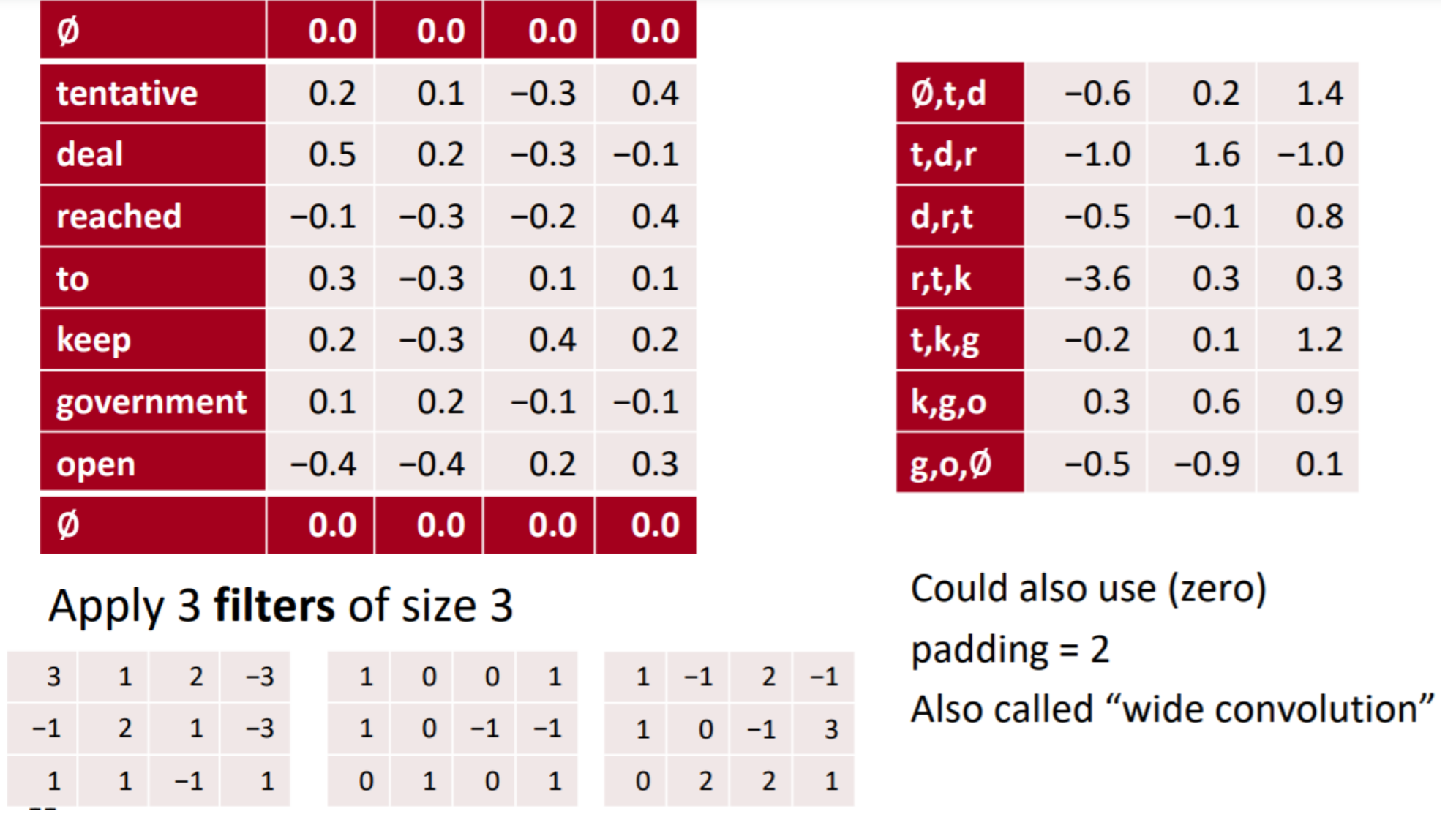
图中是经过了3个,n=3的卷积核,得到的特征向量。
每个卷积核的大小可以不同。
5.2 max pooling
随着卷积核n的不一样,计算出来的结果不一样。
随着n越大,计算出来的结果也越大。
这不是我们想要的。使用max pooling解决。
max pooling:在每一个卷积结果中取最大值。如果经过了x个卷积层,最终得到一个x维的向量。
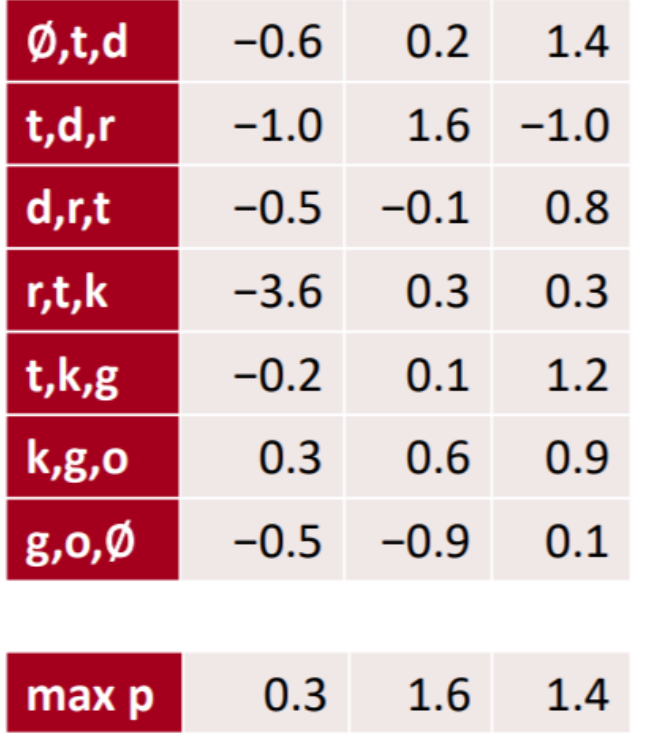
最后得到3维向量(0.3,1.6,1.4)
以上过程可以看论文:Yoon Kim “Convolutional Neural Networks for Sentence Classification”。
输入:一句话,长度为n,每个词查一下词表,得到一个nx100维度的矩阵
做一个1维的卷积,维护300个卷积核。最后得到一个300维的句子表示向量。
作为输入到MLP,实现分类。
开源工具fasttext就是这样的原理。
代码案例:https://github.com/silverriver/NLP_Course/blob/main/TextCNN/main.ipynb