刚才对kafka的数据流进行处理时发现一个很奇怪的事情,就是在scala中split函数对于以 . 为切割符时返回的竟然是个空值,我当时就感觉很奇怪,因为在python中明明是可以的,而且不需要进行转义。
scala:

python:
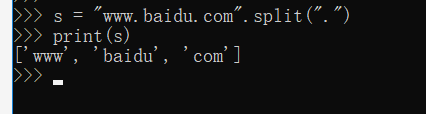
我又测试了scala中其他的分隔符,发现切割不了的应该都需要转义一下,可能在python对split方法进行了一个改写,所以对于很多的字符都是直接分割,不需要进行转义.

下面列举了一些在java或是scala中常见的需要转义的特殊字符
| 序号 | 作用 |
|---|---|
| 1 | $ 匹配输入字符串的结尾位置。如果设置了RegExp对象的Multiline属性,则 $ 也匹配,如‘\n’或’\r’。 |
| 2 | () 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符。 |
| 3 | * 匹配前面的子表达式零次或多次 |
| 4 | + 匹配前面的子表达式一次或多次 |
| 5 | . 匹配除换行符\n之外的任何单字符 |
| 6 | [] 标记一个中括号表达式的开始 |
| 7 | ? 匹配前面子表达式零次或一次,或指明一个非贪婪限定符 |
| 8 | \ 将下一个字符标记为或特殊字符或原意字符或后向引用或八进制转义符。例如:‘n’匹配字符‘n’,而‘\n’匹配换行符。序列‘\’匹配’\’ |
还有一个就是split函数重写了java中的split函数,另外一种就是
def split(arg0: String, arg1: Int): Array[String]

可以看到当arg1大于0时,它限制arg0最多成功匹配arg1-1次,也就是说字符串最多被分成arg1个子串。此时split会保留分割出的空字符串(当两个arg0连续匹配或者arg0在头尾匹配,会产生空字符串),直到达到匹配上限。