一、K8S监控系统的发展史
第一版:Cadvisor+InfluxDB+Grafana
只能从主机维度进行采集,没有Namespace、Pod等维度的汇聚功能
第二版:Heapster+InfluxDB+Grafana
heapster负责调用各node中的cadvisor接口,对数据进行汇总,然后导到InfluxDB , 可以从cluster,node,pod的各个层面提供详细的资源使用情况。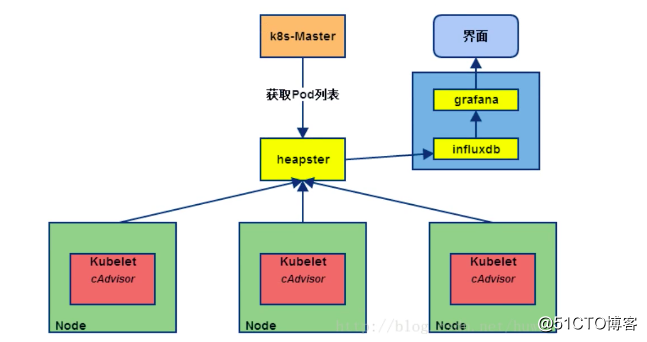
第三版:Metrics-Server + Prometheus
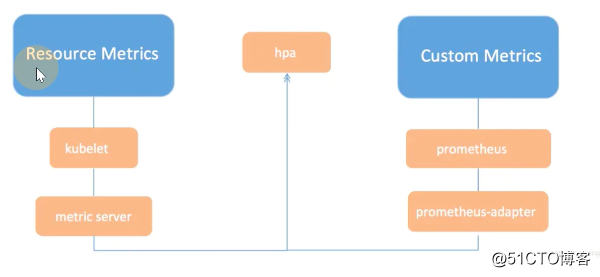
Metrics Server 与 Cadvsior 与 Cgroup 关系
Metrics Server 作为标准的 Kubernetes API 把监控数据暴露出来的服务,比如获取某一Pod的监控数据;无论是 heapster还是 metric-server,都只是数据的中转和聚合,两者都是调用的 kubelet 的 api 接口获取的数据,而 kubelet 代码中实际采集指标的是 cadvisor 模块;cadvisor获取指标时实际调用的是 runc/libcontainer库,而libcontainer是对 cgroup文件 的封装,即 cadvsior也只是个转发者,它的数据来自于cgroup文件。
cgroup文件中的值是监控数据的最终来源,
如:mem usage的值
对于docker容器来讲,来源于/sys/fs/cgroup/memory/docker/[containerId]/memory.usage_in_bytes
对于pod来讲,/sys/fs/cgroup/memory/kubepods/besteffort/pod[podId]/memory.usage_in_bytes
K8S进阶实践 之 通过HPA实现业务应用的动态扩缩容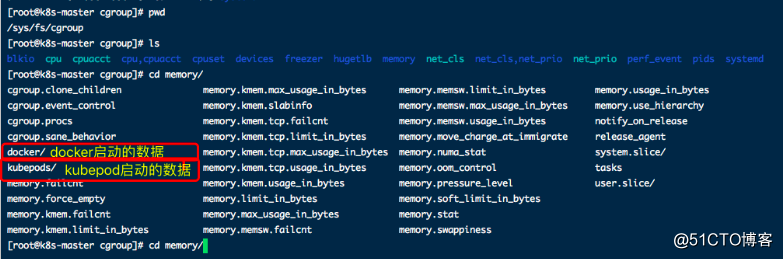
二、通用集群监控要求
- 内部系统组件的状态:比如 kube-apiserver、kube-scheduler、kube-controller-manager、kubedns/coredns 等组件的详细运行状态
- Kubernetes 节点的监控:比如节点的 cpu、load、disk、memory 等指标
- 业务容器指标的监控(容器CPU、内存、磁盘等)
- 编排级的 metrics:比如 Deployment 的状态、资源请求、调度和 API 延迟等数据指标