今天又读了一篇刘知远老师团队2015年在顶会Ijcai上发表的论文《Joint Learning of Character and Word Embeddings》,同样是有关于在词向量生成部分进行了改进,引入了词语组成成分的单个汉字的信息(论文主要针对的是中文),提升了词向量生成的质量。因为模型名称叫做“character-enhanced word embeddding model”,故模型简称为CWE。
从论文的题目可以看出,这篇paper在进行词向量训练的时候,讲词语中把组成词语的汉字单独抽取出来,和词语一起进行训练。这样就使那些共享汉字的词语之间产生了联系,因为paper的假设是“semantically compositional”的词语中的汉字对词语的意思具有一定的表征作用,比方说词语“智能”。但是在汉语中并不是所有的词语都是semantically compositional,比方说一些翻译过来的词语“巧克力”,“沙发”,再比方说一些实体的名称,比方说一些人名、地名和国家名。在这些词语中,单个汉字的意思可能和本来这个词语要表达的意思是完全没有关系的。在本篇paper中,作者做了大量的工作去把这些没有semantically compositional性质的词语全部人工的挑选出来,对于这些词语不去进行单个字的拆分处理。
这篇论文提出的模型,是在word2vec的CBOW基础之上进行改进的,模型整体的优化函数如下所示:
从中可以明显的看出,在CBOW模型中,context的表示是
介绍完了传统的CBOW模型之后,就要介绍这篇paper提出的模型,模型示意图如下所示:
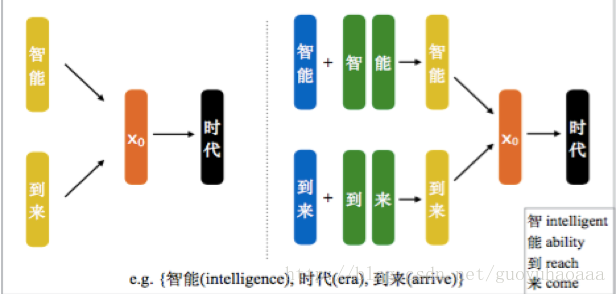
从上图可以清楚的看出,在传统的CBOW模型中,target word“时代”的context信息是直接把“智能”和“到来”的词向量形式进行相加;而在CWE模型中,对于context中的词语的表征,一方面来自于词向量,还有一部分在自于这些词语中的字的向量,具体的计算方式如下:
其中,
注意上述公式中的
上述只是一个大概的框架模型,还有一些细节问题没有考虑,其中最主要的一个问题就是:同一个汉字,在不同的词语中可能具有完全不同的语义,如果使用一个向量来表征一个字,那么很可能会无法标识出这些差异性,故使用多个向量来表征同一个汉字,有下面几种方式:
1 Position-based Character Embedding
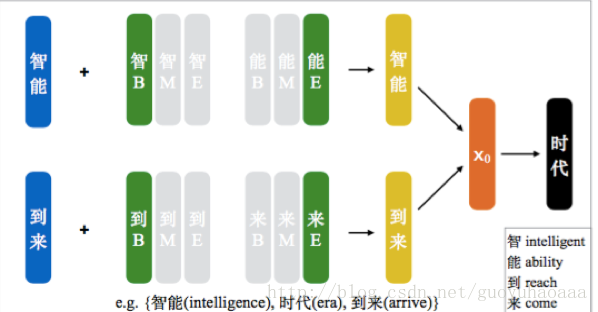
从名字可以看出,在该模型中同一个汉字根据其在词语中出现的位置不同,对应不同位置的向量表示形式。分析可知,汉字在词语中出现的位置有:Begin,Middle,End这三种情况,故每一个汉字都有三种向量表示形式,在进行
2 Cluster_based Character Embedding
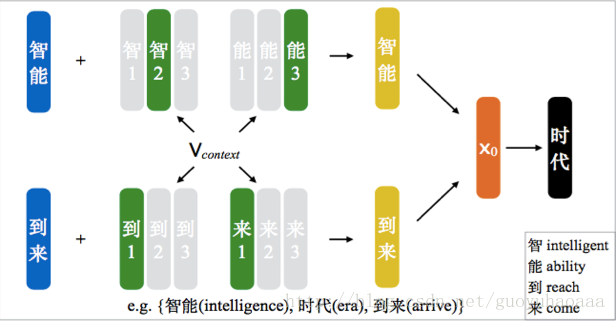
该模型运用了k-means算法思想的部分原理,也就是对于每一个汉字提前分配x个字向量,x的个数是模型的一个超参数,代表了潜在定义的每个汉字所对应的语义模式(我们也可以称之为模式向量)。至于在利用式子
其中
也就是说,在对汉字x进行模式向量筛选的时候,利用了该汉字对应词语的context信息,而context信息就是该汉字对应词语前后窗口内的2k个词语,而这些词语的向量形式由词向量和字向量叠加形成,只不过在挑选字向量的模式向量的时候,直接选了过去被挑选最多次的模式向量(这也是这篇paper里面一个比较大的具有缺陷的地方,为什么选取曾经被最多次选取的向量呢??这显然也是不合理的)。
利用context向量,从一个汉字的所有模式向量中选择一个和context语义计算上最相似的作为该汉字对应的向量。
3 Nonparametric Cluster-based Character Embeddings
该模型和2中的Cluster_based Character Embedding模型是很相似的,唯一不同的是,Cluster_based Character Embedding中的每一个汉字对应的模型向量的数量是一个预先设定的固定值,也就是作为模型的超参数。而在Nonparametric Cluster-based Character Embeddings模型中,该值是一个模型自动学习的值。我刚开始很好奇,我直观感觉模型怎么可能学习出这个参数来,后来看了具体的实现才恍然大悟,其具体方法如下式所示:
if(
else
也就是说还是计算汉字对应的所有模式向量(每个汉字在刚开始的时候会被分配初始的少量的模式向量)和context的语义相似度,当相似度小于一定阈值的时候,说明当前所有的模式向量都不太适合,那么就新添加一个更加适合的模式向量。这样来看每个汉字对应的模式向量个数,不仅仅与刚开始的初始数量有关,还和整个算法的计算过程有关。
总之作者通过大量的对比实验证明了该paper提出的模型,能够比传统的词向量生成策略word2vec和Glove提高性能。
下面是我认为比较有价值的作者的未来工作:
1 本文提出的汉字和词语结合的方式就是简单的向量相加操作,其实也许应用矩阵变换等方式可以把二者更加合理地结合在一起;
2 在相加的时候,需要给以每一个汉字不同权重,这也和我之前说的一致,可以利用attention机制,只不过在2015年的时候还没有attention的概念。
ps:最后这篇paper一句话解决我的一个困惑,就是为什么大家再生成词向量的时候选择的方法从来都不考虑Bengio刚开始提出的那个比较复杂的模型:“The training process of most previous word embedding models exhibits high computational complexity, which makes them unable to work for large-scale text corpora efficiently.”
总之一句话,就是Bengio提出的模型太复杂了,不适合训练大规模语料。