我们已经了解了数据库事务隔离级别脏读,虚读,不可重复读,不过想要更好的对数据库操作,提高数据库读写的性能,我们还需要了解数据库的另一个机制---数据库锁!
其实,刚刚使用mysql数据库不久的伙伴,对数据库锁可能没啥概念,而且可能还有疑问,难道数据库会死锁?没见过啊,死锁了数据库不就GG了么?首先要确认一个东西,那就是数据库当然会死锁,既然有事务,有隔离,有并发,逻辑一旦处理不好,死锁肯定是会发生的。
至于大多数小伙伴没遇到过,一个是因为你可能接触的业务并发不是特别高,业务逻辑不是特别复杂,还有一个重要的原因就是数据库内部有一个监测死锁的机制,一旦发现数据库死锁,就会触发回退操作,不会让数据库真的宕机。
下面我们来认识下数据库的锁,既然是数据隔离,高并发情况下操作数据,肯定是要加锁的,要不然就乱套了。等我们认识了锁,那死锁机制对我们来说就很简单了,而且,可以轻易的写出一个死锁的业务操作,就像使用java代码实现死锁一样,嘿嘿。
我们知道java中的锁(常见的)一般是乐观锁(CAS),继承AQS实现的锁通过阻塞对垒实现的锁,还有就是Synchronized的监视器实现的锁。那么MySQL呢?java是一种语言,主要针对的是数据逻辑或者说运行程序需要的资源进行加锁,锁的主要是资源,而MySQL数据库呢?这是一个关系型数据库,其中的锁主要是对数据的锁定,防止出现脏读等事件,所以两者的锁肯定是有差别的。
我们来看下MySQL的锁,主要是行锁(Record Locks),间隙锁(临键锁),意向锁(Insert Intention Locks),自增锁(Auto-inc Locks)等,下面我们来展开说下。
1.行锁
我们先建立一个数据表,这样看着操作说,更清楚一些。下面是建表和几条数据的sql语句。
CREATE TABLE `student` (
`id` int(10) NOT NULL AUTO_INCREMENT COMMENT 'id主键',
`age` int(11) NULL DEFAULT NULL COMMENT '年龄',
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NULL DEFAULT NULL COMMENT '名称',
`id_card` varchar(255) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL COMMENT '身份证号',
`stage` varchar(255) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL COMMENT '等级',
`create_date` datetime(0) NULL DEFAULT NULL COMMENT '创建日期',
PRIMARY KEY (`id`) USING BTREE,
UNIQUE INDEX `idx_card`(`id_card`) USING BTREE COMMENT '唯一索引--身份编号',
INDEX `idx_stage`(`stage`) USING BTREE COMMENT '普通索引--等级索引'
) ENGINE = InnoDB AUTO_INCREMENT = 13 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci COMMENT = '个人测试索引-学生表' ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of student
-- ----------------------------
INSERT INTO `student` VALUES (1, 16, '张三', '110120200402023456', '9', '2020-10-21 14:07:15');
INSERT INTO `student` VALUES (2, 16, '张三加', '110120200402023454', '9', '2020-10-21 14:07:15');
INSERT INTO `student` VALUES (3, 16, '张四', '110120200402023457', '8', '2020-10-21 14:07:15');
INSERT INTO `student` VALUES (4, 16, '张五', '110120200402023458', '7', '2020-10-21 14:07:15');
INSERT INTO `student` VALUES (5, 16, '张六', '110120200402023459', '6', '2020-10-21 14:07:15');
INSERT INTO `student` VALUES (6, 16, '张七', '110120200402023460', '5', '2020-10-21 14:07:15');
INSERT INTO `student` VALUES (7, 16, '张八', '110120200402023465', '4', '2020-10-21 14:07:15');
INSERT INTO `student` VALUES (8, 16, '张九', '110120200402023466', '15', '2020-10-21 14:07:15');
INSERT INTO `student` VALUES (9, 16, '张氏', '110120200402023467', '16', '2020-10-21 14:07:15');
INSERT INTO `student` VALUES (10, 16, '李四', '110120200402023480', '18', '2020-10-21 14:07:15');
INSERT INTO `student` VALUES (11, 16, '李五', '110120200402023481', '19', '2020-10-21 14:07:15');
INSERT INTO `student` VALUES (12, 16, '李六', '110120200402023482', '20', '2020-10-21 14:07:15');
截个图吧,看着清楚些哈~

进行讲解锁之前我们先了解接隔离级别的查看,就是下面这个语句:
select @@tx_isolation as 当前隔离级别 ,@@global.tx_isolation as 全局隔离级别;
事务的隔离级别对锁是有影响的哦,在进行锁操作之前,建议大家最好查看下事务的隔离级别,当然MySQL默认的就是REPEATABLE-READ
好了,我们来看下这几条sql语句 。
-- 开启事务A
START TRANSACTION;
-- id=7的数据
SELECT * FROM student where id=7 for UPDATE;
-- --上半部分
-- ----------
-- --下半部分
ROLLBACK;
-- ----最好在可视化工具的两个查询页面,方便看结果
-- 启动事务B
START TRANSACTION ;
-- id=7的数据
SELECT * FROM student where id=7 for UPDATE;
-- --上半部分
-- ----------
-- --下半部分
ROLLBACK;我们知道查询语句后面加上for update,就是对整个student表加入了意向锁(下边说),然后对id=7的记录加上了独占锁,锁了住查询的结果数据,其实很明显,for update(为了修改)你都想修改了,肯定不允许其他人修改了,不然一起修改还不乱了套。
我们运行事务A 的上半部分,就是锁住了id=7的这条数据,事务A未结束。然后启动事务B,再次去查询李四(for update),我们会发现无法查询到李四的数据,事务一直在运行,也没有报错信息的,其实就是在等待,等待事务A结束(提交或者回滚)。当然如果事务B去查询id=8的数据肯定是没有问题的。
其实这个时候对 id=7 这条数据加锁加的就是行锁。
我们来看下行锁的官方描述A record lock is a lock on an index record(行锁一定是作用在索引上的)。
student表的id(建表的时候就加了聚簇索引),idx_card,idx_stage都是是加了索引的,如果以这些条件进行加锁操作,是会锁住这一条数据的。
行锁分为两种:
-
共享锁(S) 共享锁也称为读锁,读锁允许多个连接可以同一时刻并发的读取同一资源,互不干扰;
-
排他锁(X) 排他锁也称为写锁,一个写锁会阻塞其他的写锁或读锁,保证同一时刻只有一个连接可以写入数据,同时防止其他用户对这个数据的读写。
让然如果条件是name这种没有加索引的字段,想要锁住一条数据的话,那只能使用表锁了,这样的话就比较消耗资源,而且容易发生死锁的。
2.间隙锁
我们刚刚看了以索引条件进行查询,会进行行锁那么,什么是间隙锁呢?我们来看下下面几条语句。
-- 开启事务A
START TRANSACTION;
-- id_card大于'110120200402023465',小于'110120200402023481'的数据
SELECT * FROM student where id_card>'110120200402023465' and id_card <'110120200402023481' for UPDATE
-- --上半部分
-- ----------
-- --下半部分
ROLLBACK;
-- -----------------------------------------------------------
-- 启动事务B
START TRANSACTION ;
-- 删除 id_card='110120200402023481' 的数据
DELETE FROM student where id_card='110120200402023481';
-- --上半部分
-- ----------
-- --下半部分
ROLLBACK;运行事务A的上半部分,锁住了id_card大于'110120200402023465',小于'110120200402023481'的数据,这个时候id_card大于'110120200402023465',小于'110120200402023481',这个数据段是被锁住的,如果插入id_card=110120200402023469的数据,肯定是失败的。
但是如果运行事务B的上半部分呢?id_card小于'110120200402023481',是不是'110120200402023481'没有被锁住呢?当然不是,大家执行下SQL语句,会发现事务B一直在等待,直到事务A rollback 之后,事务B才能够继续运行,很明显小id_card数据为'110120200402023481'的这条数据被锁住了。
查询相关概念,我们会发现,间隙锁锁住的策略是左开右闭,当你锁定一个区间时,左侧的数据没有被锁住,右侧的数据是被锁住的。所以事务A锁住的区间是('110120200402023465','110120200402023481'],大家可以试一下,事务B如果操作id_card=110120200402023465这条数据的话,是没有被锁住的。
有了间隙锁,锁住了某一段,这样进行一些控制,其实就能避免幻读的发生,同时有进行了最小范围的锁定,保证了数据库性能。
当然间隙锁针对的也是索引,没有索引的话也是直接锁表的。
3.意向锁
为了支持多粒度锁机制(multiple granularity locking),即允许行级锁与表级锁共存,而引入了意向锁(intention locks)。意向锁是指,未来的某个时刻,事务可能要加共享/排它锁了,先提前声明一个意向。
SELECT * FROM student where id_card>'110120200402023465' and id_card <'110120200402023481' for UPDATE
这个其实就是一个意向锁。
- 意向锁是一个表级别的锁(table-level locking);
- 意向锁又分为:
- 意向共享锁(intention shared lock, IS),它预示着,事务有意向对表中的某些行加共享S锁
- 意向排它锁(intention exclusive lock, IX),它预示着,事务有意向对表中的某些行加排它X锁
语法:
select ... lock in share mode; 要设置IS锁;
select ... for update; 要设置IX锁;
下面是意向锁与S锁与X锁的互斥关系
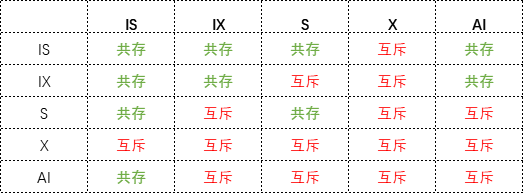
至于自增锁,我想大家都用过,每次建表的时候我们的id一般都是设置成自增的,这里其实就加了一个自增锁。
好了,数据库锁就简单的说到这里啦。
No sacrifice,no victory~