介绍一下innodb的锁吧?
乐观锁和悲观锁。
行锁和表锁。
innodb行锁的三种算法。
mvcc和非锁定一致性读。
innodb通过过期时间内没有获取锁来检测死锁,死锁条件,预防死锁,解决死锁。
===乐观锁悲观锁概念
乐观锁就是不加锁,悲观锁就是加锁。
乐观锁:一种机制。乐观锁认为一个事务读数据的时候,别的事务不会去写自己所读的数据;所以不会上锁但是在更新操作的时候会判断一下在此期间有没有人去修改这个数据,比较适合读多的情况。比如Atomic包的原子类就是用CAS来实现乐观锁。
悲观锁:一种机制。就刚好相反,觉得自己读数据库的时候,别人可能刚好在写自己刚读的数据,其实就是持一种比较保守的态度;所以悲观锁不论读写都对数据上锁(具体的数据库锁),不让其他的数据库操作对数据进行修改或者读取。比如mysql的innodb使用的表锁,页锁行锁都是,java中的synchronized获取对象monitor也是一种悲观锁的实现方式。
时间戳:时间戳就是在数据库表中单独加一列时间戳,比如“TimeStamp”,每次读出来的时候,把该字段也读出来,当写回去的时候,把该字段加1,提交之前 ,跟数据库的该字段比较一次,如果比数据库的值大的话,就允许保存,否则不允许保存
===简述innodb的行级锁和表级锁特点。
行级锁:粒度最小的锁,对事务操作的数据行进行加锁。分为共享锁和独占锁。
特点:
缺点1.开销大,加锁慢;会出现死锁;
优点2.锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
3.innodb默认使用行锁,但是innodb只对索引字段加行锁,所以只有在用索引字段搜索的时候才使用行锁,否则使用表锁。
===怎么使用行锁,最佳实践?
1.行锁锁的是索引,所以数据检索尽量用索引,避免跳到表锁降低并发量。
2.减少范围检索,因为会用到间隙锁锁住范围。
3.控制事务大小,减少锁定的资源量和时间。
4.尽量使用低级别的事务隔离级别提高并发性。
===什么时候用表锁?
1.涉及大范围数据增删改。
2.涉及多张表的复杂情况。
===innodb支持哪两种锁呢?按照锁的粒度来分,什么是意向锁?
共享锁,也就是读锁,一个事务在读取某些数据行的时候加读锁,其他事务也能够同时读取。
排它锁,写锁,一个事务在修改数据行的时候加排它锁,其他事务不能够读取或者修改这些数据行。
因为i
非锁定一致性读
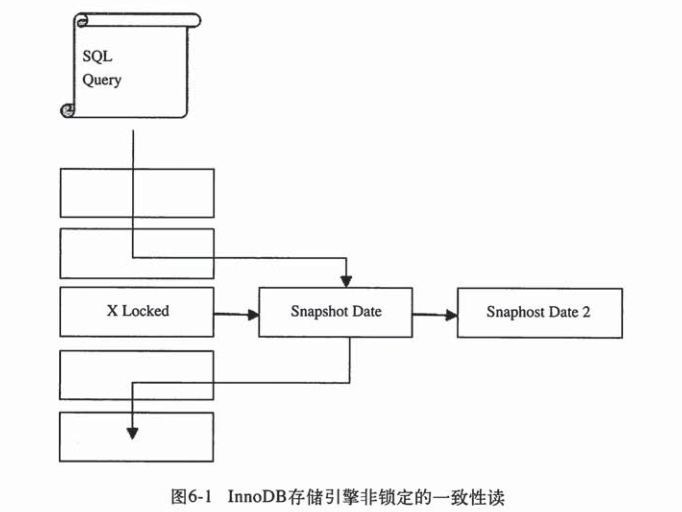
===innodb对读操作有什么优化的措施呢?解释innodb的一致性非锁定读,读取快照的方式是什么样的?在不同的事务隔离级别下的优化方式?如何提升读的并发性能呢?
非锁定一致性读是innodb对读操作的一种优化。当事务去读取加了写锁的数据的时候,会读取undo快照的数据。这个时候的读操作是不加锁的!!
undo区域用于事务回滚,保存了不同版本的数据的快照,因为有个事务在一直同步的修改这个数据。这个叫MVCC多版本并发控制。不同隔离级别下面读取的快照数据是不一样的。
1.如果是erializalbe的隔离级别下,读取数据会加lock in share mode,也就是说读操作会加共享锁,所以在这种隔离级别下innodb对读的这种优化措施就没有了。
2.repeatable这种级别下,不会有脏读,幻读和不可重复读的问题,因为它不读取已经提交或者新增的数据,所以他会读取快照中最早的那个数据。
3.read commited读提交,他只能够防止脏读,也就是说会读取新增的或者修改的数据,所以他会读取快照中最新的数据。
两种select锁
===innodb的select语句可以加哪些锁?
select可以加两种锁,同时必须在事务中加这个锁。
1.select ...for update 独占锁写锁
2.select ... lock in share mode 加共享锁读锁
但是对于一致性非锁定读,即使加了锁也是可以进行读取的。
===innodb锁的算法有哪几种?
注意,锁的算法分别可以在共享和独占模式下使用!!
算法有三种
1.record lock:锁定行记录,其实锁的就是索引。
2.gap lock:锁定范围不锁住行,防止多个事务同时插入某个范围。
3.next-key lock:锁定行并且锁定范围。比如说一个索引10,11,13,20那么这些个索引被锁定的区间可能是(-00,10)(10,11】(11,13](13,20](20,+00)这几个区间。
---innodb对于行的查询默认使用的就是next-key的算法,但是会有优化的部分?什么时候触发锁降级?
例子:表中有1,2,5三个索引值,a事务查询5,b事务插入4,默认情况下a事务会锁定(2,5)这个范围,但是因为是唯一索引,所以只会锁定5这个值,插入4完全不会被阻塞。
===innodb什么时候会使用到行锁呢?默认用的是什么算法呢?
行锁锁的是索引。
innodb行锁是通过给索引上的索引项加锁来实现的。只有通过索引条件检索数据的时候innodb才会使用到行级锁。、
同时默认使用的是next-key lock算法,锁的是某个数据范围。
===innodb如何解决幻读的问题呢?innodb默认的它的隔离级别是什么呢?
innodb默认隔离级是repeatable-read
innodb在事务隔离级别为repeatable-read的情况下,仍然能够避免幻读的问题,就是因为使用了next key-lock锁机制,锁住一个范围,这点和oracle是不一样的,oracle需要在serializable下才能够解决幻读的问题。
举例说明:1,2,5三个索引值,查>2的索引值,这个时候不是使用record lock行锁,而是使用next-key locking范围锁锁住>2的所有部分,从而避免了幻读的问题,next-key lock锁范围是一种无穷范围锁。
===行锁为什么会发生死锁问题?为什么表锁不会发生死锁问题呢?
表锁总是一次性获取所有的锁,所以不会出现死锁问题。
行锁锁的是索引,索引又分成主键索引和非主键索引,不同的事务对不同的索引进行加锁的时候可能就会出现死锁的问题了。
死锁解决方式:释放其中一个事务的锁定,使得另一个事务获取锁。
===innodb是如何解决死锁的问题的呢?就是死锁了后怎么处理。
死锁的时候会进行事务回滚,会回滚对undo区域占据最少的事务。
===为什么需要进行锁升级呢?
锁升级的意思是将锁的粒度降低,锁的粒度降低对于锁的维护性能有帮助,但是锁升级会降低数据库的并发能力。
因为如果维护太多的行锁需要很大的内存消耗,其实innodb不是单纯的维护行锁,而是维护事务访问数据的页锁,所以事务锁住一条记录还是一页记录开销都是一样。
并发下关于锁的问题:
活锁:活锁指的是T1封锁了数据R,T2同时也请求封锁数据R,T3也请求封锁数据R,当T1释放了锁之后,T3会锁住R,T4也请求封锁R,则T2就会一直等待下去,这种处理方法就是采用“先来先服务”策略;
死锁:死锁就是我等你,你又等我,双方就会一直等待下去,比如:T1封锁了数据R1,正请求对R2封锁,而T2封住了R2,正请求封锁R1,这样就会导致死锁
如何预防死锁问题:
1.一次封锁。将所要的数据一次性全部加锁,会降低并发能力,用行锁不用表锁。
2.顺序加锁。将并发事务按照使用顺序对数据加锁
3.用表锁。
如何检测到发生了死锁问题:
1.超时法
2.事务等待图
如何解决死锁的问题?
撤销损失最小的那个事务,把锁释放出来。