文章标题
前文-MySql-锁与事物
gap锁与慢查询
gap锁
其实在 mysql 中,可重复读已经解决了幻读问题,借助的就是间隙锁
实验 1:
select @@tx_isolation;
create table t_lock_1 (a int primary key);
insert into t_lock_1 values(10),(11),(13),(20),(40);
begin select * from t_lock_1 where a <= 13 for update;
在另外一个会话中 insert into t_lock_1 values(21) 成功 insert into t_lock_1 values(19) 阻塞
在 rr 隔离级别中者个会扫描到当前值(13)的下一个值(20),并把这些数据全部加锁
实验:2
create table t_lock_2 (a int primary key,b int, key (b));
insert into t_lock_2 values(1,1),(3,1),(5,3),(8,6),(10,8);
会话 1
BEGIN
select * from t_lock_2 where b=3 for update;
1 3 5 8 10
1 1 3 6 8
会话 2
select * from t_lock_2 where a = 5 lock in share mode; -- 不可执行,因为 a=5 上有一把记录锁
insert into t_lock_2 values(4, 2); -- 不可以执行,因为 b=2 在(1, 3]内
insert into t_lock_2 values(6, 5); -- 不可以执行,因为 b=5 在(3, 6)内
insert into t_lock_2 values(2, 0); -- 可以执行,(2, 0)均不在锁住的范围内
insert into t_lock_2 values(6, 7); -- 可以执行,(6, 7)均不在锁住的范围内
insert into t_lock_2 values(9, 6); -- 可以执行
insert into t_lock_2 values(7, 6); -- 不可以执行
二级索引锁住的范围是 (1, 3],(3, 6)
主键索引只锁住了 a=5 的这条记录 [5]
事务语法
开启事务
1、begin
2、START TRANSACTION(推荐)
3、begin work
事务回滚
rollback
事务提交
commit
还原点(演示)
savepoint
show variables like '%autocommit%'; 自动提交事务是开启的
set autocommit=0; insert into testdemo values(5,5,5);
savepoint s1;
insert into testdemo values(6,6,6);
savepoint s2;
insert into testdemo values(7,7,7);
savepoint s3;
select * from testdemo
rollback to savepoint s2 rollback
业务设计
逻辑设计
范式设计
数据库设计的第一大范式
数据库表中的所有字段都只具有单一属性
单一属性的列是由基本数据类型所构成的
设计出来的表都是简单的二维表
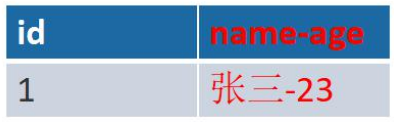
name-age 列具有两个属性,一个 name,一个 age 不符合第一范式,把它拆分成两列

数据库设计的第二大范式
要求表中只具有一个业务主键,也就是说符合第二范式的表不能存在非主键列只对部分 主键的依赖关系
有两张表:订单表,产品表
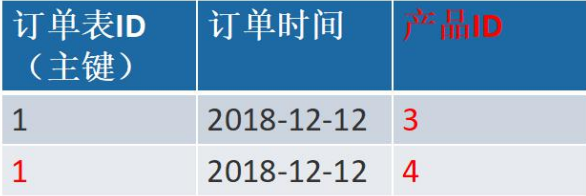
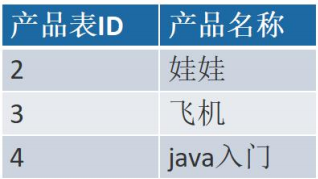
一个订单有多个产品,所以订单的主键为【订单 ID】和【产品 ID】组成的联合主键,这样 2 个组件不符合第二范式,而且产品 ID 和订单 ID 没有强关联,故,把订单表进行拆分为订单 表与订单与商品的中间表
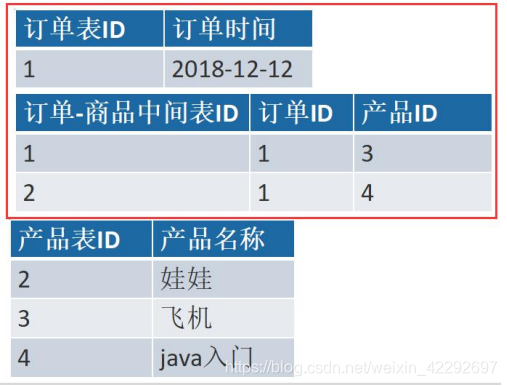
数据库设计的第三大范式
指每一个非非主属性既不部分依赖于也不传递依赖于业务主键,也就是在第二范式的基 础上相处了非主键对主键的传递依赖
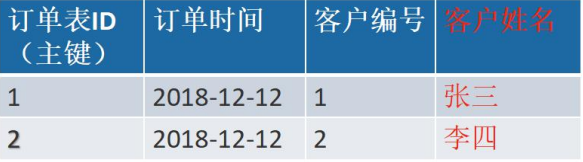
其中客户编号 和订单编号管理 关联
客户姓名 和订单编号管理 关联
客户编号 和 客户姓名 关联
如果客户编号发生改变,用户姓名也会改变,这样不符合第三大范式,应该把客户姓名这一 列删除
查询测试
编写 SQL 查询出每一个用户的订单总金额(用户名,订单总金额)

编写 SQL 查询出下单用户和订单详情(订单编号,用户名,手机号,商品名称,商品数量,
商品价格)

问题: 大量的表关联非常影响查询的性能
完全符合范式化的设计有时并不能得到良好得 SQL 查询性能
反范式设计
什么叫反范式化设计
- 反范式化是针对范式化而言得,在前面介绍了数据库设计得范式
- 所谓得反范式化就是为了性能和读取效率得考虑而适当得对数据库设计范式得要求进 行违反
- 允许存在少量得冗余,换句话来说反范式化就是使用空间来换取时间
总结
不能完全按照范式得要求进行设计
考虑以后如何使用表
范式化设计优缺点
优点:
可以尽量得减少数据冗余
范式化的更新操作比反范式化更快
范式化的表通常比反范式化的表更小
缺点:
对于查询需要对多个表进行关联
更难进行索引优化
反范式化设计优缺点
优点:
可以减少表的关联
可以更好的进行索引优化
缺点:
存在数据冗余及数据维护异常
对数据的修改需要更多的成本
物理设计
命名规范
数据库、表、字段的命名要遵守可读性原则
使用大小写来格式化的库对象名字以获得良好的可读性
例如:使用 custAddress 而不是 custaddress 来提高可读性。
数据库、表、字段的命名要遵守表意性原则
对象的名字应该能够描述它所表示的对象
例如: 对于表,表的名称应该能够体现表中存储的数据内容;
对于存储过程 存储过程应该能够体现存储过程的功能。
数据库、表、字段的命名要遵守长名原则
尽可能少使用或者不使用缩写
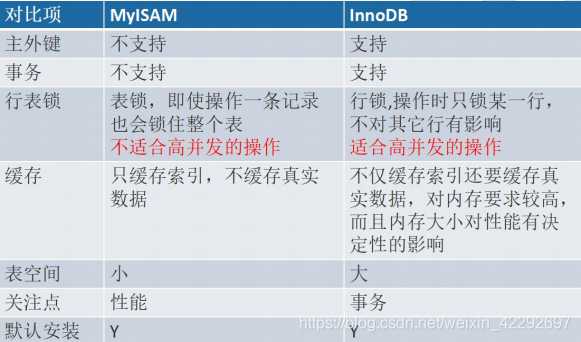
存储引擎选择
数据类型选择
当一个列可以选择多种数据类型时 优先考虑数字类型 其次是日期、时间类型 最后是字符类型 对于相同级别的数据类型,应该优先选择占用空间小的数据类型
浮点类型

日期类型
面试经常问道 timestamp 类型 与 datetime 区别
datetime 类型在 5.6 中字段长度是 5 个字节
datetime 类型在 5.5 中字段长度是 8 个字节
timestamp 和时区有关,而 datetime 无关
慢查询
什么是慢查询
慢查询日志,顾名思义,就是查询慢的日志,是指 mysql 记录所有执行超过 long_query_time 参数设定的时间阈值的 SQL 语句的日志。该日志能为 SQL 语句的优化带来很好的帮助。默 认情况下,慢查询日志是关闭的,要使用慢查询日志功能,首先要开启慢查询日志功能。
慢查询配置
慢查询基本配置
- slow_query_log 启动停止技术慢查询日志
- slow_query_log_file 指定慢查询日志得存储路径及文件(默认和数据文件放一起)
- long_query_time 指定记录慢查询日志 SQL 执行时间得伐值(单位:秒,默认 10 秒)
- log_queries_not_using_indexes 是否记录未使用索引的 SQL
- log_output 日志存放的地方【TABLE】【FILE】【FILE,TABLE】
配置了慢查询后,它会记录符合条件的 SQL
包括: - 查询语句
- 数据修改语句
- 已经回滚得 SQL
实操:
通过下面命令查看下上面的配置:
show VARIABLES like '%slow_query_log%'
show VARIABLES like '%slow_query_log_file%'
show VARIABLES like '%long_query_time%'
show VARIABLES like '%log_queries_not_using_indexes%'
show VARIABLES like 'log_output'
set global long_query_time=0; ---默认 10 秒,这里为了演示方便设置为 0
set GLOBAL slow_query_log = 1; --开启慢查询日志
set global log_output='FILE,TABLE' --项目开发中日志只能记录在日志文件中,不能记表中
设置完成后,查询一些列表可以发现慢查询的日志文件里面有数据了。
cat /usr/local/mysql/data/mysql-slow.log
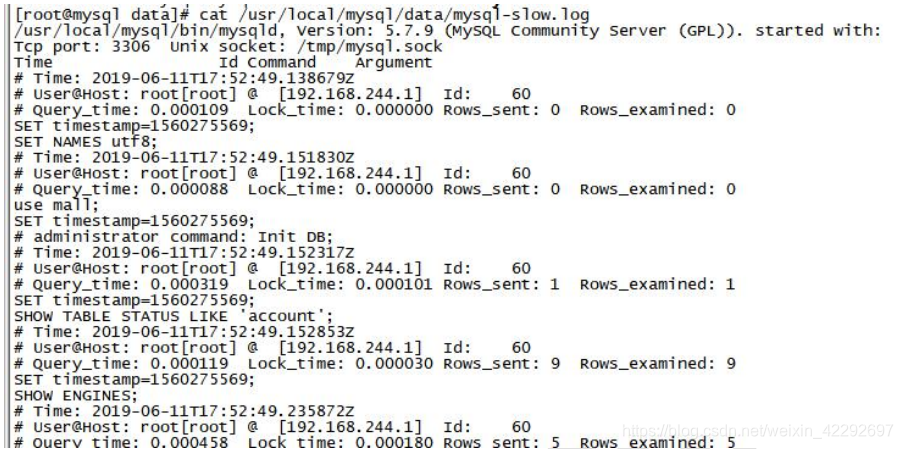
慢查询解读
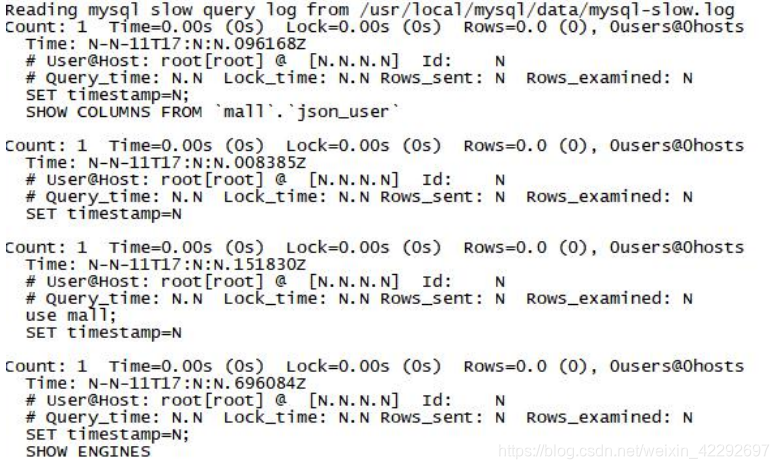
从慢查询日志里面摘选一条慢查询日志,数据组成如下

解读,慢查询格式显示
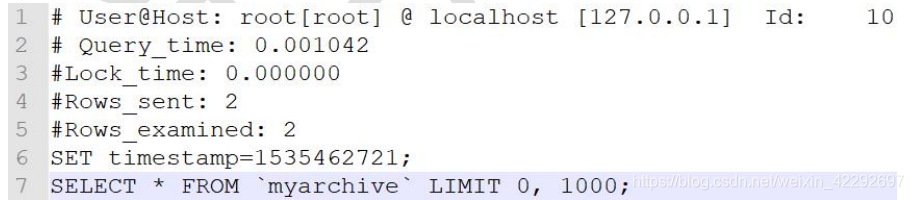
第一行:用户名 、用户的 IP 信息、线程 ID 号
第二行:执行花费的时间【单位:毫秒】
第三行:执行获得锁的时间
第四行:获得的结果行数
第五行:扫描的数据行数
第六行:这 SQL 执行的具体时间
第七行:具体的 SQL 语句
慢查询分析
慢查询的日志记录非常多,要从里面找寻一条查询慢的日志并不是很容易的事情,一般来说 都需要一些工具辅助才能快速定位到需要优化的 SQL 语句,下面介绍两个慢查询辅助工具
Mysqldumpslow
常用的慢查询日志分析工具,汇总除查询条件外其他完全相同的 SQL,并将分析结果按照参 数中所指定的顺序输出。
语法:
mysqldumpslow -s r -t 10 slow-mysql.log
-s order (c,t,l,r,at,al,ar)
c:总次数
t:总时间
l:锁的时间
r:总数据行
at,al,ar :t,l,r 平均数 【例如:at = 总时间/总次数】
-t top 指定取前面几天作为结果输出
mysqldumpslow -s t -t 10 /usr/local/mysql/data/mysql-slow.log
pt_query_digest
是 用 于 分 析 mysql 慢 查 询 的 一 个 工 具 , 与 mysqldumpshow 工 具 相 比 , py-query_digest 工具的分析结果更具体,更完善。
有时因为某些原因如权限不足等,无法在服务器上记录查询。
这样的限制我们也常常碰 到。首先来看下一个命令
包分享
提取码:s0tl
yum -y install 'perl(Data::Dumper)';
yum -y install perl-Digest-MD5
yum -y install perl-DBI
yum -y install perl-DBD-MySQL
perl ./pt-query-digest --explain h=127.0.0.1,u=root,p=root1234% /usr/local/mysql/data/mysql-slow.log
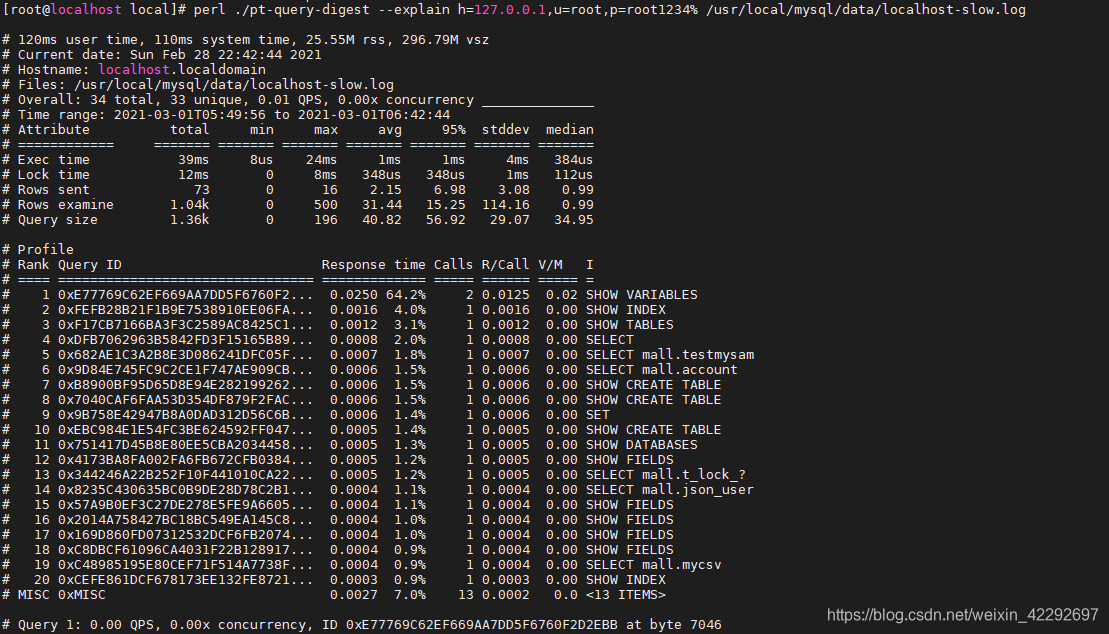
汇总的信息【总的查询时间】、【总的锁定时间】、【总的获取数据量】、【扫描的数据量】、【查 询大小】
Response: 总的响应时间。
time: 该查询在本次分析中总的时间占比。
calls: 执行次数,即本次分析总共有多少条这种类型的查询语句。
R/Call: 平均每次执行的响应时间。
Item : 查询对象
扩展阅读:
语法及重要选项
pt-query-digest [OPTIONS] [FILES] [DSN]
- –create-review-table 当使用–review 参数把分析结果输出到表中时,如果没有表就自动 创建。
- –create-history-table 当使用–history 参数把分析结果输出到表中时,如果没有表就自动 创建。
- –filter 对输入的慢查询按指定的字符串进行匹配过滤后再进行分析
- –limit 限制输出结果百分比或数量,默认值是 20,即将最慢的 20 条语句输出,如果是 50%则按总响应时间占比从大到小排序,输出到总和达到 50%位置截止。
- –host mysql 服务器地址 --user mysql 用户名
- –password mysql 用户密码 --history 将分析结果保存到表中,分析结果比较详细,下次再使用–history 时,如果存 在相同的语句,且查询所在的时间区间和历史表中的不同,则会记录到数据表中,可以 通过查询同一 CHECKSUM 来比较某类型查询的历史变化。
- –review 将分析结果保存到表中,这个分析只是对查询条件进行参数化,一个类型的查 询一条记录,比较简单。当下次使用–review 时,如果存在相同的语句分析,就不会记 录到数据表中。
- –output 分析结果输出类型,值可以是 report(标准分析报告)、slowlog(Mysql slow log)、 json、json-anon,一般使用 report,以便于阅读。
- –since 从什么时间开始分析,值为字符串,可以是指定的某个”yyyy-mm-dd [hh:mm:ss]” 格式的时间点,也可以是简单的一个时间值:s(秒)、h(小时)、m(分钟)、d(天),如 12h 就表示从 12 小时前开始统计。
- –until 截止时间,配合—since 可以分析一段时间内的慢查询。
分析 pt-query-digest 输出结果
第一部分:总体统计结果
- Overall:总共有多少条查询
- Time range:查询执行的时间范围
- unique:唯一查询数量,即对查询条件进行参数化以后,总共有多少个不同的查询
- total:总计 min:最小 max:最大 avg:平均
- 95%:把所有值从小到大排列,位置位于 95%的那个数,这个数一般最具有参考价值
- median:中位数,把所有值从小到大排列,位置位于中间那个数
# 该工具执行日志分析的用户时间,系统时间,物理内存占用大小,虚拟内存占用大小
# 340ms user time, 140ms system time, 23.99M rss, 203.11M vsz
# 工具执行时间 # Current date: Fri Nov 25 02:37:18 2016 # 运行分析工具的主机名
# Hostname: localhost.localdomain
# 被分析的文件名 # Files: slow.log
# 语句总数量,唯一的语句数量,QPS,并发数
# Overall: 2 total, 2 unique, 0.01 QPS, 0.01x concurrency
# 日志记录的时间范围 # Time range: 2016-11-22 06:06:18 to 06:11:40
# 属性 总计 最小 最大 平均 95% 标准 中等
# Attribute total min max avg 95% stddev median
# ============ ======= ======= ======= ======= ======= ======= =======
# 语句执行时间
# Exec time 3s 640ms 2s 1s 2s 999ms 1s
# 锁占用时间
# Lock time 1ms 0 1ms 723us 1ms 1ms 723us
# 发送到客户端的行数
# Rows sent 5 1 4 2.50 4 2.12 2.50
# select 语句扫描行数
# Rows examine 186.17k 0 186.17k 93.09k 186.17k 131.64k 93.09k
# 查询的字符数
# Query size 455 15 440 227.50 440 300.52 227.50
第二部分:查询分组统计结果
- Rank:所有语句的排名,默认按查询时间降序排列,通过–order-by 指定
- Query ID:语句的 ID,(去掉多余空格和文本字符,计算 hash 值)
- Response:总的响应时间
- time:该查询在本次分析中总的时间占比
- calls:执行次数,即本次分析总共有多少条这种类型的查询语句
- R/Call:平均每次执行的响应时间
- V/M:响应时间 Variance-to-mean 的比率
- Item:查询对象
# Profile # Rank Query ID Response time Calls R/Call V/M Item
# ==== ================== ============= ===== ====== ===== ===============
# 1 0xF9A57DD5A41825CA 2.0529 76.2% 1 2.0529 0.00 SELECT
# 2 0x4194D8F83F4F9365 0.6401 23.8% 1 0.6401 0.00 SELECT wx_member_base
第三部分:每一种查询的详细统计结果
由下面查询的详细统计结果,最上面的表格列出了执行次数、最大、最小、平均、95%等各 项目的统计。
- ID:查询的 ID 号,和上图的 Query ID 对应
- Databases:数据库名 Users:各个用户执行的次数(占比)
- Query_time distribution :查询时间分布, 长短体现区间占比,本例中 1s-10s 之间查询 数量是 10s 以上的两倍。
- Tables:查询中涉及到的表
- Explain:SQL 语句
# Query 1: 0 QPS, 0x concurrency, ID 0xF9A57DD5A41825CA at byte 802
# This item is included in the report because it matches --limit. # Scores: V/M = 0.00
# Time range: all events occurred at 2016-11-22 06:11:40
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
# Count 50 1 # Exec time 76 2s 2s 2s 2s 2s 0 2s
# Lock time 0 0 0 0 0 0 0 0 # Rows sent 20 1 1 1 1 1 0 1
# Rows examine 0 0 0 0 0 0 0 0 # Query size 3 15 15 15 15 15 0 15 # String:
# Databases test # Hosts 192.168.8.1 # Users mysql # Query_time distribution
# 1us
# 10us
# 100us
# 1ms
# 10ms
# 100ms
# 1s ################################################################
# 10s+
# EXPLAIN /*!50100 PARTITIONS*/
select sleep(2)\G