最近基友给了我一个任务:根据高管团队任职情况计算该团队的稳定性。
他提供的计算稳定性的算法有两种,第一种借鉴了Crutchley等(2002)、于东智和池国华(2004)等的做法,用如下公式
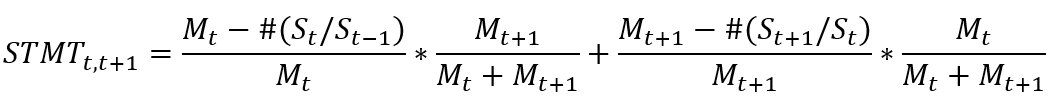
表示第t年到第t+1年间该团队的稳定性,STMT取值范围为[0,1],越接近1表示该团队的稳定性越高。![]() 表示t年在任的高管总人数,
表示t年在任的高管总人数,![]() 表示在t年在任但t+1年离任(不在任)的高管人数,
表示在t年在任但t+1年离任(不在任)的高管人数,![]() 表示在t年不在任但在t+1在任(新增)的高管人数。
表示在t年不在任但在t+1在任(新增)的高管人数。
第二种则稍微修改如下:
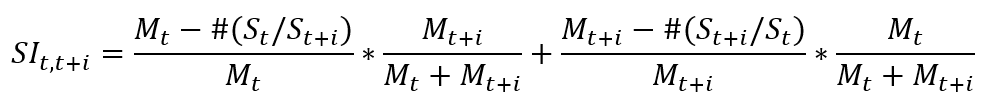
表示t年到t+i年间的稳定性。
和基友讨论过,对一些情况的界定如下:
- 对“高管人数”的界定:高管人数统计的是职位数(比如可能存在一人兼数职的情况,这样视作多个“高管”),而不是在位的员工数量。
- 对“高管”的界定:他给我提供的资料中提到,“包括董事长、董事、总经理、副总经理等,不包括外部董事和独立董事。”这个“等”具体包括什么很难说,查看数据获知,里边的职位五花八门,上千多个,还包括出纳、会计、厂长、组长等可能不算作是高管,但是职位又多又不能一个个地去筛选,方便起见,设定高管为除了外部董事和独立董事的所有职位,包括上述所有职位。
- 对在任、新任、离任三个状态的界定:假如某某某的离任时间为2014年12月,那2014年他还算在不在任呢?毕竟2014年已经在任了几个月;类似新任时间为2015年11月,那2015年算不算在任呢?所以在和基友协商后,对三个状态的界定如下:新任年、离任年也算在任。
- 对新任时间、离任时间为空或N/A的界定:基友建议有空或N/A的删掉,但我认为计算的稳定性和个人的履历和任期时间等没有直接的关联,所以对于每年的报表中存在新任时间/离任时间为空就不管新任/离任了,就视为报表年该人在任即可。
- 异常数据:1.出现一个公司一年内多个时间段多次汇报的问题,并且汇报的内容有重复的,也有不同的,甚至有改动的数据。2.存在一些数据的离任时间在报表时间(汇报时间)之后,即假设报表时间为2014年12月31日,离任时间为2015年某一天,在这理解为预期离职,但存在某某某在2014年的报表中显示2015年离职,但2015年的报表中该职位没有离任时间。

| 属性名 | 证券代码 | 统计截止日期 | 人员ID | 姓名 | 具体职务 | 任职开始日期 | 任职结束日期 | 是否在职 | 任期 |
| 解释 | 用来表示公司的唯一标识 | 公司提交报表的时间 | 表示所有员工的唯一标识 | - | 担任的职务名 | 对应职务开始时间 | 对应职务结束时间 | 表示在提交报表时该人是否在任该职务 | 从任职开始到统计截至日期的任期, |
| 取值范围 | 6位数,不为空 | 日期格式,不为空 | 不定长数字,不为空 | 不为空,可能重复 | 一条信息只有一个职务,不为空,但存在多元表示问题 | 日期格式,可能为空或N/A | 期格式,可能为空或N/A | 0(当前不在职)或1(当前在职) | 单位为月。正整数或空(任期开始日期为空或N/A时) |
由于可能存在重名问题,所以采用人员ID来表示独立个体,是否在职和任期可由之前属性推出,可以选择不用。但由于存在一年内存在多次提交数据的问题,为了防止重复,所以采用以下结构来储存结果:
证券代码:年份:人员ID:[在任职务表:[职务1,职务2,,...],新任职务表:[职务1,职务2,,...],离任职务表:[职务1,职务2,,...]]
用来表示某公司在某年,某员工的在任、新任和离任表,用来表示详细的每年的在任、新任、离任情况。
思路:读取每条信息,获得所在公司的证券代码、统计截止日期、人员ID、具体职务,如果职务为独立董事或外部董事则直接跳过(continue),如果报表年(统计截止日期所在年)该公司该员工在任表内没有该职务,则加入在任职务表;获得任职开始日期,如果不为空或N/A的话,将字符串转换为日期格式,提取对应的年份,在对应的年份的该公司该员工的新任和在任表内添加该职务(如果已有的话则跳过),离任同理。这样,无需区分离任日期、新任日期和报表日期的关系。储存后,很容易得到每个公司每年的所有在任、离任、新任数,保存在列表M中,两个公式差异不大,这次计算第二个(SI)。每个公司在每年(2014-2019年间,公式中i取1)的SI中,用该年的在任人数表示Mt,该年的离任人数表示为![]() ,下一年的在任人数表示Mt+1,下一年的新增人数表示为
,下一年的在任人数表示Mt+1,下一年的新增人数表示为![]() 。
。
import xlrd
import datetime
import xlwt
READ=True
PREPROCESS=True
CAL=True
WRITE=True
if READ:
table=xlrd.open_workbook('高管团队任职情况.xlsx')
t=table.sheet_by_index(0)
N=t.nrows
#计算在t年在任在第t+1年离任的人数 没用到
#计算第t年的高管总人数
#计算第t年不在任 第t+1年新任的人数
#股票代码用string 存储
position_out=['外部董事','独立董事']
M=dict() #公司每年的在任/离任/新任人数 格式: 公司号(股票代号):年份:[在任人数,离任,新任]
SI=dict()
#同年离任/新任也算在任
#数据出现问题
if PREPROCESS:
Detail=dict()#详细表 公司号:年份:员工id:{在任:[],离任:[].新任:[]}
for l in range(3,N):#第3行开始为数据
stkcd=str(int(t.cell_value(l,0)))
Reptdt=str(t.cell_value(l,1))#统计截止日期
PersonID=str(int(t.cell_value(l,2)))
Position=t.cell_value(l,4)
if Position in position_out:
#不在其位,不谋其政
continue
StartDate=str(t.cell_value(l,5))
EndDate=str(t.cell_value(l,6))
Tenure_value=str(t.cell_value(l,8))#没用到
ReptYear=Reptdt[:4]#取字符串的前四位,表示年份
if stkcd not in Detail:#如果不存在则创建
Detail[stkcd]=dict()
if ReptYear not in Detail[stkcd]:
Detail[stkcd][ReptYear]=dict()
if PersonID not in Detail[stkcd][ReptYear]:
Detail[stkcd][ReptYear][PersonID]={0:[],-1:[],1:[]}#0:在任,1:新任,-1:离任
ReptDateTime=datetime.datetime.strptime(Reptdt,'%Y-%m-%d')
if Position not in Detail[stkcd][ReptYear][PersonID][0]:
Detail[stkcd][ReptYear][PersonID][0].append(Position)#不在表内则添加
if len(StartDate)>4:#如果长度大于4(不为空或N/A)
StartDateTime=datetime.datetime.strptime(StartDate,'%Y-%m-%d')
if str(StartDateTime.year) not in Detail[stkcd]:
Detail[stkcd][str(StartDateTime.year)]=dict()
if PersonID not in Detail[stkcd][str(StartDateTime.year)]:
Detail[stkcd][str(StartDateTime.year)][PersonID]={0:[],-1:[],1:[]}
if Position not in Detail[stkcd][str(StartDateTime.year)][PersonID][1]:#新任
Detail[stkcd][str(StartDateTime.year)][PersonID][1].append(Position)
if Position not in Detail[stkcd][str(StartDateTime.year)][PersonID][0]:#在任
Detail[stkcd][str(StartDateTime.year)][PersonID][0].append(Position)
if len(EndDate)>4:#离任同理
EndDateTime=datetime.datetime.strptime(EndDate,'%Y-%m-%d')
if str(EndDateTime.year) not in Detail[stkcd]:
Detail[stkcd][str(EndDateTime.year)]=dict()
if PersonID not in Detail[stkcd][str(EndDateTime.year)]:
Detail[stkcd][str(EndDateTime.year)][PersonID]={0:[],-1:[],1:[]}
if Position not in Detail[stkcd][str(EndDateTime.year)][PersonID][-1]:
Detail[stkcd][str(EndDateTime.year)][PersonID][-1].append(Position)
if Position not in Detail[stkcd][str(EndDateTime.year)][PersonID][0]:
Detail[stkcd][str(EndDateTime.year)][PersonID][0].append(Position)
if CAL:
for stkcd in Detail:
M[stkcd]=dict()
for year in Detail[stkcd]:
M[stkcd][year]=[0,0,0]#初始化
for PersonID in Detail[stkcd][year]:
M[stkcd][year][0]+=len(Detail[stkcd][year][PersonID][0])#统计
M[stkcd][year][1]+=len(Detail[stkcd][year][PersonID][1])
M[stkcd][year][2]+=len(Detail[stkcd][year][PersonID][-1])
for stkcd in M:
SI[stkcd]=dict()
for year in M[stkcd]:
if int(year)<=2013 or int(year)>=2019:#指定年份
continue
NextYear=str(int(year)+1)
Mj=M[stkcd][year][0]
if NextYear not in M[stkcd]:
SI[stkcd][year]=0
continue
Mjp1=M[stkcd][NextYear][0]
S1=M[stkcd][year][2] #在j年是 但j+1不是 计算离任
S2=M[stkcd][NextYear][1] #在j年不是但j+1是 计算新任
SI[stkcd][year]=(Mj-S1)/Mj*(Mjp1)/(Mj+Mjp1)+(Mjp1-S2)/Mjp1*Mj/(Mj+Mjp1)
if WRITE:
workspace=xlwt.Workbook(encoding='ascii')
excel=workspace.add_sheet('sheet1',cell_overwrite_ok=True)#添加第一张表
excel.write(0,0,'证券代码')
excel.write(0,1,'2014-2015')
excel.write(0,2,'2015-2016')
excel.write(0,3,'2016-2017')
excel.write(0,4,'2017-2018')
excel.write(0,5,'2018-2019')
c=1
for item in SI:
excel.write(c,0,item)
for year in range(2014,2019):
if str(year) in SI[item]:
excel.write(c,year-2013,SI[item][str(year)])
else:#如果没有该年的数据,则写入0
excel.write(c,year-2013,'0')
c=c+1
workspace.save('answer.xls') 然后我基友不知道从哪里搞来了浙大一个小伙的代码。用pandas直接对整个表进行操作的:(他似乎把离任的那一年不算同一年,并且他使用的是stmt算法, 我使用的是IS,所以两个结果有出入)
# -*- coding: utf-8 -*-
"""
Created on Fri May 15 17:03:55 2020
@author: hp
"""
# -*- coding: utf-8 -*-
import numpy as np
import pandas as pd
df=pd.read_excel("Executives.xlsx")
df.columns=['Stkcd', 'Reptdt', 'Name', 'Position_type', 'Position', 'StartDate', 'EndDate','Note']
#有的列名是乱的代码要修改一下
df.drop([0,1],axis=0,inplace=True)
df.head()
#预处理
df['Reptdt']=pd.to_datetime(df['Reptdt'])
df['re_year']=df['Reptdt'].map(lambda x:x.year)
#将一行内的不同入职、离职日期合并
def min_date(x):
if x is None:
return None
else:
c=np.array(x.split(',')).astype(str)
return np.min(pd.to_datetime(c))
def max_date(x):
if x is None:
return None
else:
c=np.array(x.split(',')).astype(str)
return np.max(pd.to_datetime(c))
df['StartDate']=df['StartDate'].astype(str).map(min_date)
df['EndDate']=df['EndDate'].astype(str).map(max_date)
df['Reptdt2']=df['Reptdt']
import datetime
#由于统计时间的不同,同一个人会出现多次,把这多条记录合并
data=df.groupby(['Stkcd','Name']).agg({'Reptdt2':'max','Reptdt':'min',
'StartDate':'min','EndDate':'max'}).reset_index()
data['EndDate']=data['EndDate'].fillna(pd.to_datetime('2020-01-01'))
data['StartDate']=data['StartDate'].fillna(data['StartDate'].min())
#这里再进行缺失日期的填补,注意这里可能引入误差
data['st_year']=data['StartDate'].map(lambda x:x.year)
data['end_year']=data['EndDate'].map(lambda x:x.year)
data['re_min']=data['Reptdt'].map(lambda x:x.year)
data['re_max']=data['Reptdt2'].map(lambda x:x.year)
#计算部分
def stmt(df):
#先处理年份,从统计年份的最小年算到最大年
y1=df['re_min'].min()
y2=df['re_max'].max()
if y1==y2:
return None
stmt_list=[]
for i in range(y1,y2):#对每一年计算stmt
#入职时间小于等于当年,离职时间大于当年的记为在位(或入职离职均为当年的)
da=((df['st_year']<=i)&(df['end_year']>i))|((df['st_year']==i)&(df['end_year']==i))
m1=np.sum(da)
da=((df['st_year']<=i+1)&(df['end_year']>i+1))|((df['st_year']==i+1)&(df['end_year']==i+1))
m2=np.sum(da)
da=(df['st_year']<=i)&(df['end_year']==i+1)
s1=np.sum(da)#i年在位但下一年离任
da=(df['st_year']==i+1)
s2=np.sum(da)#i+1年新入职
if (m1==0)|(m2==0):
stmt_list.append(0)
else:
stmt12=(m1-s1)/m1*m2/(m1+m2)+(m2-s2)/m2*m1/(m1+m2)
stmt_list.append(stmt12)
return pd.DataFrame({'year':range(y1,y2),'stmt':stmt_list})
df_result=data.groupby(['Stkcd']).apply(stmt).reset_index()
df_result.drop(['level_1'],axis=1,inplace=True)
df_result['Stkcd']=df_result['Stkcd'].astype(str)
df_result.to_excel("stmt_result.xlsx")后来因为第一个版本的数据存在一年内多次提交信息,并且2019年数据比较少,很多的值为0,而且职位信息混乱,后来又给了我新版的数据,该版本的数据中公司只在每年年底(12月31日)提交数据,并且同一个人的多个职位的名称、开始时间、结束时间在一条信息(一行)中展出。如下图所示
(图上传挂了,可能服务器出了点小小的问题)
与第一次数据相比,该数据用姓名取代了原有的人员编号,取消了任期和是否在任。处理方法和第一次大同小异,就是对职位进行字符串分割后依次获得对应的开始时间和结束时间并进行新任、在任、离任等数据的添加即可。
import xlrd
import datetime
import xlwt
READ=True
PREPROCESS=True
CAL=True
WRITE=True
if READ:
table=xlrd.open_workbook('高管团队稳定性指标11(1).xlsx')
t=table.sheet_by_index(0)
N=t.nrows
#计算在t年在任在第t+1年离任的人数 没用到
#计算第t年的高管总人数
#计算第t年不在任 第t+1年新任的人数
#股票代码用string 存储
position_out=['外部董事','独立董事']
M=dict() #公司每年的在任/离任/新任人数 格式: 公司号(股票代号):年份:[在任人数,离任,新任]
SI=dict()
#同年离任/新任也算在任
#数据出现问题
if PREPROCESS:
Detail=dict()#详细表 公司号:年份:员工id:{在任:[],离任:[].新任:[]}
for l in range(3,N):
stkcd=str(int(t.cell_value(l,0)))
Reptdt=str(t.cell_value(l,1))#统计截止日期
PersonID=(t.cell_value(l,2))
Positions=t.cell_value(l,4)
StartDates=str(t.cell_value(l,5))
EndDates=str(t.cell_value(l,6))
PositionList=Positions.split(',')#由于分割符单一,可以直接使用str.split代替re.split
StartDateList=StartDates.split(',')
EndDateList=EndDates.split(',')
ReptDateTime=datetime.datetime.strptime(Reptdt,'%Y-%m-%d')
Year=str(ReptDateTime.year)
if stkcd not in Detail:
Detail[stkcd]=dict()
if Year not in Detail[stkcd]:
Detail[stkcd][Year]=dict()
if PersonID not in Detail[stkcd][Year]:
Detail[stkcd][Year][PersonID]={0:[],-1:[],1:[]}
for Position in PositionList:
if Position in position_out:
#不在其位,不谋其政
continue
Detail[stkcd][Year][PersonID][0].append(Position)
if len(StartDates)>=6:
if PositionList.index(Position)<len(StartDateList):
StartDate=StartDateList[PositionList.index(Position)]
else:
continue
# StartDate=StartDateList[0]
if len(StartDate)>4:
StartDateTime=datetime.datetime.strptime(StartDate,'%Y-%m-%d')
StartYear=str(StartDateTime.year)
if StartYear not in Detail[stkcd]:
Detail[stkcd][StartYear]=dict()
if PersonID not in Detail[stkcd][StartYear]:
Detail[stkcd][StartYear][PersonID]={0:[],-1:[],1:[]}
if Position not in Detail[stkcd][StartYear][PersonID][1]:
Detail[stkcd][StartYear][PersonID][1].append(Position)
if Position not in Detail[stkcd][StartYear][PersonID][0]:
Detail[stkcd][StartYear][PersonID][0].append(Position)
if len(EndDates)>=6:
if PositionList.index(Position)<len(EndDateList):
EndDate=EndDateList[PositionList.index(Position)]
else:
continue
# EndDate=EndDateList[0]
if len(EndDate)>4:
EndDateTime=datetime.datetime.strptime(EndDate,'%Y-%m-%d')
EndYear=str(EndDateTime.year)
if EndYear not in Detail[stkcd]:
Detail[stkcd][EndYear]=dict()
if PersonID not in Detail[stkcd][EndYear]:
Detail[stkcd][EndYear][PersonID]={0:[],-1:[],1:[]}
if Position not in Detail[stkcd][EndYear][PersonID][1]:
Detail[stkcd][EndYear][PersonID][1].append(Position)
if Position not in Detail[stkcd][EndYear][PersonID][0]:
Detail[stkcd][EndYear][PersonID][0].append(Position)
if CAL:
for stkcd in Detail:
M[stkcd]=dict()
for year in Detail[stkcd]:
M[stkcd][year]=[0,0,0]
for PersonID in Detail[stkcd][year]:
M[stkcd][year][0]+=len(Detail[stkcd][year][PersonID][0])
M[stkcd][year][1]+=len(Detail[stkcd][year][PersonID][1])
M[stkcd][year][2]+=len(Detail[stkcd][year][PersonID][-1])
for stkcd in M:
SI[stkcd]=dict()
for year in M[stkcd]:
if int(year)<=2013 or int(year)>=2019:
continue
NextYear=str(int(year)+1)
Mj=M[stkcd][year][0]
if NextYear not in M[stkcd]:
SI[stkcd][year]=0
continue
Mjp1=M[stkcd][NextYear][0]
S1=M[stkcd][year][2] #在j年是 但j+1不是 计算离任
S2=M[stkcd][NextYear][1] #在j年不是但j+1是 计算新任
SI[stkcd][year]=(Mj-S1)/Mj*(Mjp1)/(Mj+Mjp1)+(Mjp1-S2)/Mjp1*Mj/(Mj+Mjp1)
if WRITE:
workspace=xlwt.Workbook(encoding='ascii')
excel=workspace.add_sheet('sheet1',cell_overwrite_ok=True)#添加第一张表
excel.write(0,0,'证券代码')
excel.write(0,1,'2014-2015')
excel.write(0,2,'2015-2016')
excel.write(0,3,'2016-2017')
excel.write(0,4,'2017-2018')
excel.write(0,5,'2018-2019')
c=1
for item in SI:
excel.write(c,0,item)
for year in range(2014,2019):
if str(year) in SI[item]:
excel.write(c,year-2013,SI[item][str(year)])
else:
excel.write(c,year-2013,'-1')
c=c+1
workspace.save('answer_new_data_3.xls') 另一个人针对该数据的代码(我没跑)
# -*- coding: utf-8 -*-
"""
Created on Fri May 15 17:03:55 2020
@author: hp
"""
# -*- coding: utf-8 -*-
import numpy as np
import pandas as pd
df=pd.read_excel("Executives.xlsx")
df.columns=['Stkcd', 'Reptdt', 'Name', 'Position_type', 'Position', 'StartDate', 'EndDate','Note']
#有的列名是乱的代码要修改一下
df.drop([0,1],axis=0,inplace=True)
df.head()
#预处理
df['Reptdt']=pd.to_datetime(df['Reptdt'])
df['re_year']=df['Reptdt'].map(lambda x:x.year)
#将一行内的不同入职、离职日期合并
def min_date(x):
if x is None:
return None
else:
c=np.array(x.split(',')).astype(str)
return np.min(pd.to_datetime(c))
def max_date(x):
if x is None:
return None
else:
c=np.array(x.split(',')).astype(str)
return np.max(pd.to_datetime(c))
df['StartDate']=df['StartDate'].astype(str).map(min_date)
df['EndDate']=df['EndDate'].astype(str).map(max_date)
df['Reptdt2']=df['Reptdt']
import datetime
#由于统计时间的不同,同一个人会出现多次,把这多条记录合并
data=df.groupby(['Stkcd','Name']).agg({'Reptdt2':'max','Reptdt':'min',
'StartDate':'min','EndDate':'max'}).reset_index()
data['EndDate']=data['EndDate'].fillna(pd.to_datetime('2020-01-01'))
data['StartDate']=data['StartDate'].fillna(data['StartDate'].min())
#这里再进行缺失日期的填补,注意这里可能引入误差
data['st_year']=data['StartDate'].map(lambda x:x.year)
data['end_year']=data['EndDate'].map(lambda x:x.year)
data['re_min']=data['Reptdt'].map(lambda x:x.year)
data['re_max']=data['Reptdt2'].map(lambda x:x.year)
#计算部分
def stmt(df):
#先处理年份,从统计年份的最小年算到最大年
y1=df['re_min'].min()
y2=df['re_max'].max()
if y1==y2:
return None
stmt_list=[]
for i in range(y1,y2):#对每一年计算stmt
#入职时间小于等于当年,离职时间大于当年的记为在位(或入职离职均为当年的)
da=((df['st_year']<=i)&(df['end_year']>i))|((df['st_year']==i)&(df['end_year']==i))
m1=np.sum(da)
da=((df['st_year']<=i+1)&(df['end_year']>i+1))|((df['st_year']==i+1)&(df['end_year']==i+1))
m2=np.sum(da)
da=(df['st_year']<=i)&(df['end_year']==i+1)
s1=np.sum(da)#i年在位但下一年离任
da=(df['st_year']==i+1)
s2=np.sum(da)#i+1年新入职
if (m1==0)|(m2==0):
stmt_list.append(0)
else:
stmt12=(m1-s1)/m1*m2/(m1+m2)+(m2-s2)/m2*m1/(m1+m2)
stmt_list.append(stmt12)
return pd.DataFrame({'year':range(y1,y2),'stmt':stmt_list})
df_result=data.groupby(['Stkcd']).apply(stmt).reset_index()
df_result.drop(['level_1'],axis=1,inplace=True)
df_result['Stkcd']=df_result['Stkcd'].astype(str)
df_result.to_excel("stmt_result.xlsx")总结:感觉使用pandas包对整个表进行操作,能快不少,虽然存在着习惯用xlwt/xlrd逐个读取、操作,但也得适当地学习,简化不少冗余等,可以适当地学习使用/