概述
SkyWalking是一个开源的可观测分析平台(Observability Analysis Platform), 用于从服务和云原生基础设施收集, 分析, 聚合及可视化数据。SkyWalking 提供了一种简便的方式来清晰地观测分布式系统, 甚至横跨多个云平台。SkyWalking 更是一个现代化的应用程序性能监控(Application Performance Monitoring)系统, 尤其专为云原生、基于容器的分布式系统设计。
官方网站:http://skywalking.apache.org/zh/ Github主页:https://github.com/apache/skywalking
1.简介
公众号:Java高级架构师,输入“idea”,获取永久注册马!输入“阿里云”,获取阿里云网盘公测地址!

SkyWalking 为 服务(service), 服务实例(service instance), 以及 端点(endpoint) 提供了可观测能力。服务(Service), 实例(Instance) 以及 端点(Endpoint) 等概念在如今随处可见, 所以让我们先了解一下他们在 SkyWalking 中都表示什么意思
服务(Service) 表示对请求提供相同行为的一组工作负载. 在使用打点代理或 SDK 的时候,你可以定义服务的名字. SkyWalking 还可以使用在 Istio 等平台中定义的名称。
服务实例(Service Instance) 上述的一组工作负载中的每一个工作负载称为一个实例. 就像 Kubernetes 中的 pods 一样,服务实例未必就是操作系统上的一个进程. 但当你在使用打点代理的时候, 一个服务实例实际就是操作系统上的一个真实进程.
端点(Endpoint) 对于特定服务所接收的请求路径, 如 HTTP 的 URI 路径和 gRPC 服务的类名 + 方法签名。

-
架构
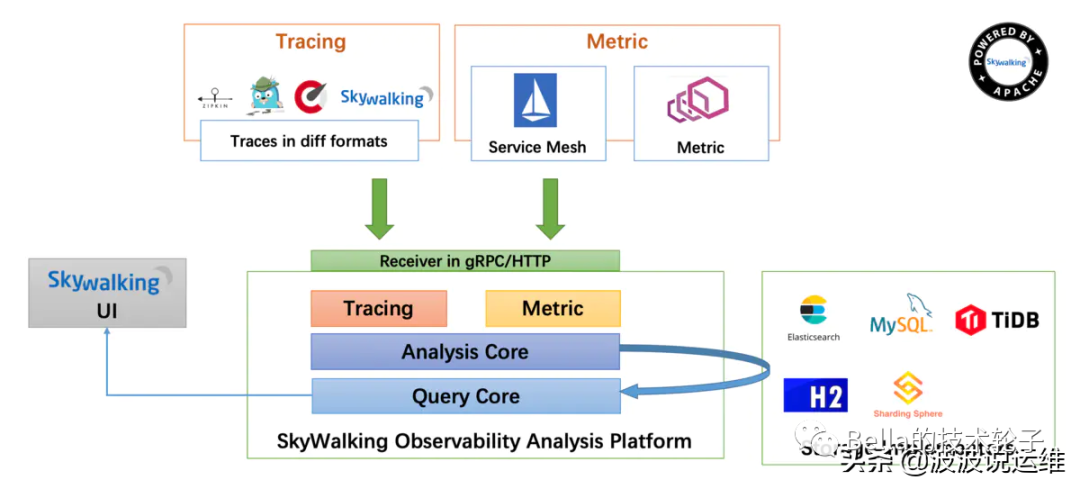
SkyWalking 的核心是数据分析和度量结果的存储平台,通过 HTTP 或 gRPC 方式向 SkyWalking Collecter 提交分析和度量数据,SkyWalking Collecter 对数据进行分析和聚合,存储到 Elasticsearch、H2、MySQL、TiDB 等其一即可,最后我们可以通过 SkyWalking UI 的可视化界面对最终的结果进行查看。Skywalking 支持从多个来源和多种格式收集数据:多种语言的 Skywalking Agent 、Zipkin v1/v2 、Istio 勘测、Envoy 度量等数据格式。
SkyWalking 逻辑上分为四部分: 探针, 平台后端, 存储和用户界面。
-
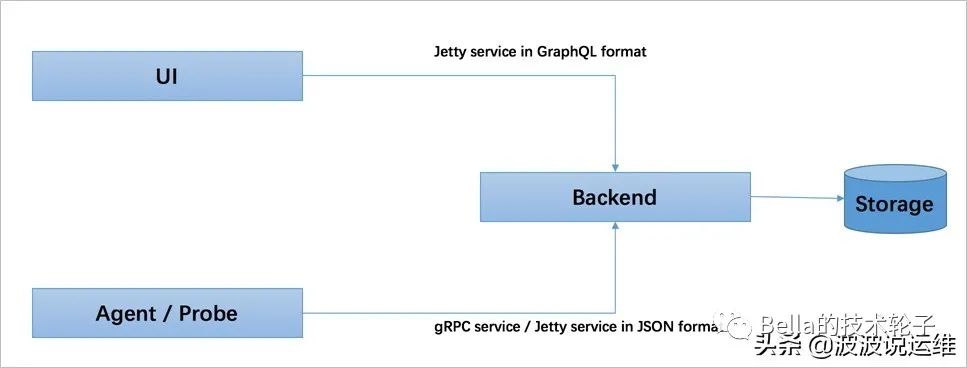
探针。基于不同的来源可能是不一样的, 但作用都是收集数据, 将数据格式化为 SkyWalking 适用的格式.
-
平台后端。支持数据聚合, 数据分析以及驱动数据流从探针到用户界面的流程。分析包括 Skywalking 原生追踪和性能指标以及第三方来源,包括 Istio 及 Envoy telemetry , Zipkin 追踪格式化等。你甚至可以使用 Observability Analysis Language 对原生度量指标 和 用于扩展度量的计量系统 自定义聚合分析。
-
存储。通过开放的插件话的接口存放 SkyWalking 数据. 你可以选择一个既有的存储系统, 如 ElasticSearch, H2 或 MySQL 集群(Sharding-Sphere 管理),也可以选择自己实现一个存储系统. 当然, 我们非常欢迎你贡献新的存储系统实现。
-
UI。一个基于接口高度定制化的Web系统,用户可以可视化查看和管理 SkyWalking 数据。
3. 特点
SkyWalking 有如下核心特点:
-
保持可观测性。不管目标系统如何部署, SkyWalking 总要提供一种方案或集成方式来保持对目标系统的观测, 基于此, SkyWalking 提供了数种运行时探针。
-
拓扑结构。性能指标和追踪一体化. 理解分布式系统的第一步是通过观察其拓扑结构图. 拓扑图可以将复杂的系统在一张简单的图里面进行可视化展现. 基于拓扑图,运维支撑系统相关人员需要更多关于服务/实例/端点/调用的性能指标. 链路追踪(trace)作为详细的日志, 对于此种性能指标来说很有意义, 如你想知道什么时候端点延时变得很长, 想了解最慢的链路并找出原因. 因此你可以看到, 这些需求都是从大局到细节的, 都缺一不可. SkyWalking 集成并提供了一系列特性来使得这些需求成为可能, 并且使之易于理解.
-
轻量级。有两个方面需要保持轻量级. (1) 探针, 我们通常依赖于网络传输框架, 如 gRPC. 在这种情况下, 探针就应该尽可能小, 防止依赖库冲突以及虚拟机的负载压力(例如 JVM 永久代内存占用压力). (2) 作为一个观测平台, 在你的整个项目环境中只是次要系统, 因此我们使用自己的轻量级框架来构建后端核心服务. 所以你不需要部署并维护大数据相关的平台, SkyWalking 在技术栈方面应该足够简单。
-
可插拔。SkyWalking 核心团队提供了许多默认实现, 但这肯定是不够的, 也不可能适用于每一种场景, 因此我们提供了大量的特性来支持可插拔功能。
-
可移植。SkyWalking 可以运行在多种环境下, 包括: (1) 使用传统的注册中心, 如 Eureka (2) 使用包含服务发现的RPC框架,如Spring Cloud, Apache Dubbo (3) 在现代基础设施中使用服务网 (4) 使用云服务 (5) 跨云部署。在所有这些情况下,SkyWalking 应该运行良好
-
可互操作。可观测性是一个庞大的领域, 即使有强大的社区, SkyWalking 不可能支持所有方方面面, 因此 SkyWalking 支持与其他运维支撑系统进行互操作, 主要是探针, 如 Zipkin, Jaeger, OpenTracing 和 OpenCensus. SkyWalking 接收并理解他们的数据格式, 这对于终端用户来说是非常有用的, 因为不需要他们更换已有的库。
4.安装部署skywalking
1.部署jdk1.8

2.部署ES

-
部署skywalking
SkyWalking 的启动包括两部分,一个是 SkyWalking Collector(oapService) ,一个是 SkyWalking UI(webappService),SkyWalking 解压后的 bin 目录
-- 下载安装
wget https://mirror.bit.edu.cn/apache/skywalking/8.0.1/apache-skywalking-apm-es7-8.0.1.tar.gz
tar -xzvf apache-skywalking-apm-es7-8.0.1.tar.gz -C /usr/local/
mv /usr/local/apache-skywalking-apm-bin-es7 /usr/local/skywalking
-- 修改配置,使用 elasticsearch7 作为存储
--选择连接ES7数据库,配置命名空间、IP地址、生命周期策略等参数。
--默认情况下,记录类数据保存3天,指标类数据保存7天,每间隔5分钟做一次滚动删除。
vim /usr/local/skywalking/config/application.yml
=========================================================================
storage:
selector: ${SW_STORAGE:elasticsearch7}
elasticsearch7:
nameSpace: ${SW_NAMESPACE:"skyworking"}
clusterNodes: ${SW_STORAGE_ES_CLUSTER_NODES:localhost:9200}
core:
default:
enableDataKeeperExecutor: ${SW_CORE_ENABLE_DATA_KEEPER_EXECUTOR:true} # Turn it off then automatically metrics data delete will be close.
dataKeeperExecutePeriod: ${SW_CORE_DATA_KEEPER_EXECUTE_PERIOD:5} # How often the data keeper executor runs periodically, unit is minute
recordDataTTL: ${SW_CORE_RECORD_DATA_TTL:3} # Unit is day
metricsDataTTL: ${SW_CORE_RECORD_DATA_TTL:7} # Unit is day
4.日常运维
-- 启动
/usr/local/skywalking/bin/startup.sh

5.应用接入skywalking探针
在 SkyWalking 中, 探针表示集成到目标系统中的代理或 SDK 库, 它负责收集遥测数据, 包括链路追踪和性能指标。根据目标系统的技术栈, 探针可能有差异巨大的方式来达到以上功能. 但从根本上来说都是一样的, 即收集并格式化数据, 并发送到后端。
1.下载解压
登录目标系统应用服务器,将官方下载包中的agent文件夹复制到提定目录
unzip apm-agent.zip -d /usr/local
2.修改配置
进入布署应用的tomcat,打开tomcat/bin/catalina.sh文件,添加动态代理配置,设定服务名、实例名、后端IP地址、日志保留期、采集请求参数与sql执行参数。一般添加在配置文件最开始处。
CATALINA_OPTS="$CATALINA_OPTS -javaagent:/usr/local/apm-agent/skywalking-agent.jar=agent.service_name=fsl_sit.portal,agent.instance_name=portal119,collector.backend_service=172.1xxxx:11800,logging.max_history_files=3,plugin.mysql.trace_sql_parameters=true,plugin.springmvc.collect_http_params=true"; export CATALINA_OPTS
3.重启tomcat应用
ps -ef|grep java|grep -v grep | awk '{print $2}' | xargs kill -9
./startup.sh
6.部分界面展示
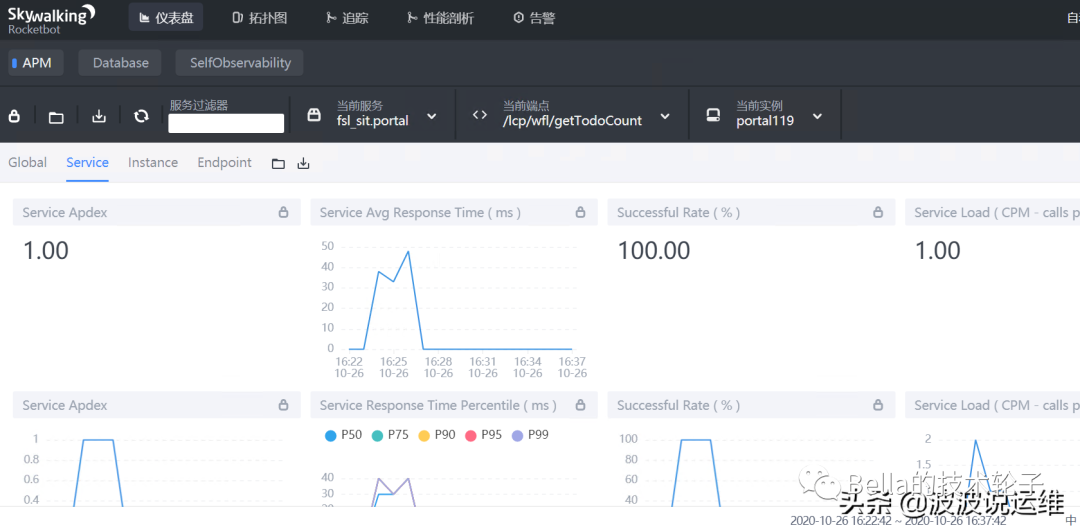

skywalking不仅可以帮助我们做链路跟踪,也可以帮助我们获取数据库中的慢sql并进一步优化,感兴趣的朋友可以测试一下。