前提
调优过程中使用
explain命令查看执行过程,包括执行时间、扫描方式、是否用到索引等,EXPLAIN 使用浅析
开启查询sql执行时间:
\timing on
关闭查询sql执行时间:
\timing off
一. 问题描述
一个查询接口被频繁调用,且查询过程较慢
二. 优化思路
- 首先考虑优化SQL语句
- 其次考虑优化业务代码
- 最后考虑是否需要添加缓存机制
三. 优化过程
3.1 优化SQL
原始SQL,分组查询每组中seq_id最大的数据,使用in + group by实现
select name, version from yc_test where seq_id in(
select max(seq_id) from yc_test group by name
);
3.1.1 SQL优化思路
- 考虑添加索引,加快查询速度
in会转为or并转为union all,效率较低。考虑使用exists或者join替代。为什么?
3.1.2 优化后的SQL
select a.name, a.version from yc_test a inner join (
select max(seq_id) as seq_id from yc_test group by name
) b on a.seq_id=b.seq_id;
3.1.3 SQL优化前后对比
explain:
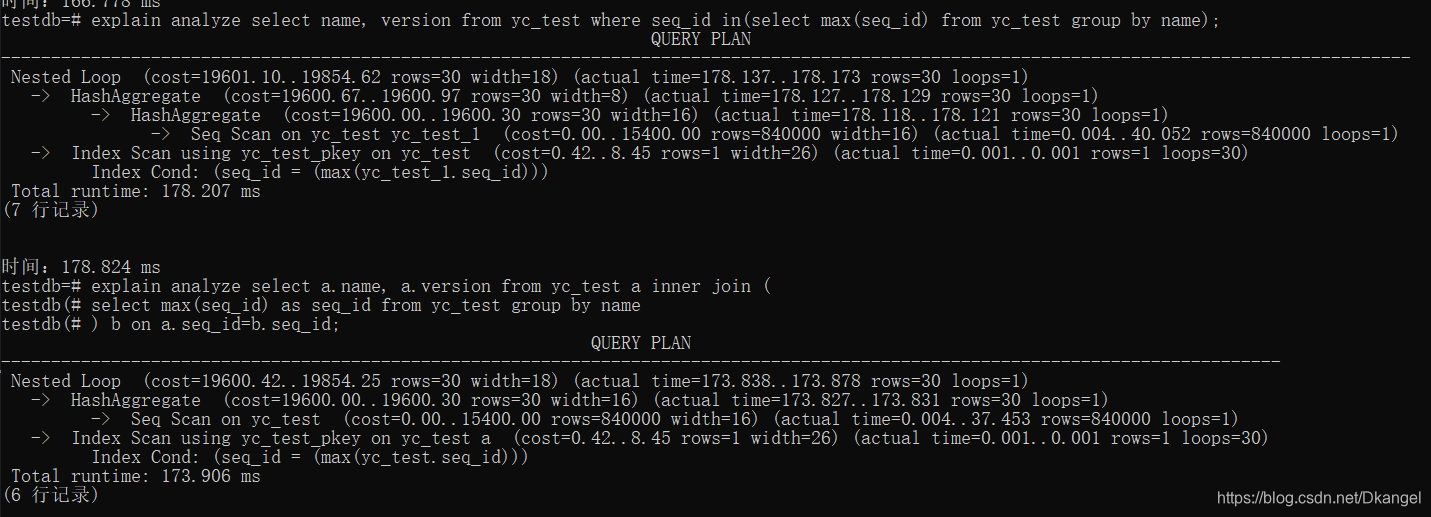
| sql | 优点 | 缺点 |
|---|---|---|
| in实现 | sql简单 | in会转换为or再转为union all,效率较低,如图多一层循环 |
| inner join实现 | 减少一层循环,效率提升 | 相比之下sql较复杂 |
3.2 优化业务代码
结合功能的业务场景(可以理解为历史记录),走读代码,发现并不是所有数据都需要持久化保存
优化方案:
定时器定时清理过期数据,减少数据冗余业务逻辑做控制,save数据的时候判断是否有多余的数据,有则删除多余的
3.3 添加缓存机制
热点数据,可以考虑缓存到内存中(变量缓存),或者存储数据库中(Redis/Memcached)
由于已经对数据量做了控制并结合后期规划,所以并未添加缓存机制