以下内容转载自 https://www.toutiao.com/i6940139685289132582/
腾讯技术工程2021-03-16 18:02:00
作者:kellyliang
聊天室概述
随着直播和类直播场景在微信内的增长,业务对临时消息通道的需求日益增长,聊天室组件应运而生。聊天室组件是一个基于房间的临时消息信道,主要提供消息收发、在线状态统计等功能。
1500w在线的挑战
视频号直播上线后,在产品上提出了直播后台需要有单房间支撑1500w在线的技术能力。接到这个项目的时候,自然而然就让人联想到了一个非常有趣的命题:能不能做到把13亿人拉个群?


本文将深入浅出地介绍聊天室组件在演进过程的思考,对这个命题做进一步对探索,尝试提出更接近命题答案的方案。
聊天室1.0架构
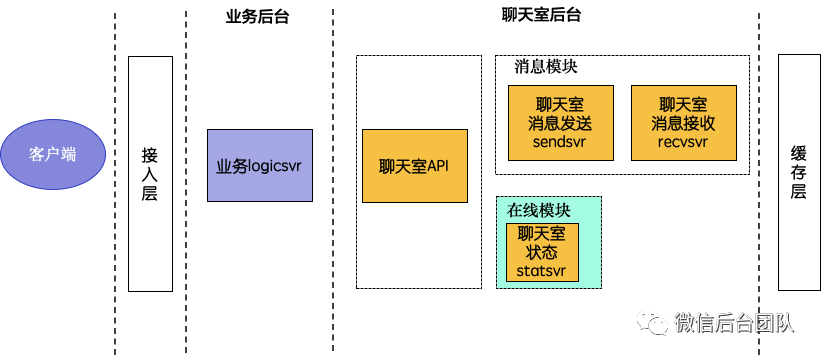
聊天室1.0诞生于2017年,主要服务于微信电竞直播间,核心是实现高性能、高实时、高可扩展的消息收发架构。
消息框架选型:读扩散
| 微信群 |
聊天室 |
|
| 参与人数 |
<=500 |
数万 |
| 关系链 |
有 |
无 |
| 成员流动 |
低 |
高 |
| 离线消息 |
关注 |
不关注 |
微信群消息使用写扩散的机制,而聊天室跟微信群有着巨大的差异。且同一时间只能关注一个聊天室,决定了聊天室应该使用读扩散的机制。
longpolling机制
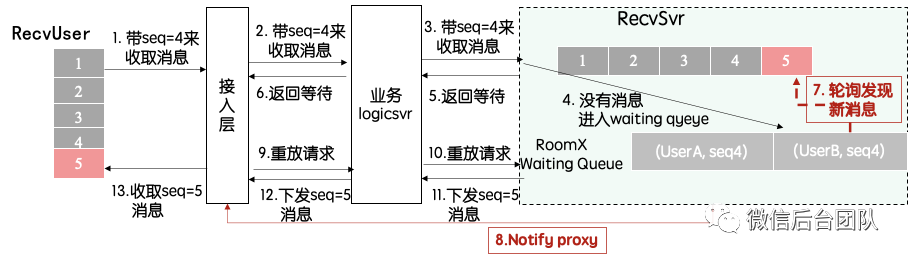
为了让用户需要实时同步到新消息,我们采用的是longpolling模式。很多人会疑惑为什么不用websocket,原因有3个:
1. websocket主要考虑推模式,而推模式则有可能丢,做到不丢还是有需要拉模式来兜底;
2. 推模式下,需要精准维护每个时刻的在线列表,难度很大。
3. longpolling本质是一个短连,客户端实现更简单。
无状态cache的设计
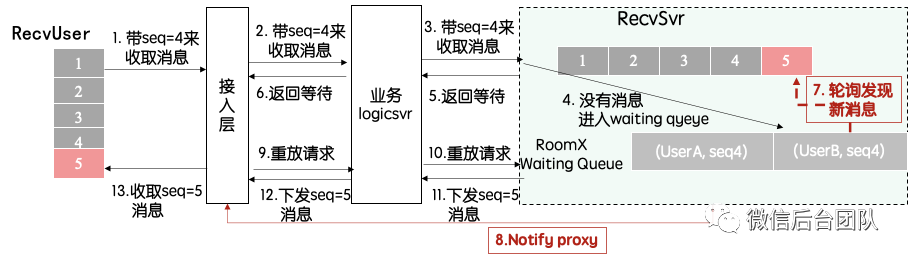
很明显,单纯的读扩散,会造成巨大读盘的压力。按照国际惯例,这里理所应当地增加了一个cache,也就是上面架构图中的recvsvr。

普通的cache都是有状态的、可穿透的,对经常会出现突发流量的聊天室不是特别友好。而通过异步线程任务,恰好可以解决这两个点。
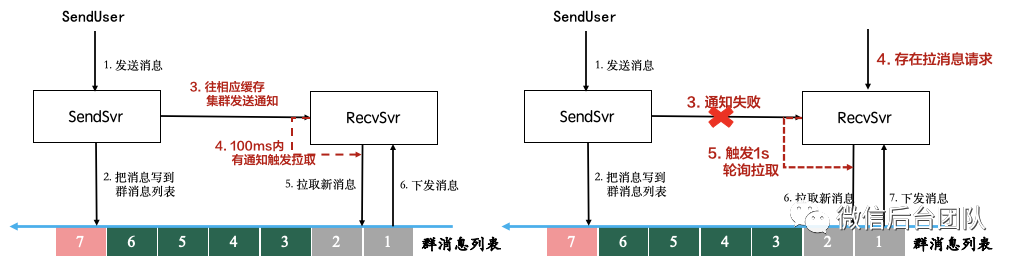
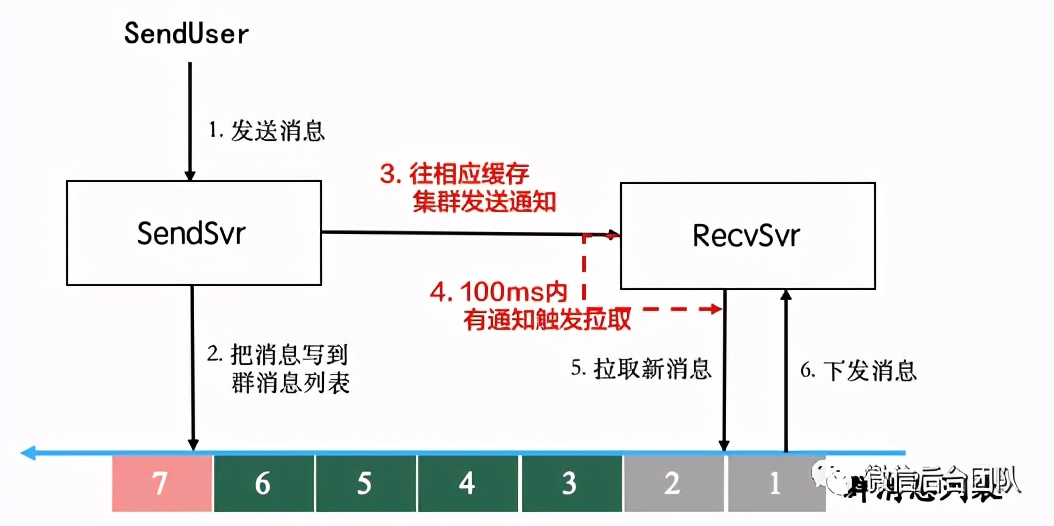
① 实时通知:发送消息时,在写入列表后,向recvsvr集群发送通知;
② 异步拉取:recvsvr机器收到通知后,触发异步线程拉取;
③ 兜底轮询:当recvsvr机器上接收到某个聊天室的请求时,触发该聊天室的轮询,保证1s内至少访问一次消息列表,避免通知失效导致无法更cache,同时做到机器启动时数据的自动恢复。
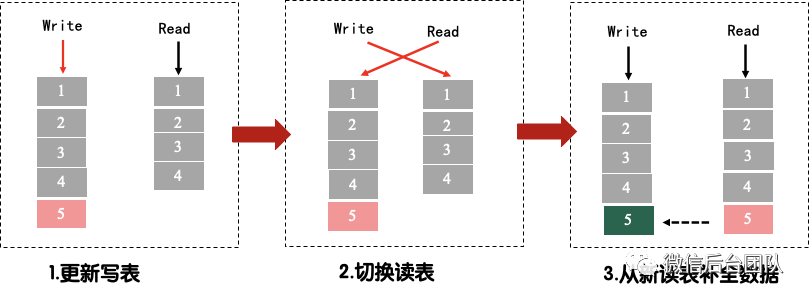
④ 无锁读取:通过读写表分离和原子切换,做到消息的无锁读取
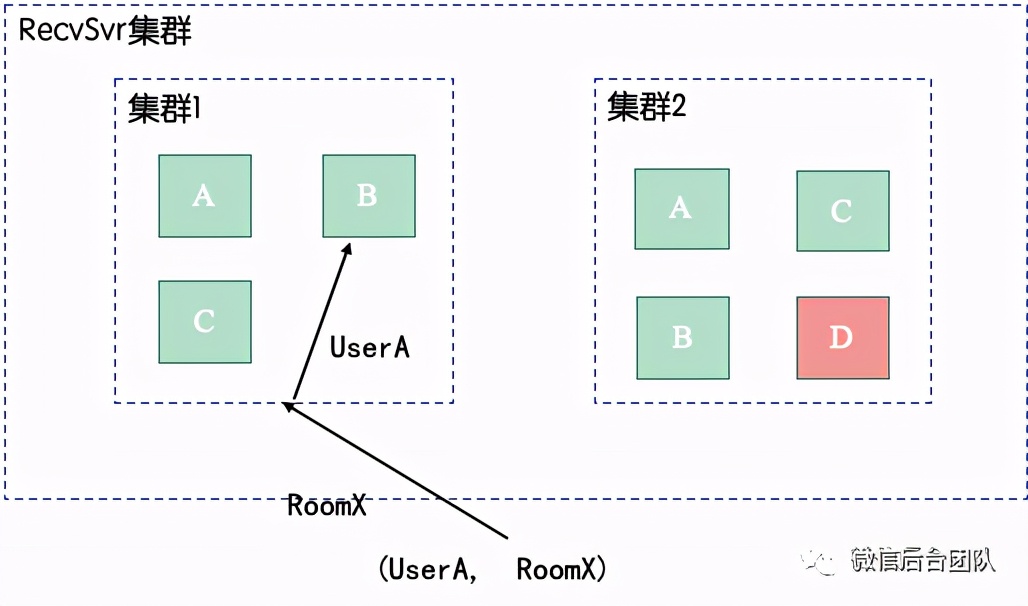
⑤ sect化部署:群数量增多时,扩sect可以把群分摊到新的sect上。
无状态消息cache的设计,不仅极大地提高了系统的性能,而且帮助聊天室建立了一个高扩展性消息收发架构。
痛点
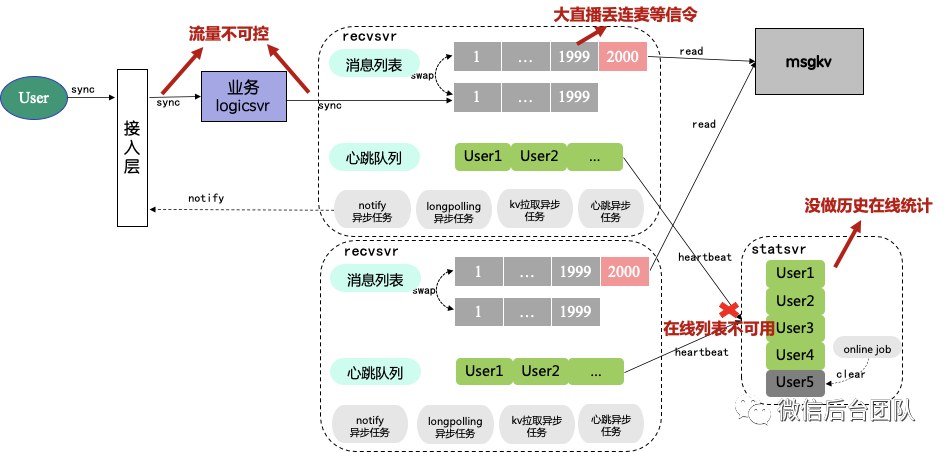
尽管做到了高性能的消息收发,1.0版本却并不能实现单房间1500w同时在线的目标。通过对整个架构和逻辑进一步的分析,我们发现4个阻碍我们前进的痛点:
(1)大直播间里,消息信道不保证所有消息都下发,连麦成功信令丢失会使得连麦功能不可用,大礼物打赏动画信令丢失会带来客诉;
(2)一个房间的在线列表,是由recvsvr把最近有收取该房间的消息的user聚合到同一台statsvr得到的,有单点瓶颈,单机失败会导致部分房间在线数跳变、在线列表和打赏排行榜不可用等;
(3)没有提供历史在线人数统计功能;
(4)裸的longpolling机制在消息一直有更新的情况下,无法控制请求量。
聊天室2.0架构
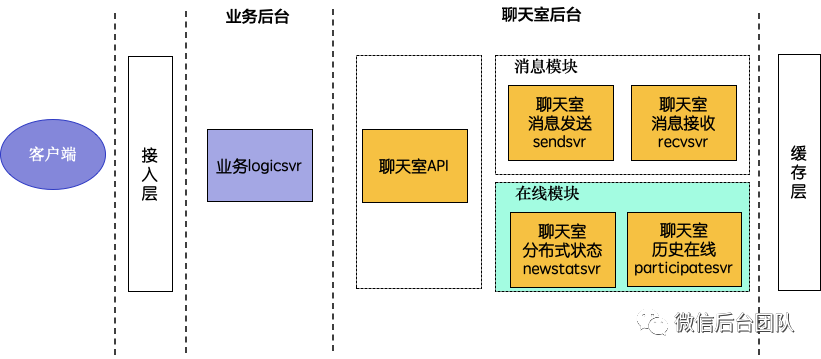
从上面分析的痛点,我们得出了聊天室2.0需要解决的问题:
(1)解决丢重要信令问题,保证热点访问下功能的可靠性。
(2)解决在线统计的单点瓶颈,保证热点访问下在线统计模块的可扩展性。
(3)实现一个高效准确的历史在线统计,保证大数据量下统计的高性能和准确性。
(4)灵活把控流量,进一步提升隔离和容灾能力,保证热点访问下系统的可用性。
优先级消息列表
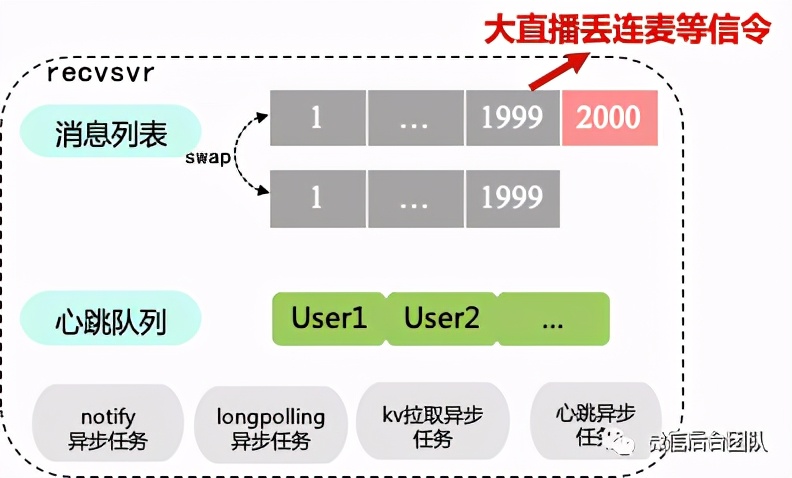
丢信令的本质原因:recvsvr只保留最近2000条消息,大直播间里,有些消息客户端还没来的及收就被cache淘汰了。
在聊天室1.0版本,我们已经证实了写扩散不可行,因此这里也不可能通过写扩散解决。
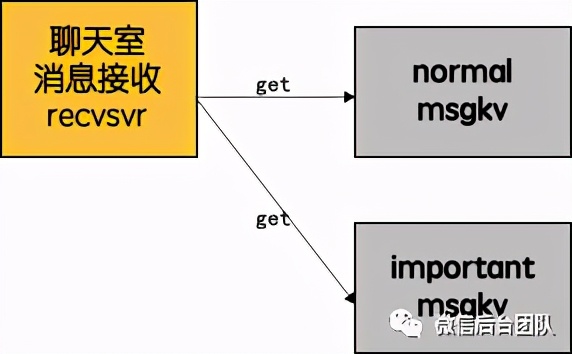
另外一个比较直观的方案:是将重要的系统信令写到另外一个列表里面,recvsvr同时读取两个消息表。带来的消耗是recvsvr对kv层增加将近一倍的访问量。于是,我们思考有没有更优的方案。
回到1.0版本的一个方案细节,我们可以看到大部分情况下,当新消息到来的时候,recvsvr它都是能及时感知到的,因此recvsvr一次拉取到的消息条数并不会很多,因此这一步骤上不会丢消息。所以我们是可以把消息表这个操作收归到recvsvr里面的:
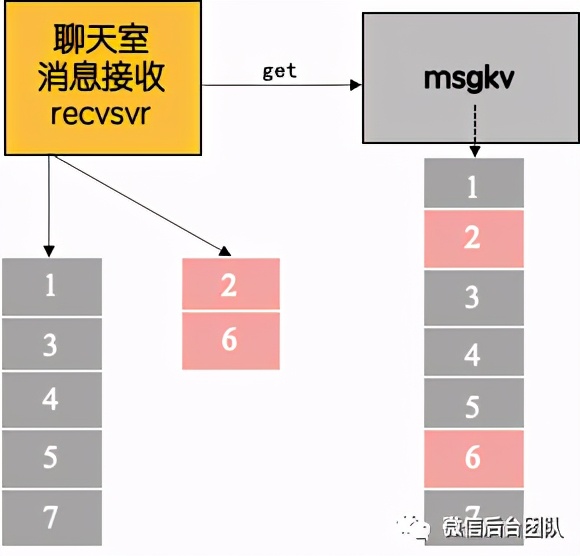
① 打优先级标记 :依然只写一张消息表,给重要的信令打上优先级标记;(节省RPC消耗)
② cache内分表:recvsvr拉到消息后分开普通消息列表和重要消息列表;(最小化改动)
③ 优先收取:收取时分normal seq和important seq,先收重要消息表,再收取普通消息表。(优先下发)
通过一个简单的优化,我们以最小的改造代价,提供到了一条可靠的重要消息信道,做到了连麦和大礼物动画的零丢失。
分布式在线统计
(1)写共享内存,主从互备
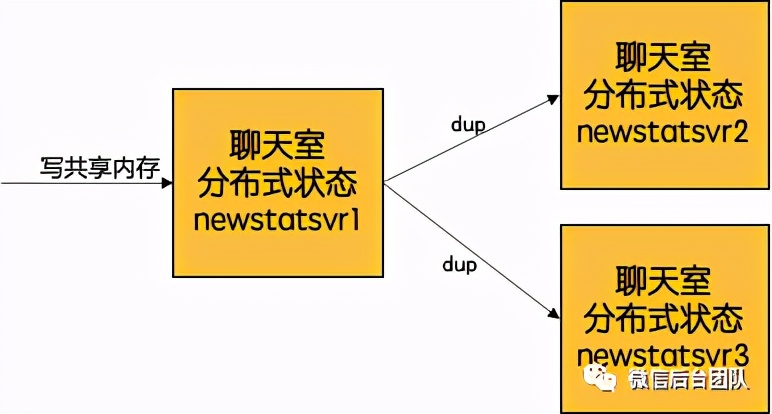
参考微信设备在线模块,我们可以有这个一个方案:
① 分sect,一个直播间选一个sect;
② 按roomid选一台机作为master, 读写该机器的共享内存;
③ master把这个roomid的数据同步到sect内其它机器,master挂了的情况可以选其它机器进行读写。
优点:解决了换机跳变问题。
缺点:主备同步方案复杂;读写master,大直播间下依然有单机热点问题。
结论:用分布式存储作为数据的中心节点。
(2)写tablekv
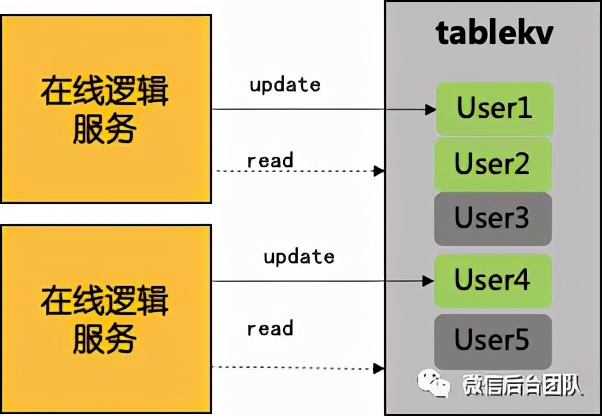
① 用tablekv的一个表来存在线列表,每行记录用户id和活跃时间;
② 定期更新用户的心跳时间,维护在线。
优点:解决了换机跳变问题,数据做到了分布式。
缺点:1500w在线10s心跳一次 => 9000w/min,穿透写单表有并发和性能问题;离线不会实时从磁盘删数据,历史活跃人数远大于当前在线,造成数据冗余。
逐点击破,单key是可以通过拆key来解决的,数据冗余可以通过key-val存储做全量替换解决,而穿透问题其实可以参考recvsvr的实现方式。因此,我们得到一个比较好的方案:拆key + 读写分离 + 异步聚合落盘。
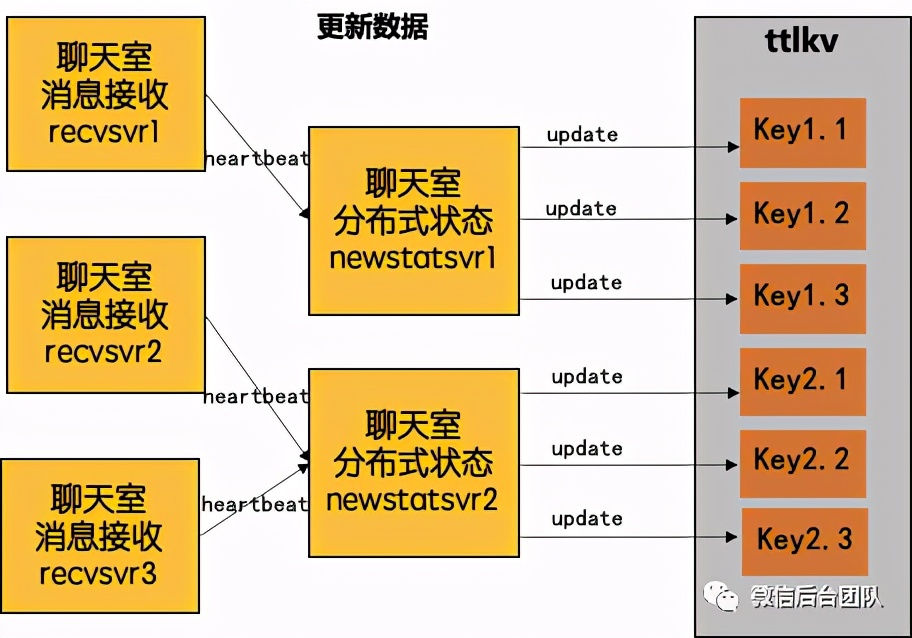
① 分布统计 :
(1) 每台机负责部分在线统计;
(2) 每台机内按uin哈希再分多shard打散数据;
(3) 每个shard对应kv的一个key;
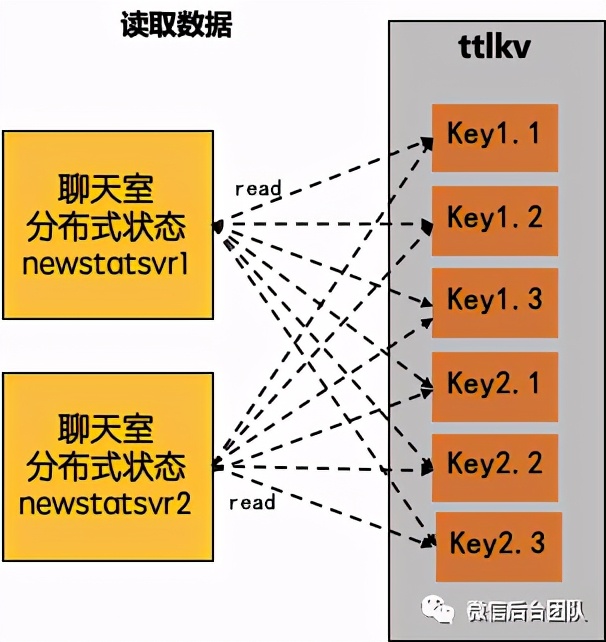
② 组合数据:让每台机都拉取所有key的数据,组合出一个完整的在线列表;
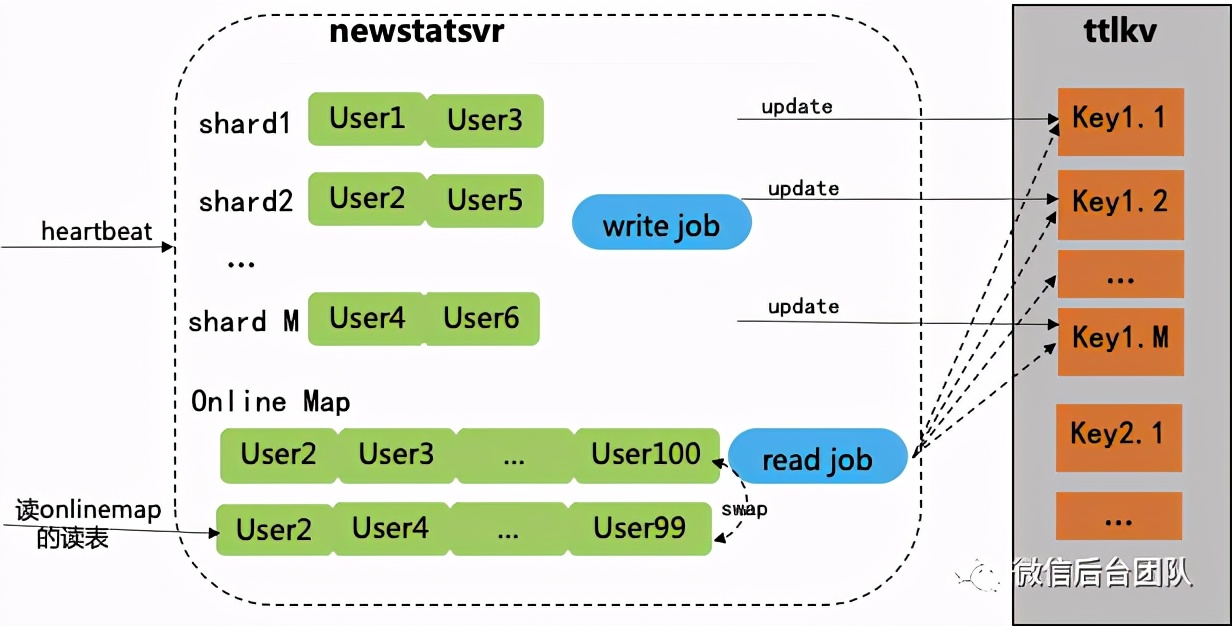
③ 异步聚合更新:心跳只更新内存,异步任务清理离线用户,并把列表序列化到一个key的val;
④ 异步拉取:由异步任务来执行②的拉取和组合数据;
⑤ 原子切换:完整的在线列表做双指针,利用原子操作无锁切换,做到无锁查询。
由此,我们提高了心跳更新和在线查询的性能,做到了在线统计模块的分布式部署和可平行扩展。
基于hyperloglog的历史在线统计
历史在线统计,是要曾经看过该直播的用户数uv,在产品上的体验就是视频号直播的“xxx人看过”。
在分布式在线统计的章节,我们已经谈到了,用tablekv来记录成员列表是不太可行的。
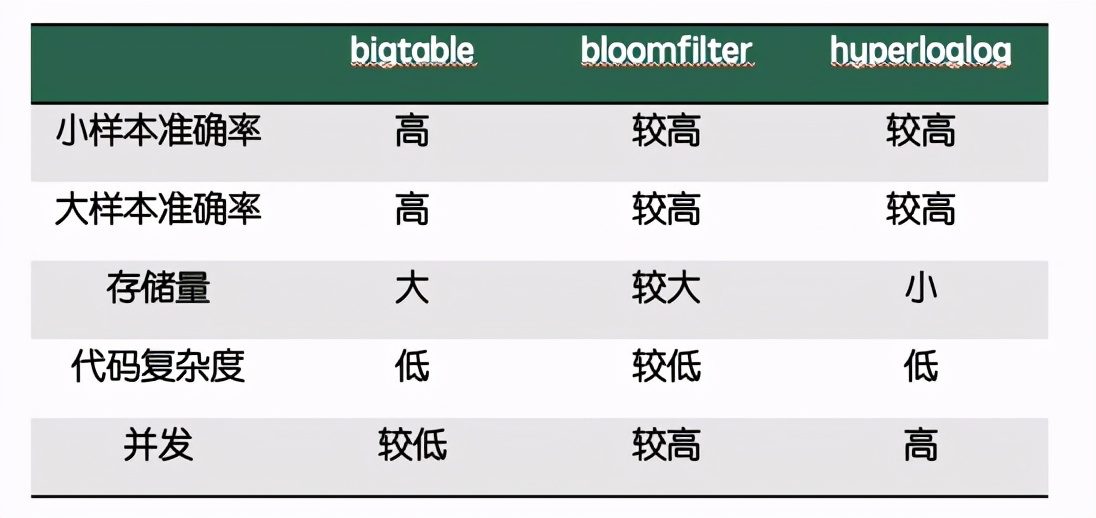
另外一个想法,是利用bloomfilter做数据压缩和去重统计,额外去维护一个count做累加。那么这里有两点,一是bloomfilter和count之间要考虑一致性问题,二是bloomfilter准确率跟压缩率相关,较好的准确率还是需要比较大的数据量。
于是我们调研了业界的一些uv统计方案,最终找到了redis的hyperloglog,它以极小的空间复杂度就能做到64位整形级别的基数估算。
(1)hyperloglog是什么?
hyperLogLog 是一种概率数据结构,它使用概率算法来统计集合的近似基数,算法的最本源则是伯努利过程。
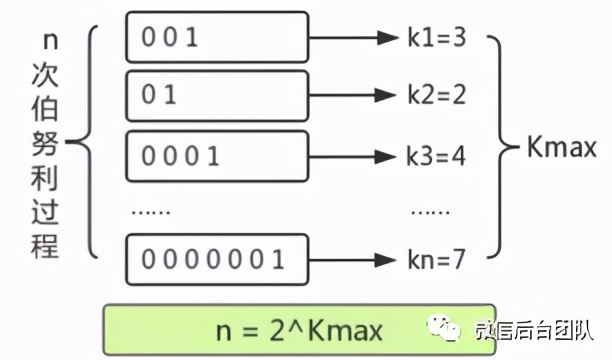
伯努利过程:设一个硬币反面为0,正面为1,抛一枚硬币直到结果为1为止。
如果做n次伯努利实验,记录每次伯努利过程需要抛硬币的次数为Ki,则可以估算n=2^Kmax。

hyperloglog对Kmax的计算进行了分桶和调和平均值优化,使得在准确率比裸的伯努利估算要高:
① 将要统计的数据hash成一个64位整形;
② 用低14位来寻找桶的位置;
③ 剩下的高位里寻找第一个1出现的位置,作为上述伯努利过程的Ki;
④ 对桶的值进行更新 Rj = max(Rj, Ki);
⑤ 估算时,对各个桶的值算调和平均值DV来替代上述的Kmax。
从上述算法的描述来看,hyperloglog无非就是存了m个桶的数值(m=10000+),本来空间复杂度也不高了。再通过一些位压缩,hyperloglog把整个数据结构优化到了最大空间复杂度为12K。
(2)tablekv+hyperloglog双管齐下
由于hyperloglog产生的毕竟是近似值,基数较少的时候误差会更明显,所以我们可以用tablekv来补全历史在线数较小时的体验。
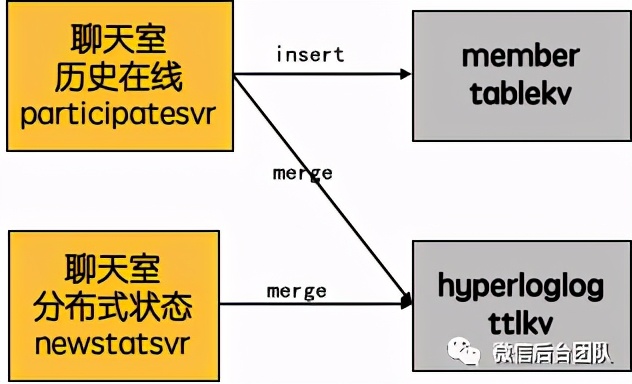
① 历史在线数较小时,双写tablekv + hyperloglog,以tablekv selectcount为准;
② 历史在线数较大时,只写hyperloglog,以hyperloglog估算值为准;
③ 在线统计模块定期把在线列表merge到hyperloglog避免丢数据。
最终我们达到的效果是,历史在线不超过1w时完全准确,超过1w时准确率大于95%。
流量隔离vipsect

大家都知道,大直播间会带来爆发式的请求量,我们不能让大直播间引起的失败影响占大多数的小直播间。另外大直播间影响力大,也要去保证它的良好体验,那需要用比小直播间更多的机器去支撑。而聊天室对kv层的请求数,跟机器数成正比,小直播间在多机器下会造成大量不必要的消耗。
对于这种情况,我们参考了微信支付应对大商户和小商户的方法,流量隔离,在聊天室的里设立vip sect。
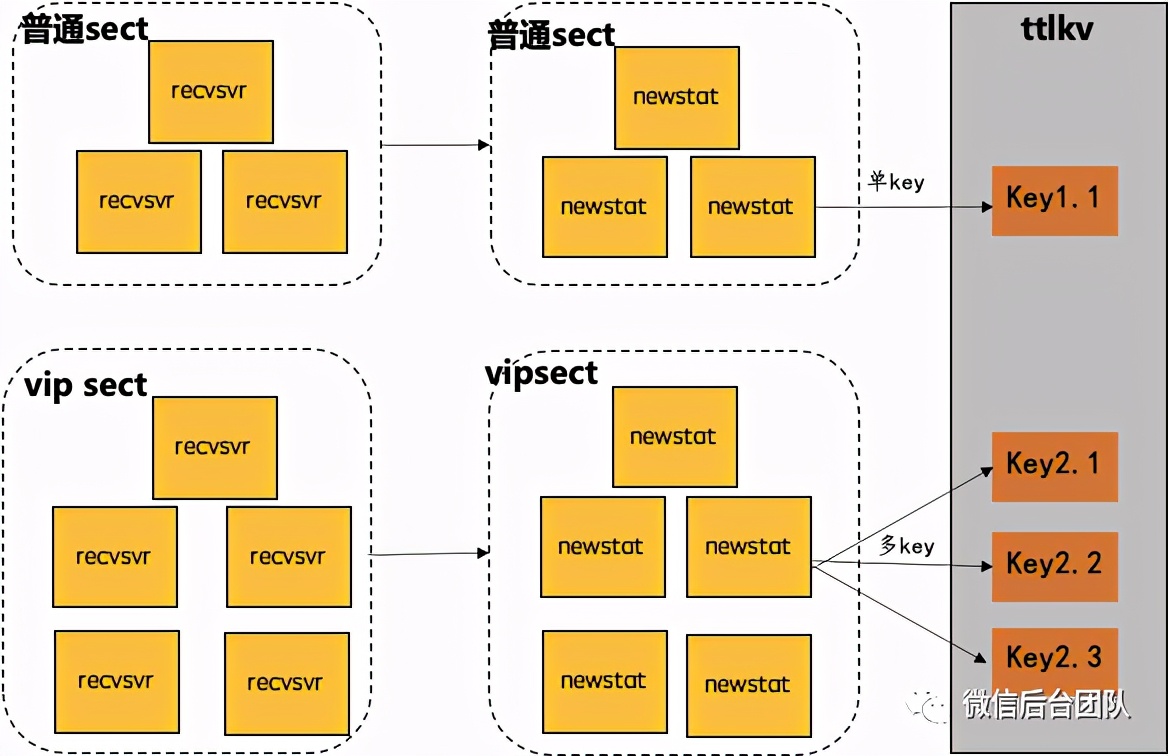
① 对可预测的大直播提前加白,直接走vip sect;
② 其它直播直走普通sect;
③ 大小直播策略分级,大直播在线列表才拆key。
虽然还有些依赖运营,但是通过这种方式,我们切走大部分的大直播流量,也降低了整个系统对kv层的压力。
Q:为什么不做自动切vip sect ?
A:是一个future work,目前有了一些初步方案,还需要去验证切换过程带来影响,进一步细化策略,也欢迎大家提出宝贵建议。
自动柔性下的流量把控

在longpolling的机制下,直播间一直有消息的话,100w的在线每分钟至少会产生6kw/min的请求,而1500w更是高达9亿/min。logicsvr是cpu密集型的服务,按30w/min的性能来算,至少需要3000台。所以这个地方必须要有一些柔性措施把控请求量,寻找一个体验和成本的平衡点。
而这个措施一定不能通过logicsvr拒绝请求来实现,原因是longpolling机制下,客户端接收到回包以后是会马上发起一次新请求的。logicsvr拒绝越快,请求量就会越大,越容易造成滚雪球。
回到longpolling机制,我们可以发现,正常运行下,recvsvr没有新消息时,是可以让请求挂在proxy层hold住,等待连接超时或者longpolling notify的。
所以,我们可以利用这个特性,柔性让请求或者回包在proxy hold一段时间,来降低请求频率。

① 根据不同的在线数设定收取间隔;
② 客户端上下文里增加字段,记录上一次成功收取的时间;
③ 成功收取后的一个时间间隔内,请求hold在proxy层;
④ 根据不同的在线数丢弃longpolling notify。
根据400w在线的压测效果,开启自适应大招时触发8~10s档位,请求量比没有大招的预期值降低58%,有效地控制了大直播间对logicsvr的压力。
成果
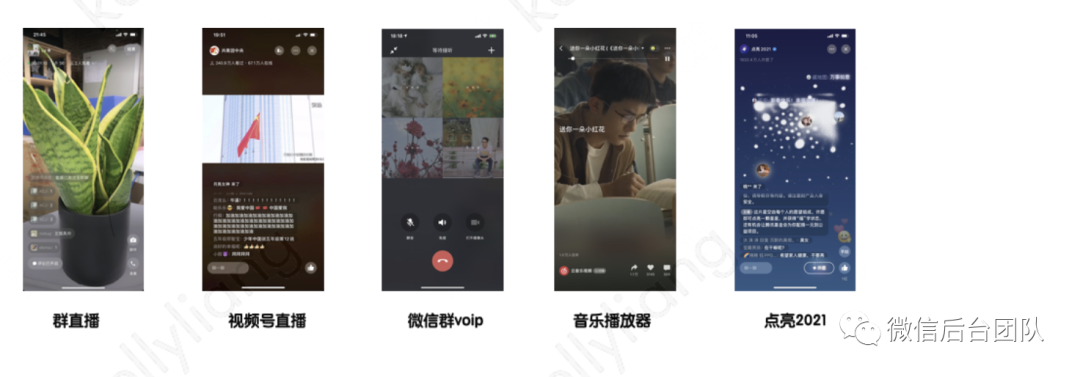
(1)支撑多个业务稳定运行
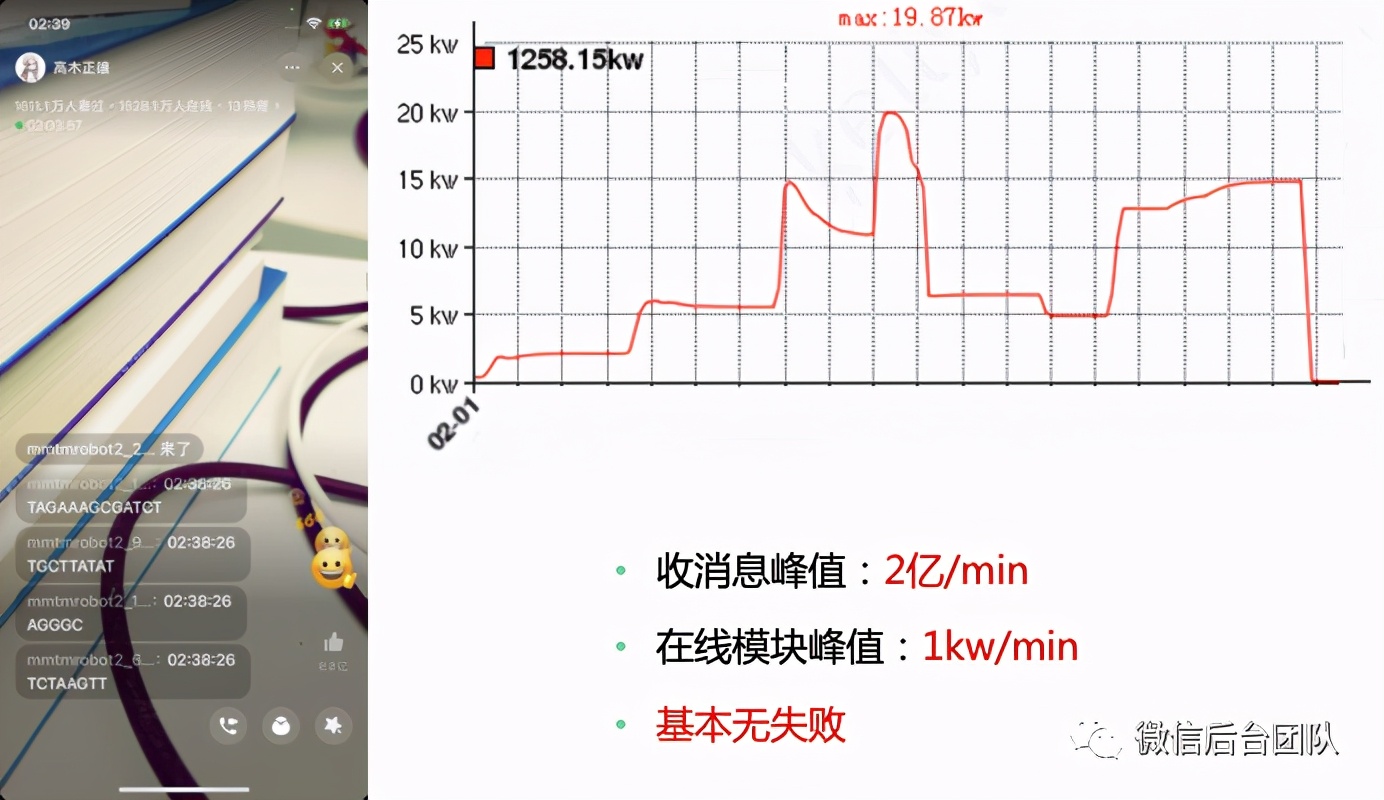
(2) 压测1500w同时在线
参考文献
https://zhuanlan.zhihu.com/p/77289303
https://www.jianshu.com/p/4748af30d194
总结与展望
我们通过抽象问题、精准分析、合理设计完成了liveroom2.0的迭代,从性能、可靠性、可扩展性、容灾等方面达到支撑单房间1500w同时在线甚至更高在线的标准。
在未来我们将继续优化,比如实现大房间自动从普通sect切换到vip sect,比如针对房间内个人的重要消息通道,使聊天室的功能和架构更加强大。
正文结束,欢迎来撩,亦期待您的加入!
微信团队诚招后台开发,JD如下,简历发送:[email protected]

