对于爬虫,很多伙伴首选的可能就是Python了吧,我们在学习Python爬虫的时候得有侧重点,这篇文章教大家如何快速掌握Python爬虫的核心!有不清楚的地方,可以留言!
1. 概述
本文主要实现一个简单的爬虫,目的是从一个百度贴吧页面下载图片。下载图片的步骤如下:
很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手。
很多已经做案例的人,却不知道如何去学习更加高深的知识。
那么针对这三类人,我给大家提供一个好的学习平台,免费领取视频教程,电子书籍,以及课程的源代码!
QQ群:701698587
(1)获取网页html文本内容;
(2)分析html中图片的html标签特征,用正则解析出所有的图片url链接列表;
(3)根据图片的url链接列表将图片下载到本地文件夹中。
2. urllib+re实现
#!/usr/bin/python
# coding:utf-8
# 实现一个简单的爬虫,爬取百度贴吧图片
import urllib
import re
# 根据url获取网页html内容
def getHtmlContent(url):
page = urllib.urlopen(url)
return page.read()
# 从html中解析出所有jpg图片的url
# 百度贴吧html中jpg图片的url格式为:<img ... src="XXX.jpg" width=...>
def getJPGs(html):
# 解析jpg图片url的正则
jpgReg = re.compile(r'<img.+?src="(.+?\.jpg)" width') # 注:这里最后加一个'width'是为了提高匹配精确度
# 解析出jpg的url列表
jpgs = re.findall(jpgReg,html)
return jpgs
# 用图片url下载图片并保存成制定文件名
defdownloadJPG(imgUrl,fileName):
urllib.urlretrieve(imgUrl,fileName)
# 批量下载图片,默认保存到当前目录下
def batchDownloadJPGs(imgUrls,path ='./'):
# 用于给图片命名
count = 1
for url in imgUrls:
downloadJPG(url,''.join([path,'{0}.jpg'.format(count)]))
count = count + 1
# 封装:从百度贴吧网页下载图片
def download(url):
html = getHtmlContent(url)
jpgs = getJPGs(html)
batchDownloadJPGs(jpgs)
def main():
url = 'http://tieba.baidu.com/p/2256306796'
download(url)
if __name__ == '__main__':
main()
运行上面脚本,过几秒种之后完成下载,可以在当前目录下看到图片已经下载好了:
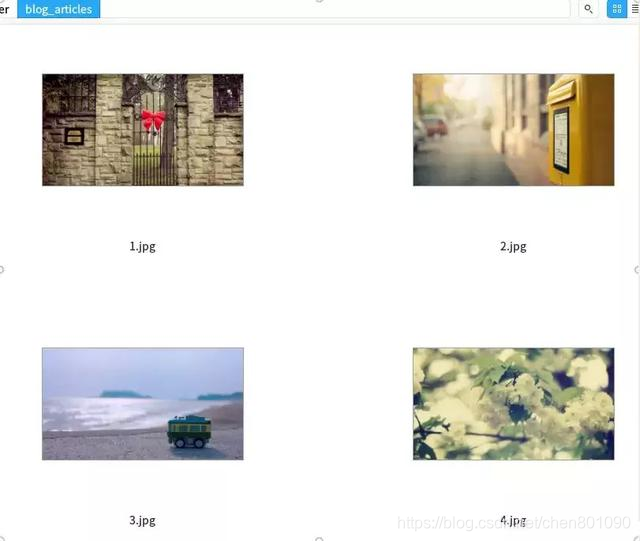
3. requests + re实现
下面用requests库实现下载,把getHtmlContent和downloadJPG函数都用requests重新实现。
#!/usr/bin/python
# coding:utf-8
# 实现一个简单的爬虫,爬取百度贴吧图片
import requests
import re
# 根据url获取网页html内容
def getHtmlContent(url):
page = requests.get(url):
return page.text
# 从html中解析出所有jpg图片的url
# 百度贴吧html中jpg图片的url格式为:<img ... src="XXX.jpg" width=...>
def getJPGs(html):
# 解析jpg图片url的正则
jpgReg = re.compile(r'<img.+?src="(.+?\.jpg)" width') # 注:这里最后加一个'width'是为了提高匹配精确度
# 解析出jpg的url列表
jpgs = re.findall(jpgReg,html)
return jpgs
# 用图片url下载图片并保存成制定文件名
def downloadJPG(imgUrl,fileName):
# 可自动关闭请求和响应的模块
from contextlib import closing
with closing(requests.get(imgUrl,stream = True)) as resp:
with open(fileName,'wb') as f:
for chunk in resp.iter_content(128):
f.write(chunk)
# 批量下载图片,默认保存到当前目录下
defbatchDownloadJPGs(imgUrls,path ='./'):
# 用于给图片命名
count = 1
for url in imgUrls:
downloadJPG(url,''.join([path,'{0}.jpg'.format(count)]))
print '下载完成第{0}张图片'.format(count)
count = count + 1
# 封装:从百度贴吧网页下载图片
def download(url):
html = getHtmlContent(url)
jpgs = getJPGs(html)
batchDownloadJPGs(jpgs)
def main():
url = 'http://tieba.baidu.com/p/2256306796'
download(url)
if __name__ == '__main__':
main()
输出:和前面一样。
希望这次简单的python爬虫小案例能帮到初入Python爬虫的你!