目录
1、OpenStack架构
学习Openstack的部署和运维之前,应当熟悉其架构和运行机制,OpenStack作为开源、可扩展、富有弹性的云操作系统,其设计基本原则如下:
■ 按照不同的功能和通用性划分不同项目,拆分子系统
解读:按照不同功能划分不同服务,将一个整体功能拆分成各个子功能,并且服务之间相互隔离,只通过API作为统一交互入口相互对接,方便管理,排障
■ 按照逻辑计划、规范子系统之间的通信
解读:API之间进行交互会有特定/通用的方式,之间相互隔离,各个子功能模块之间只会通过一个公共的api进行交互/通讯,对不同组件之间的通讯方式进行规范,各个子功能模块遵循一些规范进行通讯 (API、HTTP)
■ 通过分层设计整个系统架构
解读:
分层(以架构为单位),三层:
● 全局组件
● 辅助组件
● 核心组件
以单个核心服务/组件进行分层(各组件内部):
● API(进行预处理)
定位:内外(相对)统一的交互入口(集中化管理方式)
优点:便于集成,方便管理,集中化
◆ 向keystone进行申请认证请求的合法性和权限
◆ 下发任务,会根据请求的功能需求,将不同的任务交给不同的组件来完成,统一收集结果和需要提供的资源,整合在一起,响应请求
● 子功能模块(执行具体的功能处理)
● 其他(rabbitmq,承载了OpenStack组件内部通讯/数据交互/传输的消息代理)
注:消息代理
各组件内部,各子功能模块之间通讯都可以通过消息队列/代理(rabbitmq)进行通讯
作为组件和组件通讯/交互/数据传输的载体
■ 不同的功能子系统间提供统一的API接口
解读:
各组件之间通过统一的API接口进行交互/通讯/数据传输/调用
2、OpenStack概念架构图

解析架构图:
以架构维度分为全局组件,核心组件,辅助组件
■ 全局组件
Keystone
管理全局认证和授权的组件
Ceilometer
监控集群的状态,监控集群虚拟机的使用量
Horizon
控制台可以控制OpenStack架构内部的所有功能
■ 辅助组件
Ironic裸金属
管理和控制基础硬件资源
Trove 管理数据库的服务
管理关系型数据库和非关系型数据库,可以存储虚拟机和各组件调用的数据,以及各种日志
Heat和Sahara
做数据的分析,编排和处理,精细化的管理
■ 核心组件(为虚拟机/实例提供服务)
Glance
提供发现、注册和下载的镜像服务,虚拟机镜像的集中式仓库
通过虚拟机镜像创建虚拟机,对镜像进行精细化管理,提供管理镜像的服务(快照),修改镜像的元数据
Neutron
实现实例与实例之间以及实例与外部网络之间的通信
Cinder
提供对Volume从创建到删除整个生命周期的管理
swift
使用普通硬件来构建冗余的、可扩展的分布式对象存储集群,存储容量可达PB级
Swift属于对象存储,用于永久类型的静态数据的长期存储(如虚拟机镜像、图片存储、邮件存储和存档备份)
Nova
负责虚拟机实例的生命周期管理、网络管理、存储卷管理、用户管理以及其他的相关云平台管理功能,支持虚拟机核心资源的横向扩展,支持虚拟机数量的横向扩展(将资源提供给虚拟机)
总结:
云平台用户在经过Keystone服务认证授权后,通过Horizon或者Reset API模式创建虚拟机服务,创建过程中包括利用Nova服务创建虚拟机实例,虚拟机实例采用Glance提供镜像服务,然后使用Neutron为新建的虚拟机分配IP地址,并将其纳入虚拟网络中,之后在通过Cinder创建的卷为虚拟机挂载存储块,整个过程都在Ceilometer模块资源的监控下,Cinder产生的卷(Volume) 和Glance提供的镜像(Image)可以通过Swift的对象存储机制进行保存
3、OpenStack逻辑架构图
注:主要介绍了OpenStack内部各组件的通讯/对接方式
组件与组件之间的通讯
组件内部,子功能模块之间的通讯

■ OpenStack包括若干个称为OpenStack服务的独立组件。所有服务均可通过一个公共身份服务进行身份验证。除了那些需要管理权限的命令,每个服务之间均可通过公共API/HTTP方式进行交互
例:
httpd承载API,HTTPD提供了一个展示web页面的方式,并且表示是以HTTP进行通讯
解读:
以架构的维度来理解
openstack分为多个核心组件,核心组件之间仅通过一个公共的API进行对接/通讯,同时每个核心组件,都由一个对应的用户进行管理(会对用户进行授权)
■ 每个OpenStack服务又由若干组件组成。包含多个进程。所有服务至少有一个API进程,用于侦听API请求,对这些请求进行预处理,并将它们传送到该服务的其他组件。除了认证服务,实际工作都是由具体的进程完成的
■ 至于一个服务的进程之间通信, 则使用AMQP消息代理。服务的状态存储在数据库中
解读:为什么用消息代理
因为OpenStack服务架构非常复杂,庞大,需要处理的数据量非常的多,对消息传递的速率和效率及合理性会有一个比较严格的划分,所以需要使用队列,AMQP消息代理去作为中间的承载,而这个承载的服务就是rabbitmq
总结:
■ 首先展示了内部核心组件、辅助组件、全局组件(哪些组件,各组件的功能)
■ 各核心/辅助组件之间是怎么对接的(API进行对接,通讯的方式可以为消息代理)
■ 展示了各组件中,一部分核心的功能模块(各组件内部分层),以及单个功能模块之间如何通讯
● API:内外交互的入口
● 子功能模块:执行具体功能处理
● 消息代理:(承载数据,进行传输)
■ 展示OpenStack原生架构(基础,没有展示第三方的功能模块)
注:第三方功能模块
● 辅助原生架构的组件可以更完善更合理的运行
● 增加一些功能(原生架构没有或者不完善的-特定场景)
4、OpenStack组件通信关系
■ 基于AMQP协议的通信
● 用于每个项目内部各个组件之间的通信
■ 基于SQL的通信
● 用于各个项目内部的通信
■ 基于HTTP协议进行通信
● 通过各项目的API建立的通信关系,API都是RESTful Web API
解读:
◆ restful
是一种交互/通讯的规范,总是以HTTPS安全的方式进行对接的
◆ 为什么是web
由apache承载了API,并且提供了一个web展示页面,通过网页URL或者网址路径的形式,因为是点到点的对接
◆ 为什么是apache
主要是因为OpenStack和apache都是一种模块化的设计,适应性会更好
◆ API
组件和组件对接的技术(点到点)
■ 通过Native API实现通信
● OpenStack各组件和第三方软硬件之间的通信
5、OpenStack物理架构图
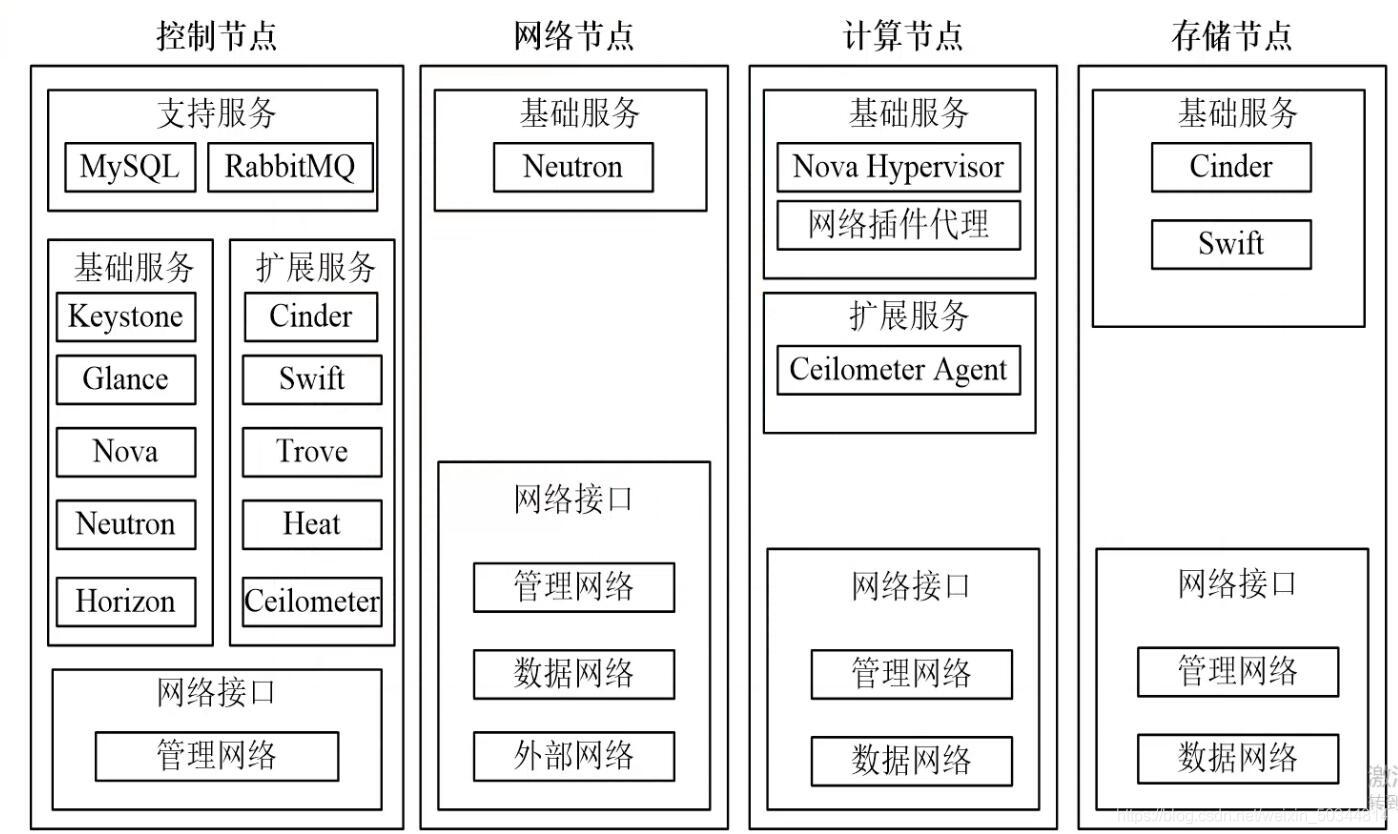
解读:
按照职能划分
■ 控制节点:掌控全局,分发任务,主要管理其他节点,可以跑实例资源(处理具体任务)
● 管理网络:是通过网卡的职能进行划分,管理其他节点
● Neutron:集中化管理
■ 网络节点:提供了OpenStack内部各组件之间的通讯
● Neutron:具体实现网络资源和网络功能
● 管理网络:接受控制节点的任务调度/请求,并且将数据返回
● 数据网络:数据库服务,数据存储,数据对接,关联和同步,和计算节点中的数据网络进行关联
● 外部网络:负责和第三方组件进行对接,关联和集成
■ 计算节点:负责具体的实例创建,资源管理,精细化的具体操作
● Nova Hypervisor:跑的具体实例
◆ 为什么放在计算节点
最大化节省资源和网络带宽,更为合理的调度使用资源
● 网络插件代理:在OpenStack中,是通过插件和代理来实现网络二层、三层的具体功能
● Ceilometer Agent:定向管理和监控并且统计资源,把资源统计给 控制节点中的Ceilometer组件,计算出具体的资源使用量,并且按量收费
● 数据网络:和数据库进行对接,把使用的资源量存储到数据库里面
● 管理网络:接受控制节点的调度和管理
■ 存储节点:提供存储服务
Cinder:块存储,为实例提供持久化存储,接受控制节点Nova组件的调度
Swift:对象存储,提供镜像存储
数据网络:把存储资源供给计算节点里的实例去使用
5.1、网络节点(Network Node)
通过插件和代理的方式实现网络功能以及通过服务提供的对象来划分的
■ 提供者网络(Provider networks )
■ 自服务网络(Self-service networks)
注:
网络节点通常需要3个网络端口,分别用于与控制节点进行通信、与除控制节点之外的计算和存储节点之间的通信、外部的虚拟机与相应网络之间的通信


小结:
● openstack网络类型(以功能划分)有两种
◆第一个是内部网络,第二个是外部网络
● openstack 的网络功能,是通过插件、代理的方式来实现
6、总结
Openstack主要就是分层和隔离,掌握Openstack架构图能对Openstack有更好的理解