1.可分离卷积
#coding:utf-8
import torch.nn as nn
class DWConv(nn.Module):
def __init__(self, in_plane, out_plane):
super(DWConv, self).__init__()
self.depth_conv = nn.Conv2d(in_channels=in_plane,
out_channels=in_plane,
kernel_size=3,
stride=1,
padding=1,
groups=in_plane)
self.point_conv = nn.Conv2d(in_channels=in_plane,
out_channels=out_plane,
kernel_size=1,
stride=1,
padding=0,
groups=1)
def forward(self, x):
x = self.depth_conv(x)
x = self.point_conv(x)
return x
def deubg_dw():
import torch
DW_model = DWConv(3, 32)
x = torch.rand((32, 3, 320, 320))
out = DW_model(x)
print(out.shape)
if __name__ == '__main__':
deubg_dw()2.DBnet论文中的DBhead

#coding:utf-8
import torch
from torch import nn
class DBHead(nn.Module):
def __init__(self, in_channels, out_channels, k=50):
super().__init__()
self.k = k
self.binarize = nn.Sequential(
nn.Conv2d(in_channels, in_channels // 4, 3, padding=1),
nn.BatchNorm2d(in_channels // 4),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(in_channels // 4, in_channels // 4, 2, 2),
nn.BatchNorm2d(in_channels // 4),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(in_channels // 4, 1, 2, 2),
nn.Sigmoid())
self.binarize.apply(self.weights_init)
self.thresh = self._init_thresh(in_channels)
self.thresh.apply(self.weights_init)
def forward(self, x):
shrink_maps = self.binarize(x)
threshold_maps = self.thresh(x)
if self.training:#从父类继承的变量, train的时候默认是true, eval的时候会变为false
binary_maps = self.step_function(shrink_maps, threshold_maps)
y = torch.cat((shrink_maps, threshold_maps, binary_maps), dim=1)
else:
y = torch.cat((shrink_maps, threshold_maps), dim=1)
return y
def weights_init(self, m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
nn.init.kaiming_normal_(m.weight.data)
elif classname.find('BatchNorm') != -1:
m.weight.data.fill_(1.)
m.bias.data.fill_(1e-4)
def _init_thresh(self, inner_channels, serial=False, smooth=False, bias=False):
in_channels = inner_channels
if serial:
in_channels += 1
self.thresh = nn.Sequential(
nn.Conv2d(in_channels, inner_channels // 4, 3, padding=1, bias=bias),
nn.BatchNorm2d(inner_channels // 4),
nn.ReLU(inplace=True),
self._init_upsample(inner_channels // 4, inner_channels // 4, smooth=smooth, bias=bias),
nn.BatchNorm2d(inner_channels // 4),
nn.ReLU(inplace=True),
self._init_upsample(inner_channels // 4, 1, smooth=smooth, bias=bias),
nn.Sigmoid())
return self.thresh
def _init_upsample(self, in_channels, out_channels, smooth=False, bias=False):
if smooth:
inter_out_channels = out_channels
if out_channels == 1:
inter_out_channels = in_channels
module_list = [
nn.Upsample(scale_factor=2, mode='nearest'),
nn.Conv2d(in_channels, inter_out_channels, 3, 1, 1, bias=bias)]
if out_channels == 1:
module_list.append(nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=1, bias=True))
return nn.Sequential(module_list)
else:
return nn.ConvTranspose2d(in_channels, out_channels, 2, 2)
def step_function(self, x, y):
return torch.reciprocal(1 + torch.exp(-self.k * (x - y)))
def debug_main():
x = torch.rand((8, 256, 160, 160))
head_model = DBHead(in_channels=256, out_channels=2)
head_model.train()
y = head_model(x)
print('==y.shape:', y.shape)
head_model.eval()
y = head_model(x)
print('==y.shape:', y.shape)
if __name__ == '__main__':
debug_main()3.sENet中的attention
目的对于不同通道进行加权,先squeeze将h*w*c global averge pooling成1*1*c特征,在经过两层线性层,通过sigmoid输出加权在不同通道。


import torch
import torch.nn as nn
import torch.nn.functional as F
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1) # 压缩空间
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y
def debug_attention():
attention_module = SELayer(channel=128, reduction=16)
# B,C,H,W
x = torch.rand((2, 128, 100, 100))
out = attention_module(x)
print('==out.shape:', out.shape)
if __name__ == '__main__':
debug_attention()4.cv中的self-attention
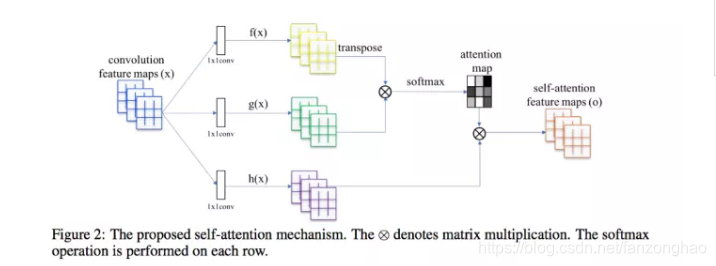
(1).feature map通过1*1卷积获得,q,k,v三个向量,q与v转置相乘得到attention矩阵,进行softmax归一化到0到1,在作用于V,得到每个像素的加权.
![]()
(2).softmax
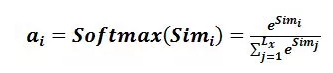
(3).加权求和
![]()
import torch
import torch.nn as nn
import torch.nn.functional as F
class Self_Attn(nn.Module):
""" Self attention Layer"""
def __init__(self, in_dim):
super(Self_Attn, self).__init__()
self.chanel_in = in_dim
self.query_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim // 8, kernel_size=1)
self.key_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim // 8, kernel_size=1)
self.value_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim, kernel_size=1)
self.gamma = nn.Parameter(torch.zeros(1))
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
"""
inputs :
x : input feature maps( B * C * W * H)
returns :
out : self attention value + input feature
attention: B * N * N (N is Width*Height)
"""
m_batchsize, C, width, height = x.size()
proj_query = self.query_conv(x).view(m_batchsize, -1, width * height).permute(0, 2, 1) # B*N*C
proj_key = self.key_conv(x).view(m_batchsize, -1, width * height) # B*C*N
energy = torch.bmm(proj_query, proj_key) # batch的matmul B*N*N
attention = self.softmax(energy) # B * (N) * (N)
proj_value = self.value_conv(x).view(m_batchsize, -1, width * height) # B * C * N
out = torch.bmm(proj_value, attention.permute(0, 2, 1)) # B*C*N
out = out.view(m_batchsize, C, width, height) # B*C*H*W
out = self.gamma * out + x
return out, attention
def debug_attention():
attention_module = Self_Attn(in_dim=128)
#B,C,H,W
x = torch.rand((2, 128, 100, 100))
attention_module(x)
if __name__ == '__main__':
debug_attention()5.spp多窗口pooling
import torch
import torch.nn as nn
import torch.nn.functional as F
class SPP(nn.Module):
"""
Spatial Pyramid Pooling
"""
def __init__(self):
super(SPP, self).__init__()
def forward(self, x):
x_1 = F.max_pool2d(x, kernel_size=5, stride=1, padding=2)
x_2 = F.max_pool2d(x, kernel_size=9, stride=1, padding=4)
x_3 = F.max_pool2d(x, kernel_size=13, stride=1, padding=6)
x = torch.cat([x, x_1, x_2, x_3], dim=1)
return x
def debug_spp():
x = torch.rand((8,3,256,256))
spp = SPP()
x = spp(x)
print('==x.shape:', x.shape)
if __name__ == '__main__':
debug_spp()![]()