一般情况下,我们经常会创建大量的线程为我们完成分配的工作,但是有时候频繁的创建销毁线程也会给系统带来很大的损耗,因此,为了避免带给系统不必要的损耗和重复造轮子,我们引入了线程池的概念。本篇文章主要讲解线程的实现原理。
请尊重劳动成果,转载标明原文地址:不清不慎的博客
所谓线程池,就是一次性创建出多个线程,当一个任务到来的时候可以直接从线程池中获取一个线程来执行任务,不需要去创建;当任务执行完毕,直接将线程还给线程池,不需要销毁。这里做避免了频繁的创建和销毁带来的消耗。
为了能够更好地控制多线程,JDK提供了一套Executor框架,帮助程序员对线程进行有效的控制,其核心就是线程池,其核心成员关系图如下:
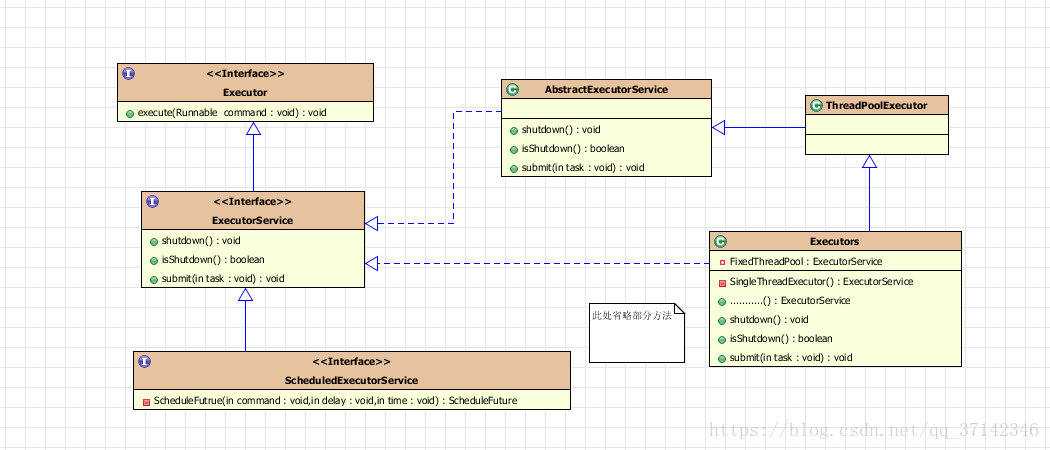
Executor接口有两个子接口ExecutorService和ScheduledExecutorService。AbstractExecutorService实现了ExecutorService接口,ThreadPoolExecutor扩展了抽象类AbstractExecutorService,而Executors类是线程池的工厂类,里面有多个静态方法创建相应的线程。
在Executors中主要以下几个静态方法:
newFixedThreadPool(int nThreads)
newSingleThreadExecutor()
newCachedThreadPool()
newSingleThreadScheduledExecutor()
newScheduledThreadPool(int corePoolSize) newFixedThreadPool(int nThreads):创建指定数目线程的线程池,当提交一个任务时,若线程池中有空闲线程,则立即执行,如果没有就暂时放入一个队列汇总等待执行。
newSingleThreadExecutor():创建只有一个线程的线程池,若有多余的线程提交,会被保存到一个队列中等待执行,按照先进先出的顺序执行。
newSingleThreadScheduledExecutor():创建只有一个线程的线程池,但是返回ScheduleExecutorService类,该类扩展了在给定时间执行任务的功能。
newScheduledThreadPool(int corePoolSize):该类也返回ScheduleExecutorService类,可以指定线程池的线程数目。
上面的几个静态方法可以根据实际需求创建相应的线程池,这里主要讲解一下newScheduledThreadPool(int corePoolSize)方法,它返回ScheduleExecutorService类,可以根据时间需要对线程进行调度。主要方法如下:
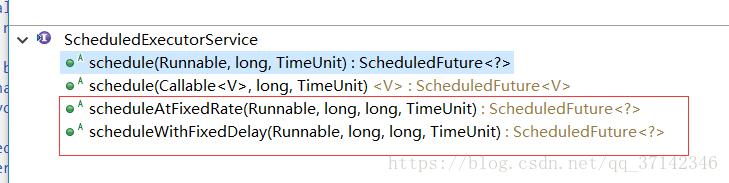


scheduleAtFixedRate方法的调度频率是一定的,它是以上一个任务开始执行的时间为起点,在之后的period时间,调度下一次任务,也就是说后续第一个任务会在initialDelay+period时执行,第二个会在initialDelay+2*period时执行,以此类推。而scheduleWithFixedDelat方法则是以上一个任务结束后,再经过delay时间进行调度任务,即上一个任务的结束时间与下一个任务的开始时间的时间差。
在介绍完线程池的核心组件之后,我们来一起看看它的内部实现。
对于上述几个静态工厂方法,它的底层使用了ThreadPoolExecutor类实现。
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}它们都创建了ThreadPoolExecutor类,因此所谓的线程池也就是在ThreadPoolExecutor类中创建。下面来看看ThreadPoolExecutor类最重要的构造器的源码:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)corePoolSize是创建线程池的大小;maximumPoolSize为线程池的最大线程数目;keepAliveTime为超过corePoolSize数目的线程的最长存活时间;unit为keepAliveTime的时间单位;workQueue为任务队列,被提交但是没有被执行的任务的任;threadFactory线程工厂;handler拒绝策略。
主要来看看workQueue任务队列,这个队列是指被提交但是尚未执行的线程队列,是BlockingQueue接口的实现类。主要有下面几种队列。
1.直接提交队列:主要由BlockingQueue接口的实现类SynchronousQueue完成,SynchronousQueue没有容量,每一个插入的任务都要等待一个删除的操作,也就是说一个任务到来,必须删除一个任务才能将这个任务插入,如果这个队列被使用,提交的任务不会被真实保存,而是总是将新来的任务提交。如果没有空闲的进程则尝试创建一个进程,如果进程数达到了最大数目则执行拒绝策略。
2.有界任务队列:由ArrayBlockingQueue类实现,它的底层由数组实现,可以指定队列的大小,当一个新任务到来,如果线程池的线程数目没有达到指定的线程池数目大小,则会优先创建线程,如果达到了指定的数目,则在不超过最大值的前提下创建线程运行任务,否则就执行拒绝策略。
3.无界队列:由LinkedBlockingQueue类实现,它的底层是链表是实现,这个队列没有大小,也就是可以放置很多任务,但是它是存放在内存当中的,如果任务太多则会撑爆内存。当有新任务到来的时候,如果线程池大小没有达到指定的大小则创建线程让任务执行,如果达到了指定线程的数目,并且没有空闲线程则将新来的任务放入等待队列中等待执行。
4.优先队列:它通过PriorityBlockingQueue实现,它可以根据任务的优先级大小先后执行任务。
因此,我们在自定义线程池的时候,需要选定合适的并发队列来作为缓冲,提高线程池的性能以及系统的性能。
下面看看ThreadPoolExecutor线程池的核心调度源码:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
/*
* Proceed in 3 steps:
*
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
*
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
*
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.
*/
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}
解释一下上面的代码执行流程:当提交一个任务的时候,线程池的线程数目小于coresize时,调用addWorker(command, true)函数,分配线程执行该任务;如果线程池的线程数目大于coresize时,则将任务提交到等待队列中,如果成功,则会等待执行,如果失败则会将任务直接提交到线程池,如果当前线程数目没有达到maximumPoolSize,则会提交失败,执行拒绝策略。
addWorker(Runnable firstTask, boolean core)函数的第一个参数是提交的任务,第二个参数是一个boolean型的参数,表示当前线程是否为线程池的核心线程,即coresize以内的线程。
ThreadPoolExecutor的最后一个参数指定的是拒绝策略,也就是说当任务超过了系统所能承载的能力时,该如何处理呢?下面我们来看看JDK内置的四种拒绝策略:
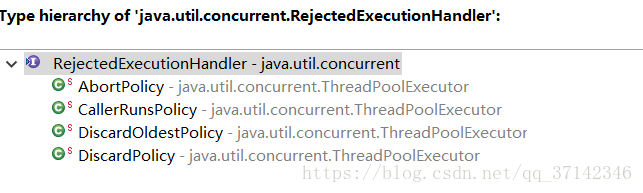
AbortPolicy策略:该策略会直接抛出异常,阻止系统正常工作。
CallerRunsPolicy策略:只要线程池没有关闭,则直接在调用者线程中运行当前被丢弃的任务。因此,该策略不会直接丢弃任务,但是提交的线程可能会因此性能急剧下降。
DiscardOldestPolicy策略:该策略丢弃最老的一个请求,并尝试提交当前请求。
DiscardPolicy策略 :该策略会直接丢弃请求,不做任何处理。
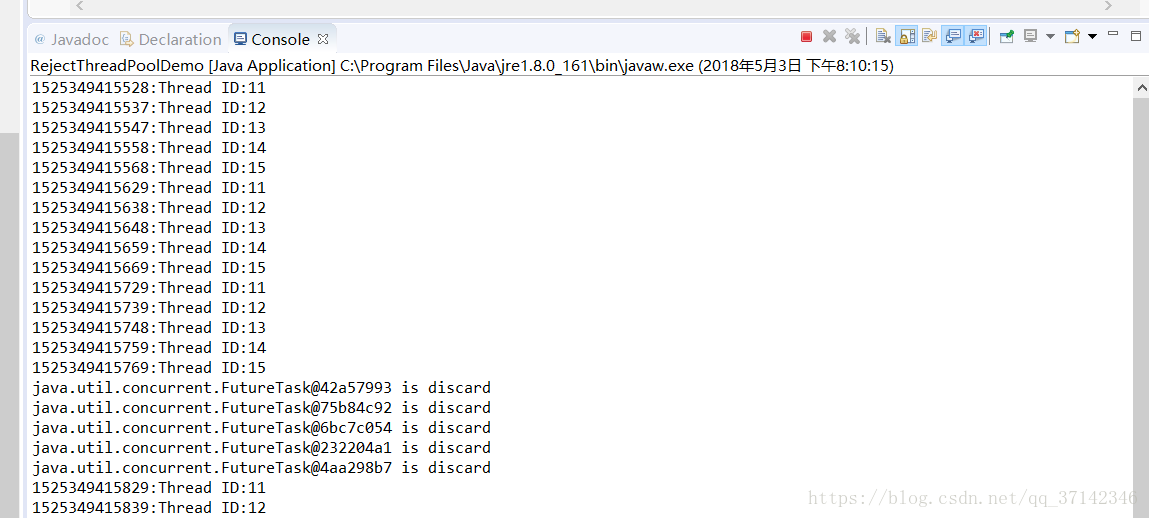
从上面的介绍中我们了解到了线程池的内部原理,所以我们可以在实际应用自定义线程池来完成相应的任务,下面来看一个例子,定义了一个大小为5的线程池,并且线程数目的最大值也为5,等待队列使用有界队列LinkedQueue,大小为10,当提价的任务过多的时候就会撑爆内存,这里打印了丢弃任务的信息,没有抛出异常。代码如下:
package cn.just.thread.concurrent;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.RejectedExecutionHandler;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class RejectThreadPoolDemo {
public static class MyTask implements Runnable{
@Override
public void run() {
System.out.println(System.currentTimeMillis()+":Thread ID:"+Thread.currentThread().getId());
try{
Thread.sleep(100);
}catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) throws InterruptedException {
MyTask task=new MyTask();
ExecutorService es=new ThreadPoolExecutor(5, 5, 0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(10),
Executors.defaultThreadFactory(),
new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
//打印被抛弃的线程的信息
System.out.println(r.toString()+" is discard");
}});
for(int i=0;i<30;i++){
es.submit(task);
Thread.sleep(10);
}
}
}
运行部分结果如下:
至此,本篇文章介绍完了线程的原理以及如何自定义线程池,如有问题,欢迎留言探讨。