
凡是搞计量经济的,都关注这个号了
所有计量经济圈方法论丛的code程序, 宏微观数据库和各种软件都放在社群里.欢迎到计量经济圈社群交流访问.
关于相关计量方法视频课程,文章,数据和代码,参看 1.面板数据方法免费课程, 文章, 数据和代码全在这里, 优秀学人好好收藏学习!2.双重差分DID方法免费课程, 文章, 数据和代码全在这里, 优秀学人必须收藏学习!3.工具变量IV估计免费课程, 文章, 数据和代码全在这里, 不学习可不要后悔!4.各种匹配方法免费课程, 文章, 数据和代码全在这里, 掌握匹配方法不是梦!5.断点回归RD和合成控制法SCM免费课程, 文章, 数据和代码全在这里, 有必要认真研究学习!6.空间计量免费课程, 文章, 数据和代码全在这里, 空间相关学者注意查收!7.Stata, R和Python视频课程, 文章, 数据和代码全在这里, 真的受用无穷!
正文
关于下方文字内容,作者:郑泽博,中国农业大学经济管理学院,通信邮箱:[email protected]
Jonah B. Gelbach,When Do Covariates Matter? And Which Ones, and How Much? Journal of Labor Economics 2016 34:2, 509-543
Authors often add covariates to a base model sequentially either to test a particular coefficient’s “robustness” or to account for the “effects” on this coefficient of adding covariates. This is problematic, due to sequence sensitivity when added covariates are intercorrelated. Using the omitted variables bias formula, I construct a conditional decomposition that accounts for various covariates’ role in moving base regressors’ coefficients. I also provide a consistent covariance formula. I illustrate this conditional decomposition with NLSY data in an application that exhibits sequence sensitivity. Related extensions include instrumental variables, the fact that my decomposition nests the Oaxaca-Blinder decomposition, and a Hausman test result.
摘要:作者们经常将协变量按顺序添加到基本模型中,以检验某个特定系数的“稳健性”,或说明添加协变量对该系数的“影响”。这样做是有问题的。因为当添加的协变量相关时,序列顺序是敏感的。利用遗漏变量偏差公式,本文作者构造了一个条件分解,解释了各种协变量在改变基本回归元系数中的作用。作者还提供了一个一致的协方差公式。文章采用NLSY数据中显示了序列敏感性的例子来阐释这个条件分解。相关的扩展包括工具变量、本文分解嵌套了Oaxaca-Blinder分解和Hausman检验结果。
一、引言
当代经验性研究中,作者们往往会估计多个版本的线性回归模型。从一个基础模型开始,逐步添加更多的协变量。顺序添加的基本目的是评估某些感兴趣的变量图片的稳健性。第二个共同目的是一个算术问题:从不含图片协变量的基础模型到包含所有协变量的完整设定,图片系数的变化有多少可以归因于图片中的各种变量。
以黑人-白人工资差距为例。在这个例子中,Y代表工资对数,图片包括一个常量和一个代表一个人是否是黑人的虚拟变量(也可能包括一些其他的基线控制变量),图片包含各种观察到的协变量。这些协变量可能与工资有关,也可能在种族间系统地变化,例如教育年数和武装部队职业资格测验(AFQT)分数。目前回答这个算术问题的方法是,首先测量随着每一组新的协变量的增加,估计的种族虚拟变量的系数的变化,然后将此变化归因于最近添加的一组变量。这种方法的问题是,协变量进入回归的顺序会影响计算的结果。这个问题当然不是未知的。但正如作者在第二节讨论的那样,许多在其他方面优秀的论文都存在着顺序添加协变量从而作出稳健性或者分解分析的问题。在第三节,作者通过重温Neal和Johnson(1996)关于黑人-白人工资差距的著名研究来说明这个问题,表明使用顺序的协变量添加得出了关于AFQT和教育在解释差距中的重要性的截然不同的结果。教育要么稍微增加黑人-白人工资差距,要么大幅度缩小差距,这取决于教育和AFQT加入工资方程的顺序。这种非稳健性的出现是因为Lang和Manove(20006)之前指出的一个经验事实:黑人-白人教育差距很大程度上取决于是否以AFQT为条件。
因为一个本身对计算顺序不稳健的稳健性度量是有问题的,所以在第四节中,作者提供了一个选择——条件分解。这个方法基于最小二乘恒等式,通过遗漏变量偏差公式将基础和完整设定模型中估计的图片系数联系起来:图片。该分解法的一个优点是,它得到了经济上和计量上有意义的总体参数的一致估计。在黑人和白人工资差距的例子中,这个推导给出了“增加协变量的影响”的明确含义。协变量的变化增加还是减少差距取决于(a)协变量对工资是否有正向影响以及(b)协变量在黑人或白人中的平均值是否更高(在排除掉基础模型里图片中的其他变量的影响之后)。这些基本思想在计量经济学和统计学中有着悠久的历史。但样本遗漏变量偏差公式的分解有用性以前还没有被认识到。
由于作者的分解基于完整设定模型的参数估计,所以它是不随协变量添加顺序改变而改变的。而且它可以通过估计一组简单的辅助模型来实现。作者发现,分解后,在全国青年纵向调查样本(NLSY)中,控制了受教育程度、行业虚拟变量和职业虚拟变量之后,成绩的异质性解释了黑人-白人全部工资差距的三分之一。教育解释了不到10%的全部差距,就业职业的变化解释了大约20%的工资差距,而行业的变化几乎没有解释力。AFQT和教育的结果与通过至少一种顺序添加方法得到的结果大不相同。相比于之前通过任意排序来解决问题,作者的分解给出了清晰的有条件的答案。
二、文献中的例子
本节中作者举了两个按顺序添加协变量的例子。第一个例子是Altonji和Blank(1999)估算的各种与工人及其工作特征相关的工资模型。表1报告了他们对黑人虚拟变量系数的估计值,并提供了包含的协变量的详细信息。Altonji和Blank写道:“随着控制变量被添加到模型中,种族对小时工资的负面影响变得不那么重要了。在1995年,如果不包括控制变量,黑人男性的每小时工资比白人男性低21%;如果控制了教育、经验和地区,黑人男性的小时工资要低12%,而在包括全套控制变量的情况下,黑人男性的时薪比白人男性低9%”。
从这一讨论中得出的一个普遍的推论是,教育、经验和地区解释了黑人和白人工资差距的21%-12%=9%,而其他控制因素解释了12%-9%=3%。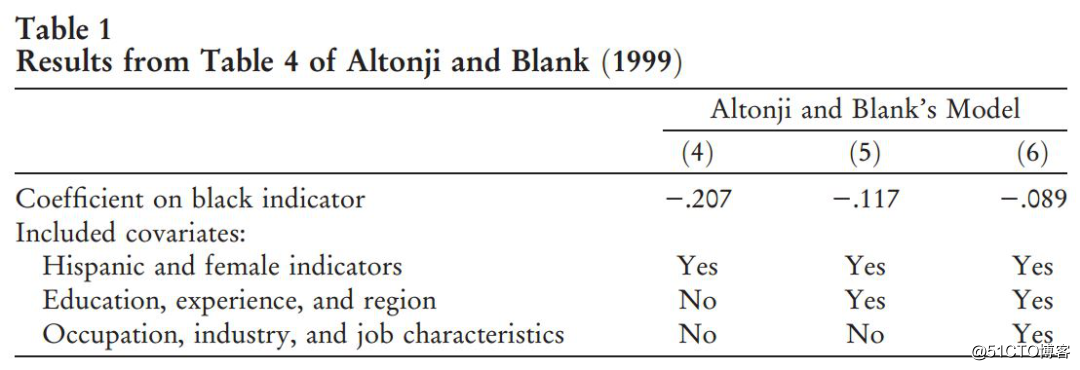
第二个例子是Levitt和Syverson(2008)使用芝加哥地区房屋销售的样本来检验代理人是否利用了其相比于委托人的信息优势。他们用所售房屋是否为房地产经纪人所有来估计房屋销售价格对数。委托代理问题的存在意味着代理虚拟变量系数为正。表2报告了Levitt和Syverson文中的结果。当只包括城市和年份的虚拟变量时,代理人虚拟变量的系数为12.8,作者将此视为基础模型设定。当每个城市逐年的虚拟变量和与家庭规模相关的基本特征(如卧室数量)包括在内时,代理人虚拟变量系数估计值降至4.8。Levitt和Syverson写道“代理所有和非代理所有的房屋之间的销售价格差异比按规模调整前获得的城市内部差价少几乎三分之二”。原文中接着添加了更详细的房屋质量指标、挂牌代理人的总销售额、房屋挂牌中各种关键字的指标以及街区的虚拟变量。如表2所示,第一个(基础)设定和最后一个(完整)设定之间的代理人虚拟变量系数的大部分变化发生在添加基本房屋特征时。Levitt和Syverson总结道,“代理人拥有的房屋与其他房屋不同的主要方面是规模和易于识别的便利设施。除了这些基本的变量,还包括一系列的控制,它们对代理关系的衡量影响相对较小”。
然而,规模和基本舒适度变量可能与房屋质量的详细指标、描述关键字和街区虚拟变量相关。因此,在添加基本规模和舒适性特征之前,添加这些其他协变量中的任何一组时,代理人虚拟变量的系数可能会改变同样多。如果没有条件计算方法,就不可能评估Levitt和Syverson关于无条件和有条件代理人变量效应差异原因的结论。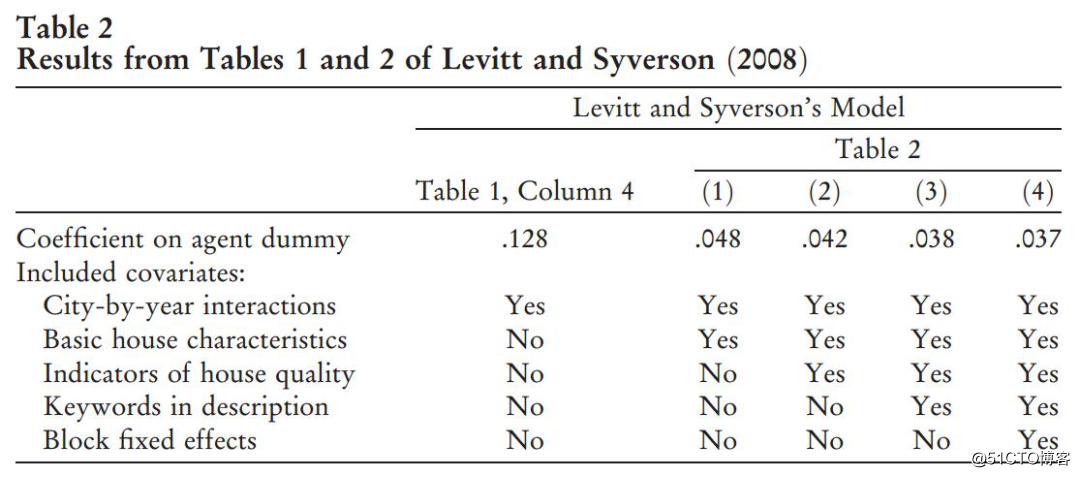
按顺序添加协变量的做法现在在经济学的无数子领域中都很普遍。作者并不是要批评这里所引用的作品;这些论文很有思想性、趣味性,而且在其他方面完成得很好。作者的批评仅限于通过顺序协变量添加进行推断的做法。
三、顺序添加和黑人-白人工资差异
本节中作者通过一个黑人-白人工资差距的实证例子,阐述了早已为人所知,但由于缺乏替代方法而常被忽视的问题:顺序添加协变量可以导致非常不同的结论,不同的协变量的贡献取决于他们的添加顺序。
这个例子基于Lang和Manove(2006)对Neal和Johnson(1996)的一项有影响力的研究的重新思考。Neal和Johnson认为,教育程度应该被排除在工资方程之外,因为教育决策可能是劳动力市场条件的内生因素。他们使用1997年NLSY数据来评估排除学校教育和控制个人AFQT成绩(一种常用的能力衡量方法)的影响。因为NLSY的受试者通常在他们完成学业之前进行AFQT测试,Neal和Johnson认为这个变量是一种基于劳动力市场信息的外生能力测量。
Neal和Johnson发现黑人和白人之间存在着无条件的巨大工资差距。当把受教育年限作为协变量时,这种差距很大程度上会持续存在。在表3中,作者用自己的NLSY样本报告了工资回归的结果,这个样本与Neal和Johnson的大致匹配。在A组的第一行,作者报告了四种不同方程设定下的种族虚拟变量的估计系数。所有的设定中都包括年龄和一个代表一个人是否是西班牙裔人的虚拟变量。第二列中的设定还包括受教育年限,第三列中的设定剔除了受教育程度,但包含了AFQT分数的测量,第四列中的设定同时包含了教育程度和AFQT。

当然,教育-AFQT顺序并不是唯一可能的序列。表3组B中的第二列报告了先添加AFQT成绩后添加教育变量的响应结果。比较A组第1列和第3列的估计值,可知AFQT波动解释了黑人-白人工资差距的14.9个对数点,占总差距的14.9/10.4=143%。同时,当将教育添加到第3列时,黑人-白人工资差距增加了4.5个对数点。也就是说教育的变化似乎缩小了黑人和白人之间的工资差距,所以保持教育不变会扩大差距。
这种违反直觉的结果是怎么产生的?正如Lang和Manove(2006)在他们的表2中证实的那样,样本中黑人的受教育年限比白人少,但在剔除AFQT分数的影响后,这种相关性的符号就逆转了。在表4中,作者报告了教育程度对黑人虚拟变量作回归的结果。两种设定都控制了年龄和西班牙裔变量。第一列的设定不包括任何其他协变量。它显示,到1990年,黑人平均比白人少完成0.37年的教育。在第2列中,作者将AFQT添加到这个辅助模型的协变量集合中。结果表明,以AFQT为条件,黑人比白人多接受一年以上的教育。正如作者在附录D中讨论的,教育程度与种族间关系符号的转变是理解表3中序列敏感性结果的关键。
表3中的结果可以理解为,黑人与白人间的教育差异要么使工资差距增加了2.5个对数点,要么缩小了近两倍。同时,黑人与白人间的分数差异要么将工资差距缩小了四分之三,要么增加了140%以上。如果认为教育程度和考试成绩都属于工资方程,那么从这些结果中得不到明确的选择依据,因为添加的顺序是任意的。
四、计算系数变化



将分解的部分加起来可以得到教育和AFQT一同解释了黑人-白人工资差距的10.4个对数点。这个数字正好等于表3中第1列和第4列之差。正如作者接着讨论的,这个等式是一个恒等式:样本遗漏变量偏差公式与基础和完整设定的系数估计值差异必然是相同的。


表6的下半部分报告了作者对黑人-白人工资差距的详细分解。AFQT的变化解释了7.06个对数点,超过了差距的解释部分的一半,接近总差距的三分之一。但还不到Neal和Johnson的设定中得出的数量的一半。受教育程度的差异解释了另外1.56个对数点。解释力并不大,尽管它是精确估计的。由12个职业虚拟变量测量的职业差异解释了黑人和白人工资差距的4.34个对数点。大约占到26个协变量解释的差距的三分之一,约占整个黑人-白人工资差距的20%。
在解释黑人-白人工资差距方面,行业差异基本上没有任何作用。这一结果或许令人惊讶,因为不同行业的工资和种族都有系统的差异。例如,完整设定中估计的行业系数的取值范围超过40个对数点。此外,对12个行业虚拟变量的向量的系数均等于零的零假设进行检验,结果p值小数点后四位都为0。同样,12个行业虚拟变量对种族、西班牙裔背景虚拟变量以及年龄的多元回归结果显示,种族与行业无关的零假设的p值为0.0062。总而言之:
•即使剔除所有其他变量,各个行业的工资也会有系统的变化;
•控制住西班牙裔背景和年龄变量后,就业行业在种族间有系统差异;
•然而,控制了行业就业后,黑人和白人的工资差距并没有影响。
五、扩展
在这一节中,作者简要地考虑上述分析结果的三个扩展。
A. 工具变量估计量
在Gelbach(2009)一文中,作者使用与Gelbach(2002b)中相同的数据来研究公立学校教育对母亲劳动力供给的影响。在Gelbach(2002b)中,作者用出生虚拟变量的1/4作为5岁的孩子入读公立学校的工具。研究发现,公立学校的入学率与劳动力供应的大幅增加有关,这里劳动力是指最小的孩子为5岁的单身母亲们。在Gelbach(2009)中,作者使用上述条件分解的IV版本来评估其原始结果对控制协变量的敏感性。并发现,对协变量的控制并没有系统地影响公立学校的入学效应,尽管不同的协变量组确实会影响这种影响。这可能是因为协变量组具有近似相等但相反的偏效应(就像第四节中讨论的行业虚拟变量的分解一样)。这是一个有趣的发现。Buckles和Hungerman(2008)发现,当他们在模型中加入家庭背景控制因素时,教育回报率的IV估计值增加了20%-50%,尽管他们没有检验统计显著性。由于作者的渐近方差公式可以应用于IV的情况,所以本文可用于回答协变量是否对IV估计有重要影响,例如在估计教育回报率方面。
B. Oaxaca-Blinder分解
第二个扩展涉及Oaxaca-Blinder分解。假设我们对黑人-白人工资平均差异的分解感兴趣。记D为种族虚拟变量,X为除常数外的所有其他解释变量。DX是交叉项。用以下方
法可以很容易看到Oaxaca-Blinder分解中的已解释和未解释的部分,即数量和价格。
Oaxaca-Blinder分解和作者的分解之间的联系实际上是有用的。首先,作者的方差公式可以用于对Oaxaca-Blinder分解估计进行推断。其次,作者的辅助回归方法可以用来计算详细的以及整体的Oaxaca-Blinder分解。而且对于诸如“行业还是职业能更多得解释OBD中得工资差距”这样的问题,作者的方差公式在应用实践是非常有用得。
C. 使用豪斯曼检验
第三个扩展是在零假设为图片协变量与图片正交的情况下,检验图片的系数的统计显著变化。当然可以直接测试正交性,但这需要为图片中的每个协变量估计一个单独的最小二乘系数向量。但在许多应用中,图片的维数很大,这样计算不方便。可以证明,当图片与图片
中的所有协变量正交时,Hausman(1978)的差异方差的结果仍然成立(尽管他的定理的充分条件不一定成立,正如Hausman所说的那样)。我们可以使用已经发表的结果来检验增加的协变量是否重要:利用已报告的系数估计及其估计的标准误差,可以构造一个检验统计量,在图片和图片正交的假设下,其渐近分布是标准正态的。只需要两个设定中的估计系数和标准误差即可进行这样的测试。
六、总结
将协变量按顺序添加到基础模型中通常无法得到感兴趣的总体参数。本文中作者展示了样本的遗漏变量偏差公式可以用来解决这个问题。与顺序添加协变量不同的是,作者在这里构造的分解是以所有协变量为条件而进行估计的。因此,不会出现序列敏感性问题。此外,使用直观且有意义的辅助回归可以很容易得实现作者的分解。
下面这些短链接文章属于合集,可以收藏起来阅读,不然以后都找不到了。