0. yolov4-deepsort简介
该项目为使用YOLOv4、DeepSort和TensorFlow实现的对象跟踪。YOLOv4使用深度卷积神经网络来执行目标检测。
我们可以让YOLOv4的输出将这些对象检测输入深度排序(使用深度关联度量进行简单的在线和实时跟踪),以创建一个高度精确的对象跟踪器。
基于yolov4-deepsort可以进行一些后续的进阶任务。我在yolo+deepsort基础上进行改进,实现路面拥堵的检查,有三个功能:对ROI区域进行目标的计数;对目标车辆的行为做出预测(waitting / break in);对车辆的行车轨迹进行可视化显示。
这里先简单介绍下项目环境的搭建,使用GPU版本可以使检测速度大幅提升,本人帧率达17左右。
原始yolov4-deepsort的git资源:link.
1. cuda环境
由于要使用GPU版本的tensorflow,所以先进行cuda的安装,安装教程可以参看本人的另外一篇博客:windows下cuda10.0+cudnn的配置。cuda的版本可以根据自己需求定,安装步骤基本一致。
2. 配置项目环境
2.1 所需环境
本次项目的所需环境为:
tensorflow-gpu==2.3.0rc0
opencv-python ==4.1.1.26
lxml
tqdm
absl-py
matplotlib
easydict
pillow
2.2 环境配置
利用anaconda进行配置,当然也可以利用官方教程进行配置。
打开anaconda,创建一个名为yolo-deepsort的环境,python为3.7。
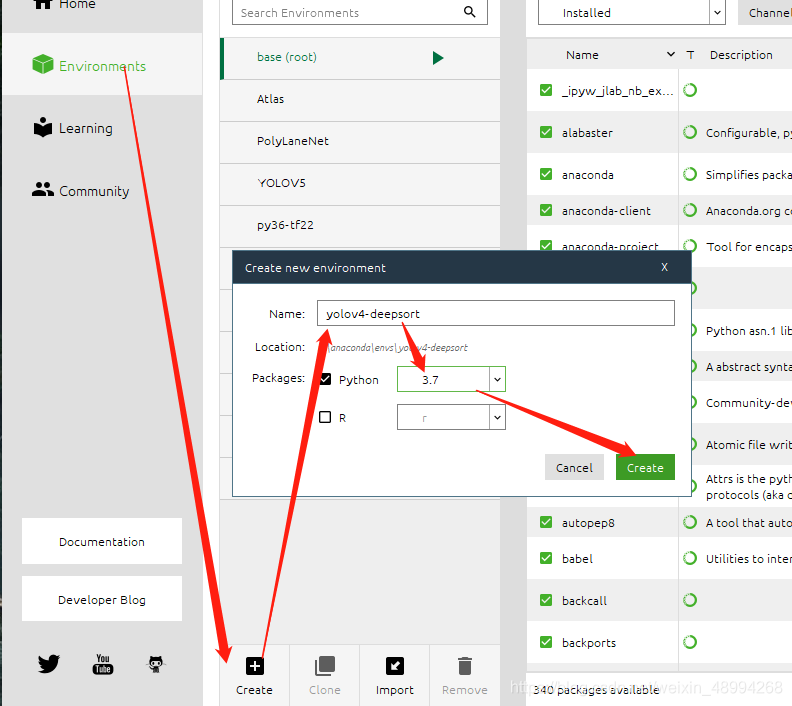
进入该环境的终端,cd到项目目录:
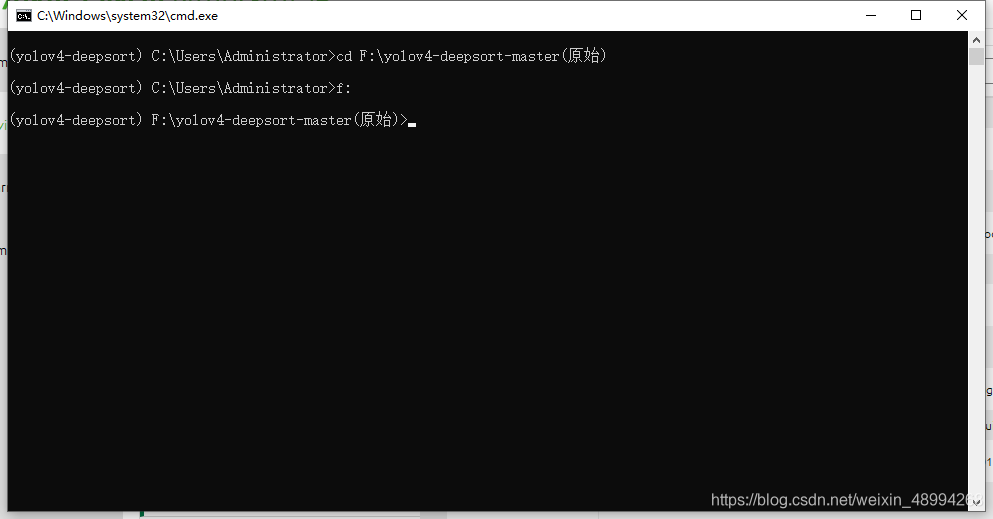
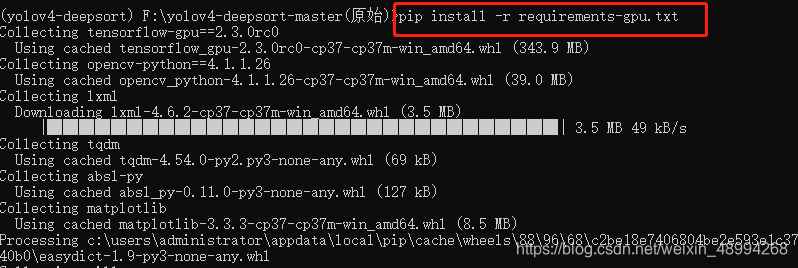
输入命令:`pip install -r requirements-gpu.txt
可以直接将对应txt文件中的所有库包安装,当然也可以手动pip。
这里下载速度慢的可以更改镜像源,网上有很多教程。也可以参看本人博客:解决pytorch安装过程中下载总是出错的问题中的修改镜像源章节。
安装后查看所有安装的包,可以点击anaconda里面的对应环境进行查看,也可以终端接着运行conda list:
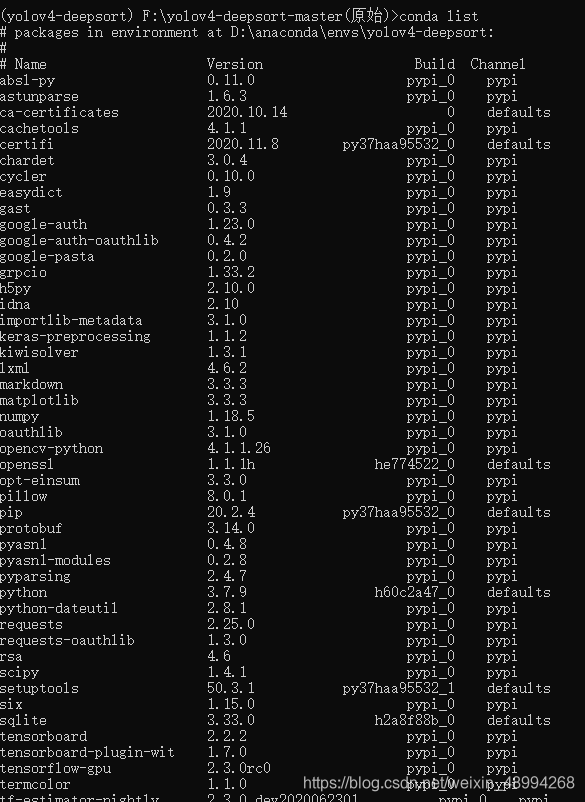
看到所有的依赖库都安装好以后环境就搭好了。本人在第一次搭建时遇到了一些小问题,遇到问题可以自己上网查查,安装不成功的库,可以使用本地安装的方法(网络不稳定的时候可以尝试)。
3. 模型权值的下载
yolov4提供了有80种物体的识别权重模型,这些都是人家训练好的,当然如果没有自己所要识别的物品,制作自己的数据集进行训练。下载链接:link.将下载好后的模型放入data文件夹。
4. 运行程序
接着运行下面的代码。这里输入的视频可以改为自己的视频的路径,输出的视频保存路径也自己改下
# Convert darknet weights to tensorflow model
python save_model.py --model yolov4
# Run yolov4 deep sort object tracker on video
python object_tracker.py --video ./data/video/test.mp4 --output ./outputs/demo.avi --model yolov4
# Run yolov4 deep sort object tracker on webcam (set video flag to 0)
python object_tracker.py --video 0 --output ./outputs/webcam.avi --model yolov4

帧率在16左右,说明GPU环境设置正确,如果只有几帧那么是你的cuda环境没有配置好,重新配置。
本人利用pycharm进行运行程序,一方面可视化效果好,另一方面可以接着他的代码继续修改。打开pycharm,setting自己建好的环境。
x修改对应的路径参数即可。
右击运行。
至此,已经完成了yolov4-deepsort的运行。如果想要使用更高速的训练模型,即刚刚下载的模型,可以接着运行下面的代码,或者更改pycharm中的模型调用的位置。
下面的命令将允许您运行yolov4-tiny模型。Yolov4-tiny允许你获得一个更高的速度(FPS)的跟踪器在精度上有一点成本。确保你已经下载了小权重文件,并将其添加到“data”文件夹中,以便命令能正常工作!
# save yolov4-tiny model
python save_model.py --weights ./data/yolov4-tiny.weights --output ./checkpoints/yolov4-tiny-416 --model yolov4 --tiny
# Run yolov4-tiny object tracker
python object_tracker.py --weights ./checkpoints/yolov4-tiny-416 --model yolov4 --video ./data/video/test.mp4 --output ./outputs/tiny.avi --tiny官方运行结果展示:


5. 本人项目demo展示
下面是本人在原有基础上进行的修改。加入轨迹信息(轨迹还需优化,存在断点),计数判断,roi区域划分:

该demo左下角记录ROI中检测框的个数,只检测车辆,当ROI里面的车辆达到一定的阈值,将对进入的车辆的行为进行判断并附上标签。视频压缩成gif受上传文件大小限制,画质不是很清楚。
场景一:

场景二:
