并发编程(三)Python编程慢的罪魁祸首。全局解释器锁GIL
并发编程(四)如何使用多线程,使用多线程对爬虫程序进行修改及比较
并发编程(七)好用的线程池ThreadPoolExecutor
并发编程(九)使用多进程multiprocessing加速程序运行
并发编程(十二)使用subprocess启动电脑任意程序(听歌、解压缩、自动下载等等)
为什么要使用多进程?
有了多线程threading,为什么还要使用多进程multiprocessing
-
如果遇到CPU密集型计算,多线程反而会降低执行速度!
-
虽然有全局解释器锁GIL,但是因为有IO的存在,多线程依然可以加速运行。
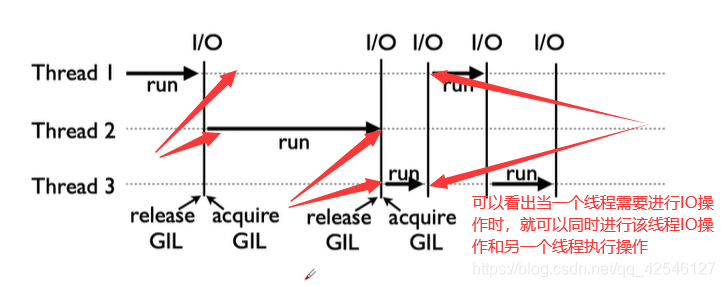
- CPU密集型计算,线程的自动切换反而变成了负担,多线程甚至减慢了运行速度。

- 为了解决上面这个问题。我们就引入了多进程。multiprocessing模块就是python为了解决GIL缺陷引入的一个模块,原理是用多进程在多CPU上并行执行。
多进程multiprocessing使用方法(对比多线程Threading)
# 多线程引入模块
from threading import Thread
# 多进程引入模块
from multiprocessing import Process
# 多线程的新建、启动、等待结束
t = Thread(target=func, args=(x,))
t.start()
t.join()
# 多进程的新建、启动、等待结束
p = Process(target=func, args=(x,))
p.start()
p.join()
# 多线程数据通信
import queue
q = queue.Queue()
q.put(item)
item = q.get()
# 多进程数据通信
from multiprocessing import Queue
q = Queue()
q.put(item)
item = q.get()
# 多线程加锁
from threading import Lock
lock = Lock()
with lock:
# do someting
pass
# 多进程加锁
from multiprocessing import Lock
lock = Lock()
with lock:
# do someting
pass
# 多线程池化技术
from concurrent.futures import ThreadPoolExecutor
with ThreadPoolExecutor() as executor:
# 方法一
rsts = executor.map(func, item)
# 方法二
future = executor.submit(func, x)
rst = future.result
# 多进程池化技术
from concurrent.futures import ProcessPoolExecutor
with ProcessPoolExecutor() as executor:
# 方法一
rsts = executor.map(func, item)
# 方法二
future = executor.submit(func, x)
rst = future.result()
(如果有疑问,可以参考前面几个博客的内容,前面几个博客已经详细介绍了线程的使用。而进程和线程基本一致)
代码实战:单线程、多线程、多进程对比CPU密集计算速度
我们先来看结果,我这儿测试的是连续100次判断一个很大的数字是否是素数。可以看出多线程会比单线程还耗时多。而多进程就大大减少了耗时。

原码及结果:
# -*- coding: utf-8 -*-
# @Time : 2021-03-22 16:00:12
# @Author : wlq
# @FileName: process_test.py
# @Email :[email protected]
import math
import time
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
# 需要判断列表,下面数字判断100次
PRIMES = [112272535095293] * 100
# 判断是否是素数
def is_prime(n):
if n < 2:
return False
if n == 2:
return True
if n % 2 == 0:
return False
sqrt_n = int(math.floor(math.sqrt(n)))
for i in range(3, sqrt_n + 1, 2):
if n % i == 0:
return False
return True
def single_thread():
for x in PRIMES:
is_prime(x)
def multi_thread():
with ThreadPoolExecutor() as pool:
pool.map(is_prime, PRIMES)
def multi_process():
with ProcessPoolExecutor() as pool:
pool.map(is_prime, PRIMES)
if __name__ == '__main__':
start_time = time.time()
single_thread()
end_time = time.time()
print("single_thread cost:", end_time - start_time)
start_time = time.time()
multi_thread()
end_time = time.time()
print("multi_thread cost:", end_time - start_time)
start_time = time.time()
multi_process()
end_time = time.time()
print("multi_process cost:", end_time - start_time)
'''
output:
single_thread cost: 63.33259177207947
multi_thread cost: 63.582000970840454
multi_process cost: 17.35455083847046
'''
通过代码结果,可以看出多进程在处理CPU密集型计算时会节省很多时间。反而,多线程处理CPU密集型计算会增加耗时。