ransformer是一种强大的序列模型,但是它所需的时间和内存会随着序列长度出现二阶增长。而OpenAI研究人员开发出了一种深度神经网络Sparse Transformer,该网络在预测长序列方面创造了新纪录——无论预测的是文本、图像还是声音。该神经网络利用注意力机制中的一种改进算法,可以从长度可能是之前30倍的序列中提取模式。
OpenAI提出的模型可以使用数百个层对数万个元素的序列进行建模,在多个域中实现最先进的性能。稀疏Transformer能够帮助我们构建具有更强的理解世界能力的AI系统。

Sparese Transformer 项目说明文档

一 、项目介绍
Transformer 中 Self-attention的计算时间和显存占用量都是 的(表示序列长度),随着序列长度的增加,计算时间和显存占用也都成二次方增长。因此当序列长度足够大时,计算时间和显存带来的问题也会很大。Sparse Transformer 引入了注意力矩阵的稀疏分解将计算时间和显存占用减小至,同时不会降低性能。
项目所需环境:

项目目录:
二、数据集介绍
三、算法原理
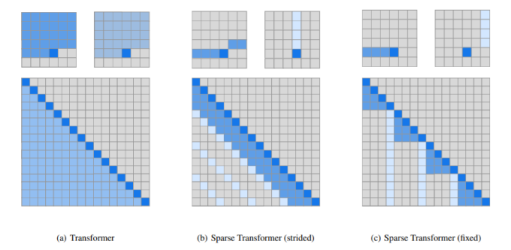
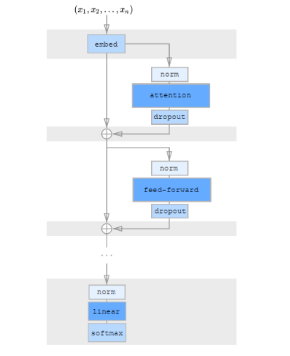
Sparse Transformer 主要介绍了strided attention和fixed attention,并与full attention进行了对比,结构如下:
四 、数据训练测试
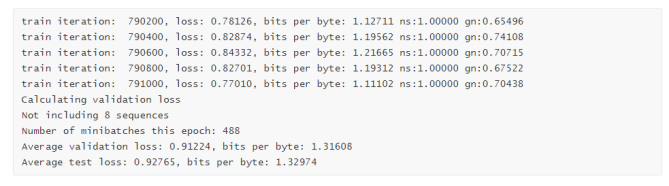
训练结果如下: