前戏
上篇文章一番优化后,依然存在请求响应偶发超时,看来上次调优简直是赠送的惊喜发现。
重新思考
不是查询语句和数据结构引起的慢查询,那为什么会偶发的超时,排查超时时间范围内的日志,并没有大量的突发请求,这让本来不精通ES的我雪上加霜!但是咱能怎么办,只能撸起袖子加油干!(我太难了)
查询资料得到几个API技能
//集群线程池情况
GET /_cat/thread_pool?v
//集群热点线程
GET /_nodes/hot_threads
//集群缓存
GET /_stats/request_cache?human
一番操作猛如虎,原来还是无用功。没有发现什么异常,但是有一个API引起了我的特殊目光
集群JVM
GET /_nodes/stats/jvm
就是她,让我想起了ES底层是Java,他是一个Java程序啊,老铁!
Java程序,在一段时间内无响应,那它很大几率是发生了GC(OMG!有线索了)
看一下集群的堆内存是否设置的不合理
集群堆内存API
GET _cat/nodes?h=heap.max
嗯,设置的很合理。完全遵循官方要求。
kibana上观察一下节点JVM Heap的情况

小朋友,你是否有很多问号❓,很明显了罪魁祸首就是GC了,但为什么GC了这么久,大概2个小时的间隔,堆内存就会上去,继续观察下一个节点
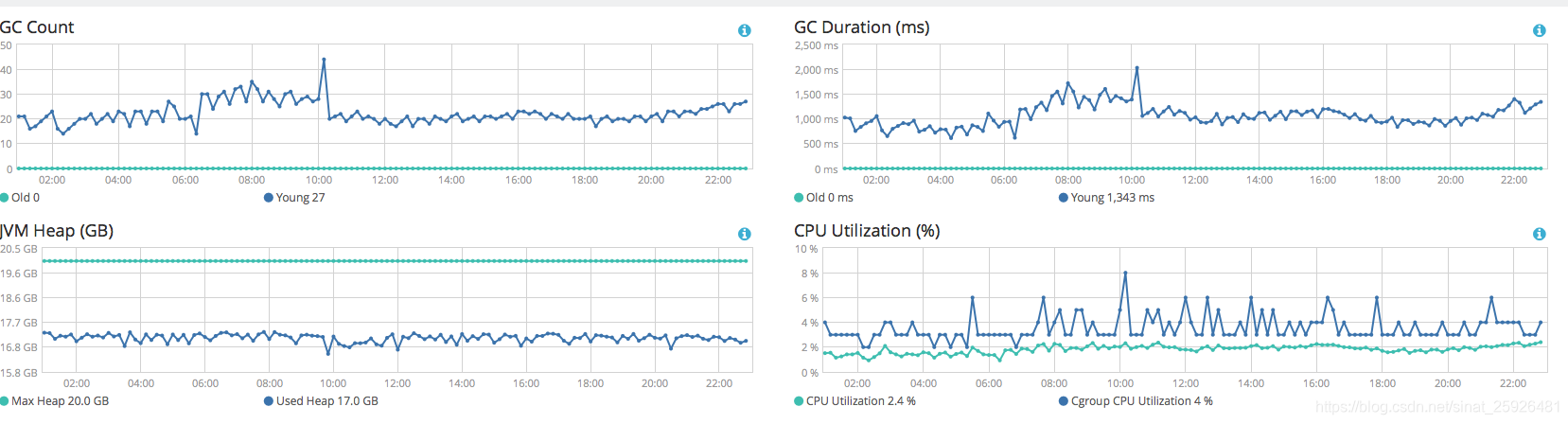
这个节点堆内存倒是很稳定,GC也都是新生代GC影响很小,没有发生old gc。这里就会很疑惑了,查看了所有节点,只有这么一台是很稳定的,另外的多台节点,都如第一个节点一样,堆内存简直是在坐过山车。
如何解决
发现了是GC导致的,那么为什么会这样,还是一无所知,集群也不是咱搭建的,咱也不敢问,咱也不敢说。但是还是要恰饭啊!问了下运维图2的节点是G1GC 其余节点是CMSGC,至于为什么有一台是G1GC 我怀疑是之前就有发现这个问题在调优,但是没有进行下去。
网上搜索了一些答案,在官方论坛也搜刮了好几遍,没有找到想要的答案。大概就是聚合、大批量的深分页、Fielddata等,但是通过Kibana查看一切都是那么的正常。
搜到的各种关于ES GC的问题,得到最多的是,不推荐使用G1gc,因为lucene的缘故,g1gc可能会损坏分片,但是都是在早期的ES上。
怎么办呢?明显G1GC的节点,表现上强于CMSGC节点,只能硬着头皮把节点都陆续改为G1GC观察一下了,另外就是排查一下业务上有没有滥用ES。
待续~~~~~~~~~~
后续
经过两周的观察,没有出现oldGC, YoungGC在100ms内效果非常客观,但是堆内存一直占用60-70%甚至更高,如果资源不够慎用!!!