知识追踪模型——教育大数据挖掘
知识追踪的本质是根据学生的历史学习记录来推测任意时刻学生对于知识点的掌握程度,进而预测学生的未来成绩,也可以辅助教师布置教学计划等。
现有的知识追踪模型大致可以分为3类:

基于概率图模型的知识追踪
BKT
贝叶斯知识追踪(BKT)是最流行的知识追踪模型。在BKT模型中提出了一个关于学生知识状态的隐变量,学生的知识状态由一个二元组表示 {掌握该知识点,没掌握该知识点}。整个模型结构实际上是一个HMM模型,根据状态转移矩阵来预测下一个状态,根据当前的状态来预测学生的答题结果。而且在BKT模型中认为知识一旦掌握就不会被遗忘,最近有研究引入了学生未掌握知识的情况下猜对题目的概率和学生掌握知识的情况下答错题目的概率,学生的先验知识和问题的难度来扩展模型。然而不管有没有这些扩展,BKT模型依然存在问题,隐藏状态和练习做题之间的映射模糊,很难充分预测每个练习的某个概念。
FuzzyCDF
FuzzyCDF模型将模糊理论应用到认知诊断中,可以同时对学生作答客观题和主观题进行诊断,解决了传统认知诊断模型无法有效诊断主观题的问题。
FuzzyCDF模型假设在客观题作答中,学生要掌握题目所涉及的全部知识点才能掌握题目也即学生对题目的掌握程度等于学生对知识点掌握程度的模糊交;在主观题作答中,学生要掌握题目所涉及的全部知识点的其一就可能掌握题目也即学生对题目的掌握程度等于学生对知识点掌握程度的模糊并;但这种假设不够严谨,实际中若学生只掌握测试题所涉及的知识点中的一个,很多时候得不到分数。
基于矩阵分解的知识追踪
KPT
KPT整体流程如下所示。在给定学生练习反馈日志和Q矩阵(由教育专家提供的Q矩阵描绘了练习题目与知识点之间的关系),KPT利用Q矩阵将每个学生的潜在向量映射到知识空间中,而后根据学习和遗忘曲线来解决知识追踪问题。在预测阶段,KPT模型预测学生T+1时间窗口中的练习表现情况RT+1和学生T+1时间窗口的知识点掌握情况UT+1。

基于深度学习的知识追踪
DKT
DKT模型首次将循环神经网络应用于知识追踪任务,利用LSTM模型追踪学生知识熟练度随着时间动态变化的过程。
DKT模型输入为xt = {qt, at},其中qt表示题目编号,at表示反馈结果(1表示正确,0表示错误)。如图所示,xt在进入DKT模型前先经过one-hot编码转化为one-hot向量,再输入到LSTM中。

LSTM结构中每个模块如下公式所示,其中ft用于决定是否丢弃之前记忆单元存放的信息;it用于确定t时刻的更新信息; ~Ct为t时刻获取得到的信息;Ct中存放的信息综合考虑到了长期记忆ft与短期记忆it的影响;最终根据Ct与输出控制门Ot计算LSTM在t时刻的输出ht。

通过使用LSTM, DKT可以综合考虑学生较长时间前通过的题目情况与近期通过的题目情况,用以确定当前时刻学生对于知识的熟练度。其中遗忘门ft的设计符合学生随着时间的流逝,对之前学习的知识的熟练度逐渐降低这一特点。DKT的输出yt表示学生完成各个题目的正确率,其中yt的维度等于题目的数量。
EERNNA
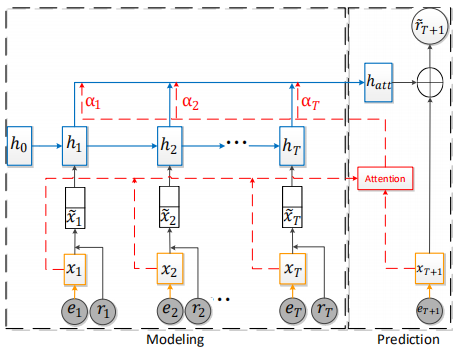
EERNNA通过充分利用学生练习记录和题目文本来预测学生的表现。具体来说,其对于学生练习过程建模,首先设计一个双向LSTM,利用文本来对每个题目进行嵌入。然后,EERNNA设计了一种新的基于注意力机制的LSTM架构,它根据学生练习记录中的类似题目来追踪学生的知识熟练度。通过这种方式,EERNNA可以根据学生的练习记录自然地预测每个学生在未来练习中的表现。
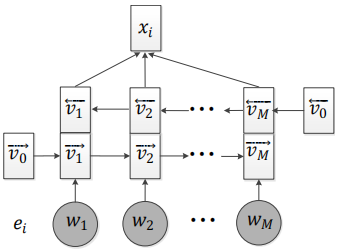
如下图为题目嵌入的过程,每道题目表示为e=w1w2…wM。将每个单词w经过词嵌入后输入到双向LSTM中获得vi= concatenate(vi->,vi<-),最终题目嵌入结果为xi。
练习嵌入xt被扩展为~xt,其中⊕是连接两个向量的操作。
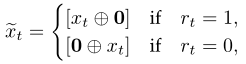
基于当前输入的~xt和递归公式中的前一状态ht-1来更新她的练习步骤t的隐藏学生状态 ht,其递归公式如下:
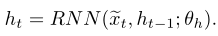
学生可能会在类似的练习中得到相似的分数,例如,学生S1正确地回答了练习e1和e3,这可能是因为这两个练习因为相同的知识概念“函数”。EERNNA假设第(T+1)步的学生状态是基于练习eT+1和历史学生状态之间的相关性的。在下一步骤T+1,我们将学生的注意力状态向量hatt定义为:
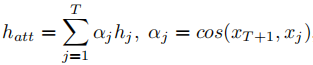
(1)假设该学生应用状态hatt来解决该练习;
(2)利用练习嵌入从练习文本et+1中提取语义表示xt+1;
(3)按照以下公式预测她在练习et+1上的表现;
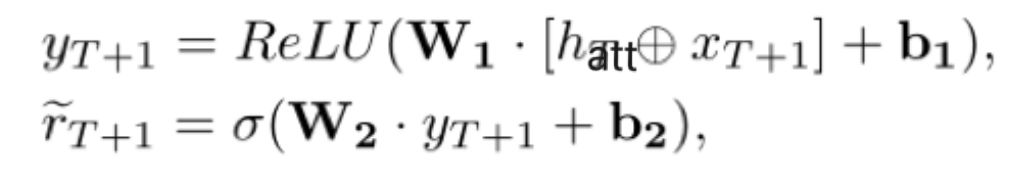
EKTA

上文中所提到的EERNN模型可以预测学生的表现,但是不可以对学生的每一个知识点的掌握程度进行追踪,这存在一定的局限性,因此提出了一种新的方法,即可以准确的预测学生的表现情况,还可以追踪学生对于每一个知识点的掌握情况。不同于EERNN用向量描述学生的知识掌握情况,EKTA使用的是一个矩阵去描述学生对于各个知识点的掌握情况,其中矩阵的每一列表示的是学生对于单一的知识点的掌握程度。EKTA假设学生的知识状态和之前所有状态均相关。
我们将每一个知识点都存放在矩阵M中,其中矩阵的每一列是表示一个知识点的向量。首先我们将习题的知识点维度v与M中的每一列做内积,之后将结果送入到softmax函数中,得到该习题与各个知识点之间的相关程度β:
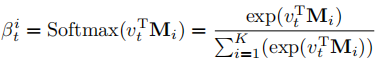
在这里,用联合输入~xti替换原始的输入xti,该~xti在公式中计算为:
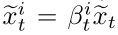
在练习步骤t,在学生回答练习et之后,我们还通过LSTM网络更新学生的知识状态Hti。

EKTA模型认为,学生当前的知识水平,不仅仅与当前的认知水平有关,还和学生之前的知识水平相关,我们加入Attention机制,计算题目xT+1和之前题目的相似度,之后将每一个时刻的知识水平H与其对应的权重相乘求和,得到当前的矩阵Hatt。再计算习题的知识概念权重,最后得到当前学生对于题目理解的向量ST+1,再将理解程度向量与习题向量拼在一起,经过全连接层,得到最终的预测结果。
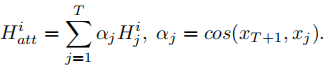
将学生当前的知识水平Hatt的每一列与对应的权重相乘,得到学生当前对于题目知识的理解 sT+1
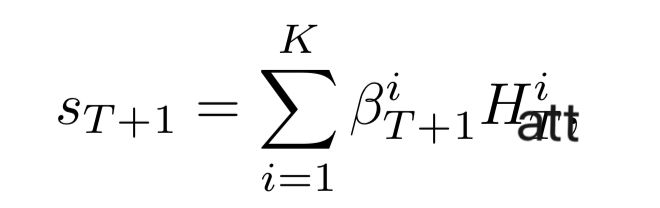
再结合题目自身的文本因素,去预测学生作对题目的概率。
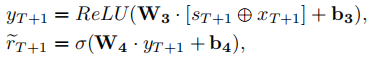
在第t步,通过EKTA框架设~rt为练习et的预测分数,rt为实际的二进制分数,从而定义某一学生的总损失为:
研究展望
学生的真实学习环境极为复杂,学生学习效果受到多方面因素影响。因此在知识追踪的过程中,应该考虑诸如题目的文本信息、题目中包含的图片信息以及MOOC平台中学生与平台之间多种类型的交互信息等异构数据。为此,应该引入自然语言处理、图像识别等领域中的模型,以处理异构数据,将异构数据嵌入到高维空间中,以方便之后综合多种因素进行学生知识追踪。除此之外,在建模过程中还应该考虑将更多的传统教育学中的经典理论,如记忆曲线、遗忘曲线、LSI模型中的学习风格等考虑在内,以加强模型构建的合理性,进一步提升知识追踪的性能。