NoSQL,泛指非关系型的数据库。随着互联网web2.0网站的兴起,传统的关系数据库在处理web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,出现了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,特别是大数据应用难题。
中文名 非关系型数据库 外文名 NoSQL=Not Only SQL 全 称 Not Only SQL 类 别 非关系型的数据库 应用领域计算机、软件、数据库 分 类 键值存储、列存储、文档存储等
MongoDB和HBase天生都支持分布式存储,即将一份大的数据分散到不同的机器上进行存储,从而降低了单个节点的存取压力,这就使得大数据存储和处理都得到了比较好的解决。
大数据的存储方式有哪些?其实总结下来就是传统的关系型数据库和现如今主流的非关系型数据库,而从大数据处理的角度,非关系型数据库无疑是最佳的选择。总之,每种数据库各有各的优势和劣势,具体怎么选要视实际情况而定。
我喜欢叫她“反向索引”(索引那么萌的东西,当然要用“她”啦!_ )常规的索引是文档到关键词的映射: 文档——>关键词但是这样检索关键词的时候很费力,要一个文档一个文档的遍历一遍。(这事不能忍)于是人们发明了倒排索引倒排索引是关键词到文档的映射 关键词——>文档这样,只要有关键词,立马就能找到她在那个文档里出现过,剩下的事就是把她揪出来了~~~可能是因为将正常的索引倒过来了吧,所以大家叫他倒排索引,可我依然喜欢叫他反向索引~
1)创建文档列表:

2)创建倒排索引列表
l 然后对文档中数据进行分词,得到词条。对词条进行编号,以词条创建索引。然后记录下包含该词条的所有文档编号(及其它信息)。

倒排索引创建索引的流程:1) 首先把所有的原始数据进行编号,形成文档列表2) 把文档数据进行分词,得到很多的词条,以词条为索引。保存包含这些词条的文档的编号信息。
搜索的过程:当用户输入任意的词条时,首先对用户输入的数据进行分词,得到用户要搜索的所有词条,然后拿着这些词条去倒排索引列表中进行匹配。找到这些词条就能找到包含这些词条的所有文档的编号。然后根据这些编号去文档列表中找到文档
个人认为翻译成转置索引可能比较合适。
一个未经处理的数据库中,一般是以文档ID作为索引,以文档内容作为记录。
而Inverted index 指的是将单词或记录作为索引,将文档ID作为记录,这样便可以方便地通过单词或记录查找到其所在的文档。

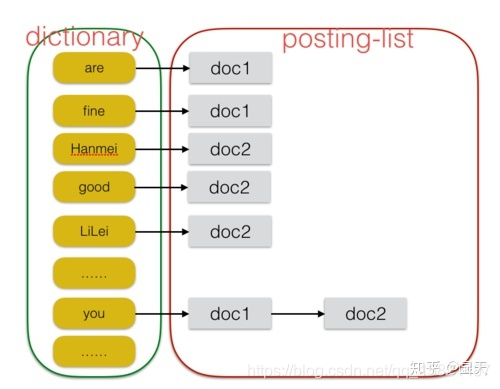
我们肯定都会这样的经历:偶然看到一段很好的文字,但是却不知道出处,这时候去图书馆,一个一个翻找,无疑是大海捞针,这个时候肿么办呢,于是便有了全文检索这项技术,而它最核心的就是倒排索引。假如有如下文档:
我们把前面的部分叫做dictionary(字典),里面的每个单词叫做term,后面的文档列表叫做psoting-list,list中记录了所有含有该term的文档id,两个组合起来就是一个完成的倒排索引(Inverted Index)。能够看出,假如需要查找含有“you”的文档时,根据dictionary然后找到对应的posting-list即可。
而全文检索中,创建Inverted Index是最关键也是最耗时的过程,而且真正的Inverted Index结构也远比图中展示的复杂,不仅需要对文档进行分词(ES里中文可以自定义分词器),还要计算TF-IDF,方便评分排序(当查找you时,评分决定哪个doc显示在前面,也就是所谓的搜索排名),压缩等操作。每接收一个document,ES就会将其信息更新在倒排索引中。
从这里我们就可以看出ES和MySQL、HBase的存储还是有很大的区别。而且ES不仅包含倒排索引,默认同时还会把文档doc存储起来,所以当我们使用ES时,也能拿到完整的文档信息,所以某种程度上,感觉就像在使用数据库一样,但是也可以配置不存储文档信息,这时只能根据查询条件得到文档id,并不能拿到完整的文档内容。
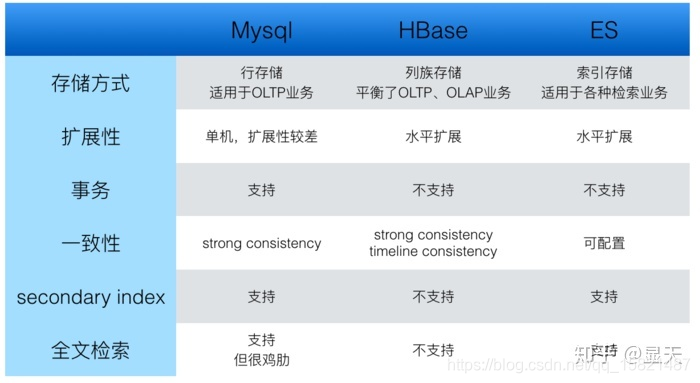
总结:MySQL行存储的方式比较适合OLTP业务。列存储的方式比较适合OLAP业务,而HBase采用了列族的方式平衡了OLTP和OLAP,支持水平扩展,如果数据量比较大、对性能要求没有那么高、并且对事务没有要求的话,HBase也是个不错的考虑。ES默认对所有字段都建了索引,所以比较适合复杂的检索或全文检索。
OLTP主要是对数据的增删改,OLAP是对数据的查询。

OLTP主要用来记录某类业务事件的发生,如购买行为,当行为产生后,系统会记录是谁在何时何地做了何事,这样的一行(或多行)数据会以增删改的方式在数据库中进行数据的更新处理操作,要求实时性高、稳定性强、确保数据及时更新成功,像公司常见的业务系统如ERP,CRM,OA等系统都属于OLTP。当数据积累到一定的程度,我们需要对过去发生的事情做一个总结分析时,就需要把过去一段时间内产生的数据拿出来进行统计分析,从中获取我们想要的信息,为公司做决策提供支持,这时候就是在做OLAP了。
所以OLAP和OLTP之间的关系可以认为OLAP是依赖于OLTP的,因为OLAP分析的数据都是由OLTP所产生的,也可以看作OLAP是OLTP的一种延展,一个让OLTP产生的数据发现价值的过程。
这里我们在多介绍一下OLAP
总结:MySQL行存储的方式比较适合OLTP业务。列存储的方式比较适合OLAP业务,而HBase采用了列族的方式平衡了OLTP和OLAP,支持水平扩展,如果数据量比较大、对性能要求没有那么高、并且对事务没有要求的话,HBase也是个不错的考虑。ES默认对所有字段都建了索引,所以比较适合复杂的检索或全文检索。