摘要
我们提供了DeepWiFi协议,该协议可通过深度学习强化基准WiFi(IEEE 802.11ac),并通过减轻网络外干扰来维持高吞吐量。 DeepWiFi可与基准WiFi互操作,并以现有WiFi的PHY收发器链为基础,而无需更改MAC帧格式。用户运行DeepWiFi用于i)RF前端处理; ii)频谱感测和信号分类; iii)信号认证; iv)频道选择和访问; v)功率控制; vi)调制和编码方案(MCS)适应;和vii)路由。 DeepWiFi减轻了概率性,基于感知的自适应干扰器的影响。 RF前端处理应用基于深度学习的自动编码器来提取频谱表示特征。然后,训练深度神经网络将波形可靠地分类为空闲,WiFi或干扰。利用信道标签,用户可以有效地访问空闲或阻塞的信道,同时避免干扰合法的WiFi传输(通过基于机器学习的RF指纹验证),从而提高了吞吐量。用户优化其发射功率以降低拦截/检测的可能性,并优化其MCS,以最大化反压算法用于路由的链路速率。与基准WiFi和另一种抗干扰协议相比,DeepWiFi受嵌入式平台实施的支持,可显着提高吞吐量,尤其是在信道可能被干扰且信号与干扰加噪声比低的情况下。
1 简介
认知无线电为无线通信系统提供了感知,学习和适应频谱动态的能力。 诸如WiFi之类的现有通信系统可以极大地受益于认知无线电的设计概念,该概念涵盖了各种检测,分类和预测任务。 这些认知无线电任务可以通过适应光谱数据的机器学习来潜在地执行,而无需明确编程[1] – [4]。 特别是,深度神经网络具有强大的潜力来处理和分析丰富的光谱数据。 认知无线电任务的深度学习应用示例包括卷积神经网络(CNN)的调制分类[5],使用CNN [6]和生成对抗网络(GAN)进行频谱感测[7],以及使用前馈神经网络(FNN)[8],[9]进行抗干扰和功率控制。
在本文中,我们提出了DeepWiFi协议,旨在通过机器学习(特别是深度学习)的应用来强化基准IEEE 802.11ac WiFi,以提高吞吐量性能并在存在干扰造成干扰的情况下增强其安全性-网络干扰。
我们考虑三种类型的干扰器,它们被建模为概率干扰,基于感应的干扰或自适应干扰。
DeepWiFi利用了新兴的计算功能所支持的机器学习算法的先进性。 DeepWiFi的范围是说明如何在多跳移动自组织网络(MANET)中使用这些算法来增强性能和安全性。 DeepWiFi的潜在应用领域包括物联网(IoT),传感器和第一响应者通信。 DeepWiFi的一个关键方面是支持与基准WiFi的互操作性,同时避免对基准WiFi操作产生任何不利影响。为此,DeepWiFi使用基线WiFi的PHY收发器链,并且不会更改其媒体访问控制(MAC)帧格式。 DeepWiFi协议栈涉及以分布式方式运行的物理(PHY),链路/ MAC和网络层算法。与依靠访问点连接各个节点的IEEE 802.11ac的标准用法相比,DeepWiFi支持多跳路由。作为扩展,WiFi Direct可用于支持多跳通信[10],而IEEE 802.11s修正案是专门为包含多跳通信的网状网络而设计的。尽管本文介绍了使用WiFi设置的发现,但DeepWiFi的算法也可以扩展到其他频带和波形。
1.1 Summary of Contributions
DeepWiFi包含七个步骤:1)RF前端处理; 2)频谱感测和信号分类; 3)信号认证; 4)频道选择和访问; 5)功率控制,以实现低拦截概率和低检测概率(LPI / LPD); 6)调制和编码方案(MCS)适配;和7)路由。本文的主要贡献是步骤1-4中的算法,即RF前端处理;频谱感测和信号分类;信号认证;以及频道选择和访问。关于功率控制,自适应调制和编码以及路由的步骤5-7在其他类似协议中使用,并且包括提供其余功能(保留协议栈的分层体系结构),实现和评估完整的协议栈,并对其进行比较其他协议的性能。在执行这些步骤时,DeepWiFi将控制发射功率,MCS ID,已认证信号,通道ID,邻居ID和流量ID的选择,并将选择提供给IEEE 802.11ac收发器链。 DeepWiFi协议中的机器学习知识。
1)RF前端处理:每个用户将自动编码应用于在感测通道上收集的数据的同相和正交(I / Q)分量,并提取频谱特征。 可以通过使用其他接收器来收集I / Q数据,也可以通过在现有WiFi芯片上使用固件分派来提取I / Q数据,如[11]中所述。 我们证明,与其他方法(例如主成分分析(PCA)和t分布随机邻居嵌入(t-SNE))相比,自动编码在降维方面实现了较低的重建损失(0.2%)。 RF前端处理的输出输入到信号分类模块。
2)频谱感测和信号分类:每个用户对通过RF前端处理获得的功能应用深度学习(FNN或CNN),以便将每个信道分类为空闲(I),阻塞(J)或被另一个WiFi设备使用( W)。 我们显示FNN和CNN都达到了98%以上的精度,而支持向量机(SVM)的精度被限制为66%。
3)信号认证:每个用户都应用基于机器学习的RF指纹来认证信号。 无线电硬件对RF信号的影响用作检测异常值的功能。 我们表明,最小协方差决定因素(MCD)的检测精度接近90%,而SVM和隔离林只能分别达到69%和70%左右的精度。 DeepWiFi的信号认证功能可保护WiFi免受重放攻击。
4)频道访问:与基准WiFi(在此情况下,用户不管干扰的类型而后退)相反,DeepWiFi中的每个用户都进行信号分类,当干扰来自参与DeepWiFi协议的另一个用户时,则退避。 当干扰来自干扰时,请退后。 这样,DeepWiFi用户可以继续进行通信(以降级模式),并通过调整功率,调制和编码方案来实现非零吞吐量(而不是退避)。
在本文中,在存在概率干扰和基于感知的干扰器的情况下,模拟了运行DeepWiFi的分布式用户网络。
MATLAB WLAN Toolbox用于生成逼真的WiFi信号和通道。
仿真结果表明,随着干扰效果(故意的对抗性干扰或网络外干扰的形式)增加,基准WiFi的吞吐量会迅速降至零,而DeepWiFi能够可靠地识别出要传输的通道并维持其吞吐量。 对于在40个通道上运行的9个用户,我们显示,当堵塞可能性小于60%时,DeepWiFi没有吞吐量损失,而当堵塞可能性为80%时,只有14%吞吐量损失。 最后,我们证明DeepWiFi优于抗干扰MAC协议,即Jamming Defense(JADE)[12]并且对自适应干扰器具有鲁棒性。
1.2 Related Work
[8],[9]研究了机器学习的干扰和抗干扰机制,其中敌方用户建立了一个基于深度学习的分类器,利用探索(推断)攻击来干扰数据传输,以预测传输是否成功(应答ACK消息)或不成功(无ACK)。作为回报,发送器可以对干扰器的分类器发起因果攻击(通过向传输决定添加受控扰动)作为防御机制。与[8]、[9]类似,DeepWific考虑具有干扰能力的用户。不同之处在于,deepwifi能够识别被干扰的信道,并(通过调整MCS)支持传输,即使是在干扰情况下,而不是在备份情况下关闭(在基线WiFi中就是这种情况)。关于调制识别的研究也有丰富的文献,可以区分不同调制方式的信号。这些相关研究包括[13]、[14]中使用从原始信号中提取的循环光谱特征的早期工作,以及在使用CNN将原始I/Q样本用作输入的[5]、[15]中最近的工作。Sincea帧可以由多个调制(在前置码和数据部分)组成,并且调制可能在短MAC帧(IEEE 802.11ac[16]中的5.484毫秒)之间发生变化,DeepWiFi中的问题与[5]不同,[15] 重点对帧时间内的波形进行分类,并对在较长周期内保持不变的简单调制进行分类。注意,DeepWiFi前端处理、信号分类和信号认证的总体处理开销测量为0.1546sec(802.11acframe的2.8%),以处理每个样本。此外,我们注意到,常规的频谱传感能量检测器不能应用于我们的框架中,因为它们无法区分总线干扰信号,这样敌人就可以轻易地产生具有相同能量特性的未接通信号,从而愚弄能量检测器。
有几个特点,可用于射频指印。人们可以关注传输信号的瞬态[17]或稳态[18]、[19]行为。例如,[17]研究了发射机独特的瞬态特性,这些特性通常归因于射频放大器、频率合成器模块和调制器子系统。瞬态行为的持续时间取决于系统的类型和型号传送器。还有,随着设备老化,其瞬态行为会发生变化[17]。**在WiFi中,我们选择不使用瞬态行为作为特征,因为它非常容易受到噪声和干扰影响,并且需要精确的信号传输开始时间。**相反,DeepWiFi使用发送器和接收器对之间的稳态特性,例如频率和定时同步偏移,这两者通常都归因于无线电的振荡器、功率放大器和数模转换器。有两个相关的研究,使用稳态特性类似于本文。首先,在[18]中,使用了三种瞬时信号特征,如信号的幅度、相位和频率。在预处理步骤(去除均值和归一化)之后,在预定义的窗口大小内提取它们的特征(如方差、偏度和峰度)[18]。第二,在文献[19]中使用频率偏移、幅度和相位偏移、距离向量和i/Q原点偏移作为射频指纹识别的特征,并开发了加权投票分类器和最大似然分类器。在DeepWiFi中,我们使用machinelearning进行信号验证。
WiFi上的adhoc网络有两个标准,即802.11中的adhoc模式及其后续WiFi Direct。adhoc模式(IBSS)是802.11标准中的两种操作模式之一,另一种模式是基于基础设施模式(IM-BSS)的常用模式。IBSS模式支持任何设备之间的直接通信,而无需接入点(AP)。这一标准已经演变为WiFi Direct,被认为是WiFi上特别是使用android智能手机的ad hoc网络的主要标准[20]。谷歌开发了一个点对点(P2P)框架WiFi P2P,符合WiFi标准。Android 4.0(API级别14)之后的设备可以发现其他设备,并通过WiFi直接相互连接,而无需中间AP,这两个设备都支持WiFi P2P[21]。API包括对对等发现、请求和连接的调用,所有这些调用都在WifiP2PManager类中定义(有关详细信息,请参见[21])。在ad-hocmode中使用WiFi direct并实现多跳路由的相关工作是[10],它以较低的开销改进了多组链路连接。请注意,标准中定义的WiFiDirect不支持多跳通信,但最近的工作(如[10])表明,可以使用WiFiDirect实现多跳路由。DeepWiFi的四个新贡献集中在PHY和mac层(如第2节所述),DeepWiFi被设计为支持单跳和多跳通信。DeepWiFi中的路由方法与[10]不同,因此基于背压算法的路由同时使用队列和信道信息。
DeepWiFi中的RF预处理步骤使用自动编码器[22],[23]。在文献中,有一些研究使用自动编码器在高维空间中提取特征,并提供数据的特征表示,然后使用这些特征训练一个单独的分类器(例如,[24])。在本文中,我们也使用同样的半监督方法。其他预处理方法,如短时傅里叶变换、Choi-Williams变换和Gabor小波变换,在通过CNN运行I/Q数据之前,已在[25]中使用。在本文中,我们的预处理步骤是数据驱动的,由一个去噪自动编码器组成,该编码器可以抑制输入到深度学习分类器中的噪声,并导致轻微的重建损失。
论文的其余部分组织如下。第2节描述了系统模型。第3节给出了DeepWiFi协议概述。第4.1节描述了Deepwifi的射频前端处理。随后,描述了第4.2节的频谱传感和信号分类。第4.3节中应用射频指纹技术,以验证DeepWiFi中的身份信号。第4.4节介绍了DeepWiFi的信道选择和通道访问。随后分别在第4.5节和第4.6节中说明了对DeepWiFi的LPI/LPD和MCS自适应的功率控制。第4.7节介绍了DeepWiFi的路由扩展。第5节描述了模拟设置。第6节介绍了DeepWiFi和基线WiFi的性能结果。讨论了DeepWiFi的实现、开销和复杂性方面的安全性7。第八节总结全文。
2 系统模型
2.1 网络设置
考虑了一种n个的用户无线多跳网络。每个用户可以充当packet traffic的源、目的地或中继。每个源i生成用于通信流Sij的单播数据包,用rate rij发送到destination j。虽然deepwifi 算法不需要同步,但我们在离散时间模拟中考虑了slotted time,并遵循802.11ac MAC的同步,该同步在帧的前导码中使用同步定时器(非HT训练字段[16])。对于每个packetflows,每个用户都有一个单独的队列(在时间slott时长度为qsi(t))。每个队列中的数据包都以先到先服务(FCFS)的方式提供服务。数据包在传输之前分配给802.11ac macframe。如果队列长度小于帧长度,则对缺少的数据部分使用零填充。如果队列长度大于帧长度,则在传输之前,队列中的数据包被划分为多个帧。
有多个频道可用。在任何给定的时隙,用户可以选择这些信道中的一个来传输分组。用户共享这些通道进行数据传输和控制信息交换。没有集中控制器。用户在分布式环境中做出自己的决定。没有任何干扰机的目的是干扰传输。在不丧失通用性的情况下,每个干扰机被分配到其中一个信道(即nJ=m)。
干扰机有三种类型:
概率(随机)干扰机:在任何给定的时隙,以固定的干扰概率开启干扰机。
基于静态感知的干扰机:如果使用恒定的感知阈值τ在信道上检测到信号,则开启干扰机,否则开启干扰机的概率为任何给定时隙的干扰概率。
自适应干扰器:该干扰器是一种基于传感的干扰机信道感知阈值自适应调整。如果干扰机检测到通道上的信号,则该信号已打开。
静态干扰机和自适应干扰机都使用信道感知测量做出干扰决策。对于基于静态感知的干扰机来说,感知阈值是恒定的,而自适应干扰机则通过观察发射机在给定时间窗口内的动作来改变阈值。
物理层实现和MAC帧格式遵循ieee802.11ac标准。中心频率为5.25千兆赫瞬时带宽为20mhz,每个OFDM子载波占用312.5khz的带宽。子载波可以独立使用,并且传入的数据位可以分布在子载波之间(可能取决于信道频率响应)。因此,20 MHz信道由64个子载波组成。我们为导频分配8个子载波,为空分配16个子载波,为数据分配40个子载波(即m=40)。
每个用户根据接收到的数据选择其MCSSINR从userito到userjat的链路速率由cij(t)表示,并且取决于所选择的MCS、发射功率以及由此观察到的SINR。在每个信道上,auser的SINR取决于用户(合法发射机和干扰机)之间的信道和干扰效果。接下来,我们将描述用户之间的信道及其信号是如何生成的。
2.2 通道和波形数据生成
利用MATLAB无线局域网系统工具箱中的802.11a库生成物理信号和信道。提供了几种信道模型。
每个信道模型考虑不同的断点距离、均方根时延扩展、最大时延、非视距条件下的Rician K因子、抽头数和簇数。
使用MATLAB WLAN的WLANWaveFormGenerator功能,指定波形相关参数以生成信号,如输入数据位、数据包数、数据包格式(VHT、HT等)、空闲时间(每个数据包后添加)、扰码器初始化、发射天线数、有效负载长度、MCS和带宽系统工具箱。他的功能是产生一个经过通道的时域I/Q波MX,在通道中应用小范围衰落和其他信道损伤。
用于此操作的MATLAB函数是WLANTGACCHANNEL,它执行ANHX操作,其中它是通道矩阵。在信道生成过程中,有几个参数可以设置,例如延迟曲线(表1中所示的A-Fare模型)、采样率、载波频率、,传输方向(上行链路或下行链路)、接收和发送天线的数量、天线之间的间距以及大规模衰落效应(“无”、“路径丢失”、“阴影”或“路径丢失和阴影”)。
接下来,使用MATLAB无线局域网系统工具箱。因此,我们得到了在I/Q波MX上产生的信道效应HX+N。

3 深度wifi协议概述
在802.11ac之上,每个用户分别异步运行DeepWiFi协议栈,主要步骤如下(如图1所示):
1)射频前端处理:每个用户在WiFi通道之间跳跃(一个接一个),收集每个感测通道上的射频信号,并在射频前端处理射频信号,以建立I/Q数据并提取特征。
2)频谱感测和信号分类:每个用户对这些特征(射频前端的输出)进行深入学习,以便将每个通道分为空闲(I)、干扰(J)或已使用通过另一个WiFi设备(W)。
3)信号认证:每个用户应用基于机器学习的RF指纹在物理层对合法WiFi信号进行认证。
4)通道选择和通道访问:每个用户在合法WiFi信号(W)使用的任何繁忙通道上后退(以解决将来的冲突),选择一个空闲信道(I);如果无,则选择干扰信道(J)(包括非合法WiFi信号使用的信道),该信道具有最佳SINR以进行数据传输。干扰信道的使用(当noidle信道可用时)对应于降级模式,
5)LPI/LPD的功率控制:每个用户选择低于干扰机阈值水平的发射功率,以避免干扰机检测并实现LPI/LPD。
6)自适应调制和编码:在802.11ac中有九种可能的EMCS选项可供选择。每个用户选择最佳的MCS根据测得的信噪比,使所选信道上的可实现速率最大化。
7)路由:每个用户通过应用背压算法选择要服务的流和要传输的下一跳来进行路由决策,它根据流量拥塞和链路速率(在步骤6中计算)优化频谱效用。较低层次的DeepWiFi对路由算法是透明的,并且可以与多跳网络的其他工作相结合,例如扩展WiFi Direct用于多组网络[26]
DeepWiFi协议的输出指定为:a.TX powerspecifies The transmit power。数字1: 包含七个步骤的DeepWiFi协议图。
b.MCS id指定使用IEEE 802.11ac的哪个MCS及其相应的速率。
c.Authenticated signal指定哪些信号属于合法的WiFi。
d.Channel id指定要发送的信道next datapacket.e.Neighbor id指定为下一次传输选择哪个邻居。
f.Flow id指定在传输数据包时为哪个应用程序通信流提供服务传送。这些在每个用户处输出802.11ac网络协议栈的调谐参数。具体来说,outputsa ctune the physicallayer,outputsdandetune the link/MAC layer,outputsfandgtune the network layer,如图所示。

4 DEEPWIFI PROTOCOL STEPS
4.1 第一步:射频前端处理
输入:RF信号
输出:给定给步骤2的提取特征集和给步骤3的I/Q data。
如图2所示,射频信号处理采用以下步骤:
1)16位模数转换器(ADC)通过为信号的实部和虚部分配8位来采样信号。
2)数字化信号在同时带宽内用20MHz带通滤波,消除相邻频带的干扰。
3)数字化信号基于深度学习的自动编码器采用输入采样,并将其分解为潜在特征。

RF前端处理将I / Q数据提供给步骤3(信号验证),并将简化的功能集提供给步骤2(频谱感应和信号分类)。 该过程的详细信息(如图1所示)如下:
1)频谱感测和信号分类(步骤2)**在步骤1中获取自动编码器的输出,并将输入信号分类为WiFi(W),Jammer(J), 或闲置(I)。2) 逻辑将信号分类结果作为输入。**如果信号是WiFi信号,它会将I/Q数据传递给物理层身份验证(RF指纹)模块,这是物理层安全的第一步
**我们没有直接使用I/Q数据作为信号分类器的输入,而是使用去噪自动编码器来提取接收信号的特征,然后将这些特征输入信号分类器。**在一个射频环境中,我们通常有许多未标记的数据样本(可以通过感知光谱来收集),而标记的数据样本(训练分类器所需的)数量与每个数据样本的维数相比是相对较小的(在我们的例子中,40K是每个样本的维数)。然而,未标记的数据可以用来训练一个自动编码器,减少输入数据的维数,从而从少量标记的数据样本中建立一个可靠的分类器。
**此外,我们使用了一个去噪自动编码器,进一步抑制了输入中的噪声。**当环境改变时(例如,新的信道条件(分布)或通过已知或未知信道分布的未知信号发送),可以观察到自动编码器的另一个优点。在新环境下用未标记数据训练的自动编码器可以通过鲁棒特征提取来适应新环境的影响。那么,在新的环境中,少量的标记数据样本就足够了。如果我们直接使用I/Q数据作为基于深度神经网络的分类器的输入,这些功能将无法实现,因为我们无法使用少量的标记训练样本来训练高维问题的可靠分类器。
为了对数据进行预处理,我们还尝试了不同的标准技术,如主成分分析(PCA)[27]和t分布随机邻域嵌入(tSNE)[28]。然而,他们未能分离出感兴趣的信号。这些结果见附录。相反,DeepWiFi使用自动编码器从I/Q数据中提取特征。
自动编码器是一个深层神经网络,它被训练来重建它的输入,由两个神经网络组成,即编码器h=fθ(x)和一个产生重建r=gΦ(h)的编码器,其中θ是与编码器相对应的神经网络的权值和偏差集,Φ代表解码器的权值和偏差集。神经网络可以构造为FNN或CNN。自动编码器用于有效编码的无监督学习DeepWiFi使用自动编码器学习一组数据的表示(编码),以实现特征学习和降维。特别是,DeepWiFi使用去噪自动编码器,将噪声添加到其输入中,并训练其恢复原始噪声、输入。此方法防止自动编码器将其输入复制到输出,自动编码器在数据中查找模式,同时避免过度拟合。
DeepWiFi(ADC、带通滤波和采样)的预处理可生成尺寸为40000(I为20000,Q组件为20000)的I/Q数据,每次instant inStep 1。DeepWiFi将去噪自动编码器应用于该I/Q数据,并确定进一步馈送至DeepWiFi信号分类器的潜在特征。
DeepWiFi的去噪自动编码器将高斯噪声添加到I/Q数据中(以防止过度拟合),然后在一次初始归一化后应用四个隐藏层(前两层用于编码,后两层用于解码)图层。隐藏层通过反向传播算法进行训练以最小化最小平方误差(MSE)作为损失函数。我们使用双曲正切函数(tanh)作为执行msf(x)=tanh(x)运算的激活函数。在神经网络中,激活函数被用来表示动作电位在神经网络中的触发速率牢房。我们进行了超参数优化,观察到均值和方差为0.1的无高斯噪声给出了最佳重建损失,避免了过度拟合。DeepWiFi使用以下自动编码器结构:
•隐藏层1:FNN有534个神经元和tanh激活。
•隐藏层2:FNN有66个神经元和tanh激活。
•隐藏层3:FNN有534个神经元和tanh激活。
•隐藏层4:FNN有40000个神经元和tanh激活
输入层和输出层具有相同的维度。
去噪自动编码器向输入数据样本x添加均值为0、方差为σ2的高斯噪声。
结果数据xNoised=X+Nis输入到神经网络网络去噪autoencoder求解以下损失函数:(Φ∗,θ∗)=min(Φ,θ)EX[| | gΦ(fθ(xnoised))−X | | 2],(1)其中EX[·]表示X上的期望值,而|·| | 2表示’2-范数(欧氏范数)。去噪自动编码器的结构如图3所示。
利用张量流框架实现了一个去噪自动编码器,该编码器接收输入的I/Q数据并降低其维数。这些特征代表潜在变量(提取特征)。
原始信号X和重建信号ˆX之间的重建损失由[| | X−ˆX | | 2]计算。为了找到最佳参数,我们使用超带框架进行了超参数优化[29]。这个框架可以提供超过一个数量级的加速比贝叶斯参数优化方法。超带随机抽样一组超参数配置,评估所有当前配置的性能,排序配置得分,并删除最差的评分配置(连续减半)。这个过程随着迭代次数的增加而逐渐重复。因此,只有产生良好结果的构型才能得到全面评价。注意,我们使用双曲线优化第4.1-4.2节中描述的神经网络参数。
我们将可分配给单个配置的最大资源量考虑为81次迭代和3次下采样率(η=3)。用于去噪自动编码器训练的数据集由相等数量的WiFi、干扰机和噪声信号组成。数据集分为80%和20%的训练集和测试集,分别。我们使用64个样本的批量大小。图4描述了训练过程中训练集和测试集的损失。我们观察到两组的损耗都逐渐减小,没有过度拟合。

图5示出了测试集中的合法WiFi信号及其重构。我们观察到边带的噪声抑制达到10分贝。这突出了自动编码器去噪和降噪的效果。注意,在图像处理[30]中已经报告了使用去噪自动编码器的类似去噪效果,并且图5示出了RF域中的相同效果。自动编码器的输出是在步骤2中提供给分类器的一组提取特征。

自动编码器的输出是在步骤2中提供给分类器的一组提取特征。
4.2 第二步:频谱感知和信号分类
输入:从第1步开始的感测信道上的I/Q数据。
输出:将信道分类为空闲,WiFi使用或干扰,作为第3步的输入。
每个用户对感测信道上接收的I/Q数据应用基于深度神经网络的分类器,并将捕获的信号分为噪声(空闲)、WiFi信号或干扰信号。
特征是随时间接收的I/Q数据(步骤1的输出)。
每个信道有三个可能的标签:空闲(I)、另一个无线设备(W)和干扰(J)。离线收集训练数据,离线执行训练。
训练好的分类器离线加载到每个用户。记忆中只存储了神经网络的权值和偏差。每台收音机都有各自的线路。
4.2.1 信号种类(I)、(W)和(J)
对于训练和测试阶段,每个标签的信号都是如下:
1)噪声:WiFi的背景噪声介于−80dB和−100dB之间。为了模拟这种情况,我们在频域中随机选择一个−80dB和−100dB之间的数字,然后进行逆傅里叶变换以获得时间样本。
2)WiFi合法信号:利用MATLAB的WLAN系统工具箱生成WiFi信号,包括前置表和有效载荷。我们考虑以下参数:
a) 中心频率:5.25GHz,b)信道带宽:20 MHz,c)TX-RX距离:5m(默认值;我们更改SINR嵌入),d)归一化路径增益:真,e)发射天线间距:0.5波长(默认),f)接收天线间距:0.5波长(默认),g)分组格式:VHT,h)扰频器初始化:93(默认),i)信道编码:BCC(二进制卷积编码),j)APEP长度:1,k)PSDU长度:36(默认;PSDU长度是用户有效载荷中携带的字节数。对于单个用户,SDU长度为1To220−1之间的标量整数,l)长防护间隔长度:800 ns,m)短防护间隔长度:400 ns,n)a-MPDU长度:256字节,o)发射天线数量:1,p)发送的空间流数:1,q)MCS:0-9之间的变化。
我们使用特定的信道模型(如第2.2节所述)生成信道系数,并通过信道传递WiFi信号。然后,我们加入高斯白噪声。输出作为带有标签(W)的WiFi信号样本存储在训练数据中。
3) 干扰信号:在时域中,我们首先产生均值为零、方差为1的非均匀分布随机数。然后我们将这些样本采样到一个与WiFi带宽相同的选定载波信号。我们使用第2.2节中讨论的相同信道模型生成信道系数,并通过信道传递干扰信号。然后,我们加入高斯白噪声。输出作为带有标签(J)的干扰器信号样本存储在训练数据中。
使用不同的信道模型生成12000个样本。80%的数据用于训练,20%分配给测试、培训数据集包括在六种不同信道条件下产生的信号(每个信道模型2000个样本)。
4.2.2 简单机器学习分类器
为了进行基准比较,我们评估了SVM分类器在信号分类中的性能。由于其性能取决于内核类型和使用的超参数,因此超参数被调整为最佳精度。
使用了两种最常用的核函数:线性核函数和径向基函数核函数。
对于RBF核,有两个参数被考虑,C and γ。所有支持向量机核类型中的参数都是通用的,它将训练样本的误分类与决策面的简单性进行了比较。当数量较少时,决策面比较平滑,而且数量较多时,更强调对所有训练实例的正确分类。所以C用错误惩罚换取稳定性。
第二个参数γ是高斯 RBF,K(Xi,XJ)=EXP(γγ席席XJ(2))的自由参数,其中γ>0。明确了每个训练实例的影响。较大的γ仅对近邻有较小的影响。NBF,K(Xi,XJ)=EXP(γγ席席XJ(2))的自由参数,其中γ>0。明确了每个训练实例的影响。较大的γ仅对近邻有较小的影响。,K(Xi,XJ)=EXP(γγ席席XJ(2))的自由参数,其中γ>0。明确了每个训练实例的影响。较大的γ仅对近邻有较小的影响。
对于超参数整定,C=[0.0001,0.001,0.01,0.1,1.0,10.0100.01000.0]用于线性核,具有相同值的γ用于高斯RBF核。在评估步骤中,我们实施k-foldcross验证来计算交叉验证的准确度和setkas10。通过网格搜索,我们得到了最佳绩效模型的得分。采用c=1.0和γ=0.1的RBF核实现了最佳性能,仅达到66%的精度。
4.2.3 深度学习分类器
我们设计了两种深度神经网络结构,FNN和CNN,用于信号分类任务,**实现了小记忆点、高精度和低推理时间。**这些神经网络是使用keraslibrary在TensorFlow中实现的[31]。反向传播用于使用交叉熵损失函数来训练神经网络,交叉熵损失函数被定义为l=-∑mi=1βilog(yi),其中β={βi}mi=1是地面真值的二元指标,因此对于来自labelk的样本,βk=1,而其他条目都是零。神经网络预测用y={yi}mi=1表示。在这两种架构中,我们都使用了ADAM优化器[32],其学习率为10-5。
4.2.4 FNN
我们调整FNN的超参数(如层数、每层神经元数和激活函数),使用校正线性单元(ReLU)作为激活函数连接网络层输出,执行off(x)=max(0,x)操作。使用ReLU激活函数的优点是,与逻辑函数和双曲正切函数相比,ReLU激活函数的计算速度比硬件中的其他激活函数快一点,并且不会出现消失梯度问题,因为它不会对正值饱和[33]。结果FNN由以下层组成:
•完全连接层,15个神经元(ReLU激活)。
•Dropout 层,辍学概率为50%。
•完全连接层,3个神经元(Softmax激活)。
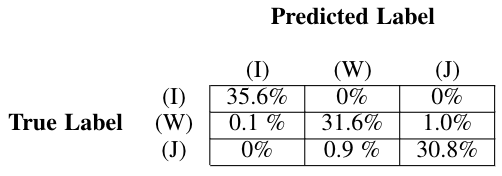
它使用了从神经网络的上一层中取出一些神经元输出,并达到了目的通过防止训练数据的复杂适应来减少过拟合的正则化方法。对于输出层,在神经网络的最后一层使用softmax交流激励函数fi(x)=exi/(∑jexj)。Softmax激活函数通常是输出类互斥的分类任务的良好选择。模糊神经网络预测正确信号的平均准确率为98.75%。FNN的混淆矩阵如表2所示。

4.2.5 CNN
我们调整CNN的超参数。产生的CNN包括以下层:
•以下五层级联:
–一个具有32个滤波器和核大小(2,5)的二维卷积层。
–一个具有32个滤波器和核大小(2,5)的二维卷积层。
–最大池层,核大小(2,2)和跨距(2,2)。
–批标准化层。
•具有18个神经元的完全连接层。
•退出层有50%的退出概率。
•完全连接层有3个神经元。
二维卷积层用于对输入应用滑动滤波器。该层通过沿输入垂直和水平移动过滤器来卷积输入,计算权重和输入的点积,再加上偏见术语最大值池层用于逐步减小表示的空间大小,以减少网络中的参数数量和计算量,从而控制过拟合。最大池层通过将输入划分为矩形池区域并计算每个区域的最大值来执行下采样。批处理规范化层用于通过一个小批处理规范化每个输入通道。其目的是加快CNN的训练速度,降低对网络初始化的敏感性。CNN预测信号标签的平均准确率为98.0%。CNN的混淆矩阵如表3所示
4.3 第三步:信号认证
输入:来自射频前端处理的I/Q数据(步骤1)和来自频谱感应和信号分类的信道标签(步骤2)。
输出:一组授权信号(提供给WiFi接收器链)。
物理层身份验证(如图2所示)的目标是通过提供物理层指纹处理能力来处理I/Q数据和验证合法身份,从而增强物理层的标准WiFi安全性(在第2层)用户.RF指纹识别的动机是减轻重放攻击在无线网络中。
最近的开源固件补丁[11]支持在缓冲区中存储和传输I/Q数据。软件无线电(SDR)还可以通过监听双方之间的合法通信并播放具有合法WiFi特征的I/Q数据来执行重放攻击。在这种情况下,信号分类可能不足以进行信号认证,并且敌方发射的信号中的RF特性可用于在物理层中对信号进行认证。**请注意,此步骤直接使用I/Q数据,而不是自动编码器跟踪的特性,因为身份验证中使用的硬件损坏可能会在自动编码器处丢失。因此,在这个步骤中直接使用I/Qdata。**该认证过程(如图2所示)的细节如下所示:
1) 频谱感知和信号分类(步骤2)采用步骤1中自动编码器的输出,并将输入信号分类为WiFi(W)、干扰机(J)或空闲(I)。
2)逻辑将信号分类结果作为输入。如果信号是WiFi信号,它会将I/Q数据传递给physicallayer authentication(RF指纹),这是物理层安全的第一步。
3)物理层身份验证使用每个发射机固有的物理层信息,如果检测到接收到的信号来自合法的发射机,则进行授权。
4)如果接收到的信号经过授权,则由WiFi接收机处理链条。
其目的是分析射频信号特征,以验证合法WiFi用户。
射频指纹识别的一种方法是通过捕获特定信道的特征(如接收信号强度指标(RSSI)电平)进行位置识别,但是这种方法不能有效地应用于RSSI电平快速变化的移动用户。
射频指纹识别的另一种方法是利用无线电特征进行识别,无线电特征分为波形域和硬件域特征(损伤)。
波形域方法可识别持续时间很短(微秒)且难以建模的基于感知的行为。瞬态特性也容易受到噪声和干扰的影响。硬件主方法基于捕获硬件损伤,如频率、幅度和相位误差、I/Q偏移和时域和频域的同步偏移。我们追求第二种方法。
为了验证签名,我们使用两层方法(如图6所示):
1) 异常值检测确定签名是否属于任何经过身份验证的签名。如果签名未经验证,则会被拒绝。如果签名属于经过身份验证的用户,那么我们继续下一步。
2) Classification验证签名是否属于它声明的传输者。分类器返回一个储存。什么时候对数据前导码进行解码,验证发送方和分类器(用户ID)的输出是否匹配。
接下来,我们将描述PHY层损伤模型、特征提取、数据生成和认证步骤。
4.3.3 物理层损伤建模
在MATLAB中生成训练数据,以考虑不同的软件损伤。特别地,考虑了采样率偏移、载波频率偏移和I/Q平衡偏移(幅度和相位)。
为了对发射机和接收机之间的采样率偏移(SRO)进行建模,将传输数据重新采样,并利用原始采样率的P/Q倍来重新采样,从而提高插值和判决因子。
这些参数对于每对发射器-接收器是不同的。我们使用MATLAB的采样功能。利用MATLAB的helperfrequencyoffset函数,对前一个信号引入了频率偏移。[34]中提出了这种联合和载波频率偏移损伤。最后,对于每对收发两用机,使用以下公式将恒定的I/Qoffset加上ψ(表示幅度不平衡)和φ(表示相位不平衡)[35]:
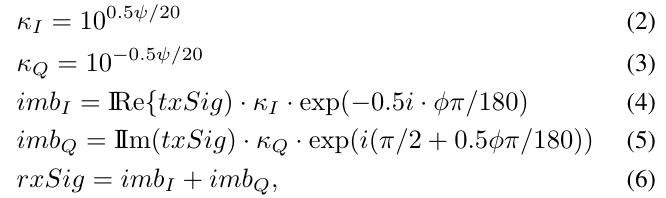
其中txsigandxsigare分别表示发送和接收信号,κi和κq分别表示同相和正交增益,imbiandimbq分别表示同相和正交不平衡,振幅不平衡ψ用indB表示,相位不平衡φ用度表示。图7显示了一个示例,其中SRO由ω表示,cro是载波频率偏移。
4.3.2 信号波形特征提取
接下来,我们提取信号特征并获得每个波形的指纹特征。
首先利用MATLAB通信工具箱检测i/Q不平衡和获取补偿系数IQComp。使用iqcoef2imbal估计I/Q系数,它计算给定补偿器的振幅和相位不平衡系数。我们还需要在频域和时域中提取同步。频域同步有两个分量,称为粗偏移和精偏移。时域同步只有一个组件。利用MATLAB的WLANCOARSECFOFESTIMATE、WLANFINECFOFESTIMATE和WLANSYMBOLTIMINGESTIMATE函数分别对粗、精中心频偏和symboltiming同步进行了估计。
通过这些步骤,我们,9获取五个特征:粗中心频率偏移、精中心频率偏移、符号定时同步、幅度im平衡和相位不平衡。
注意,为了提取这些特性,我们使用了领域知识,而不是遵循纯数据驱动的方法。这是由于硬件损害会导致接收信号的非常细微的变化,因此需要领域知识来提供一个鲁棒算法。
4.3.3 Data 产生
作为一个综合数据集,我们以5db增量为每一个,以5db增量的snr值生成E50信号样本子带同样的实验重复给10个用户。为了引入频率偏移损伤,我们认为atransmmiter和接收器对之间的SRO是100个部分的电容(PPM)的倍数,即ωj=100jPPM,如[34]所建议。为此,我们采用插值因子asp=104,并将每个用户的指定系数Q=p−Jr更改为userjasωj=(1−p/(p−j))106PPM的aSRO。注意,如果偏移量较大,则RF指纹签名将更容易区分。这些偏移在不同的NR和信道实现过程中保持恒定。为了引入振幅和相位平衡,在使用者之间增加1dB和10度增量,这样JTH用户有J DB和10×J出口不平衡
4.3.4 异常值检测
为了对信号进行授权,我们首先使用一种简单的离群点检测方法,其目的是识别哪些签名被授权,哪些没有被授权。
我们测试并评估了三种不同方法的性能:(i)一类支持向量机[36],(ii)隔离林[37]和(iii)最小协方差行列式(MCD)[38],[39]方法。我们的结果表明,MCD,也称为椭圆包络方法,优于其他两种方法。接下来,我们将简要介绍这三种方法,然后给出绩效评估结果。
•一类SVMis无监督异常值检测方法。它学习了一个边界,划定了初始观测的轮廓线。如果一个新的观测值位于边界分隔的子空间中,它就好像来自同一个群体(一个授权的签名)。否则,如果他们在边境之外,这就是一个异常值(未经授权的签名)。参数ν是一类支持向量机的边距,它决定在边界之外发现新的、但规则的观测值的概率。
•通过随机选择一个特征,然后随机选择所选特征的最大值和最小值之间的一个分割值来隔离观测值。这种递归分区可以用一个树结构来表示,分离一个样本所需的拆分次数等于从根用户到终止用户的路径长度。这个路径长度,在这样的随机树的森林上平均,是正态性和我们的决策函数的度量。
•mcd拟合一个椭圆包络,使得椭圆外的任何数据点都是一个离群值。它是多元分布的一个高度可靠的估计量[38]。它使用马氏距离,使得md(x)=√(x−μx)T∑−1x(x−μx),其中μx和∑−1x是数据x的平均值和协方差。
假设有10个签名,其中6个是授权的,4个是未授权的(看不见的)签名。表4显示提出了MCD离群点检测的混淆矩阵,平均准确率达到89.8%。我们还分别在表5和表6中给出了ν=0.2的一类支持向量机和隔离林方法的混淆矩阵。这两种分类器的准确率分别只有70.0%和69.1%,顺序与以前相同。第二步,采用有监督分类和基于employRBF核的支持向量机,C=1,γ=0.1,准确率达到100%。



4.4 第四步:信道选择和信道接入
输入:第2步中的一组通道标签和SINR。
输出:为其选择的通道的ID传输。
每个用户单独开始扫描通道集(随机初始化),并使用基于深度学习的分类器将每个通道分类为(I)、(W)或(J)(如第3步所述)。
1)如果通道被分类为(I)用户发送并中断扫描循环。
2)否则,如果信道被分类为(W),则用户后退(使用指数计时器)并从2K−1(其中是计时器窗口)倒计时。
3) 否则,如果信道被分类为(J),它将被添加到一个可能的列表中进行数据传输,用户将扫描下一个信道。
请注意,第三步在基线wifit中不存在,它以相同的方式处理通道(W)和(J),并退出所有这些通道。在扫描通道结束时,每个用户执行以下内容:
1)如果没有(I)信道(信道为(W)和(J)),则用户选择具有最佳SINR和传输的信道(J)
2)如果没有信道(I)和(J),即所有信道为(W),而退避计数器不为零,用户等待一个时隙并将所有计数器减少1.
3)如果任何退避计数器为零,则用户感知该信道。•如果信道为(I),则用户在该信道上传输。•否则,用户重置退避计数器并统一选择0和2K+1−1之间的随机数。
4.5 步骤5:LPI/LPD的功率控制
输入:步骤4中所选频道的ID和SINR。
输出:提供给WiFi发射机的发射功率链。
每个DeepWiFi用户将其功率降至最低,以满足其预期接收机对LPI/lpd容量的最小SINR要求,前提是执行从其自身到其预期接收机的信道估计定期地。考虑一个用户i所选择的传输功率和干扰具有感测阈值τj,并让hij denote从user i to jammer j获得路径损失。然后,jammer j无法检测到user iifPihij< τj的传输。请注意,τj and hij对useri是未知的
4.6 步骤6:自适应调制和编码
输入:第4步中所选信道的ID和SINR。
输出:MCS电平和该信道的相应速率提供给WiFi发射机链。
每个用户基于在感测信道上测量的SINR来选择802.11ac的调制和编码速率。我们考虑为802.11ac的甚高吞吐量(VHT)方案定义的mcs,如表7所示。

我们在接收端用MCSscheme标记生成的样本,MCSscheme给出了最佳的错误率和吞吐量-关闭。由在设计上,我们希望低信噪比的MCS电平(索引)和高信噪比的MCS电平。这种方法提供了一种有效的链路自适应。我们确定一个表,为给定的SINR分配最佳MCS。该表预先加载到每个根据测得的SINR调整MCS的计算机。为了建立这个表,我们首先生成传输的信号使用高MCS级别。我们通过信道传输信号并添加噪声。我们使用扩频器估计接收端的信道并均衡信号。然后用均衡后的样本对信号进行解调。因此,我们通过比较发送和接收的比特来获得分组错误率。如果包错误率不为零,我们降低MCS级别并重复相同的过程。如果在接收端仍然有错误的位formcs0,那么我们保持MCS为0。图8示出了根据SINR最大化速率的最佳mcslevel(当分别使用256、512和1024字节的数据有效负载时)。
4.7 第7步:路由
输入:从给定用户到其邻居的链路速率集(步骤6给出)(注意,用户和其邻居的队列长度集是通过步骤7中的信息交换获得的)。
输出:要服务的流的ID和为下一跳传输选择的邻居的ID。
每个用户在没有任何集中控制器的分布式设置中应用背压算法[40]。注意,这里还可以应用其他无线路由算法。我们使用backpressure算法来反映路由决策中的信道和队列信息,这些路由决策利用了步骤6中优化的链路速率。每个用户与其邻居交换频谱实用程序中的本地信息[41]。每个用户在timet为每个流保留一个单独的队列,并返回logqsi(t)。对于所有链路,用户选择要传输的流作为在接收端和发送端具有最大队列积压差异的流,即,对于每个链路(i,j),用户i选择流
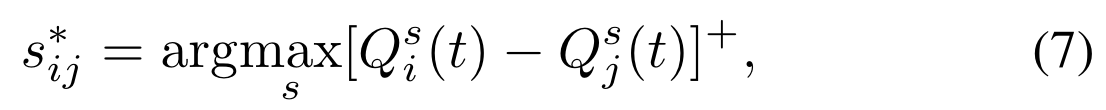
然后,我们定义了频谱效用
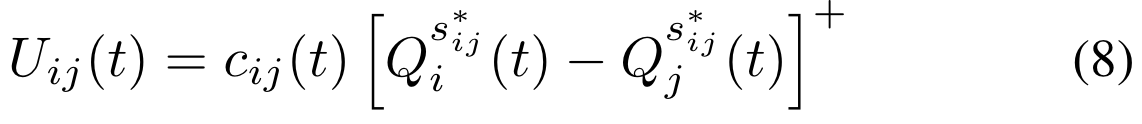
对于用户传递到用户j,其中cij(t)是时间t(取决于步骤5的传输功率和步骤6中的mcs)时链路(i,j)上的速率。用户传递到选定邻域*t,产生最大频谱实用程序,即。
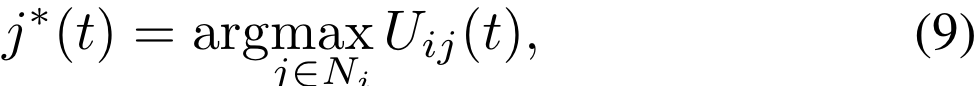
其中ni是useritoselect的下一跳候选集。每个用户使用数据通道(带内)进行交换与邻居控制信息。没有单独的控制通道。用户通过使用以下四个阶段异步地在分布式设置中做出决策[41]:
1) 邻域发现和信道估计,2)流信息更新的交换和背压算法的执行,3)传输决策协商,以及4)数据传输。
5 网络级性能评估的仿真设置
每个模拟时间生成的用户数为9个,m=40个通道,生成5个流。arenJ=40干扰机,每个干扰器分配到一个信道。每个随机干扰机都是独立打开的,每次模拟时都会有jammingpJon的概率,PJIS在0到1之间变化,增量为0.05。接收到的SINR(由于干扰器和噪声)也随1个二进制数而变化。每个用户将通信量生成到随机选择的EddesignationJ。从源目标对(i,j)的平均raterij=500kbps的[0,1]Mb/s中随机选择流量率。仿真软件在MATLAB中实现。模拟时间为100秒。利用MATLAB-WLAN系统工具箱实现了WiFi的基线特征。在张量流中实现了深层学习代码。
我们比较了DeepWiFi与baselineWiFi(无深度学习或抗干扰)和抗干扰MAC协议JADE的性能[12]。在存在自适应对抗干扰的情况下,JADE是渐近最优的。由于基线WiFi的设计不是为了缓解任何干扰,它与DeepWiFi的比较量化了干扰防御的效果。在deepwifi中,我们使用ieee802.11ac标准中定义的指数退避。DeepWiFi与JADE的比较量化了信道接入和不同解决方案的差异空间。频道JADE中的访问不区分WiFi和干扰信号,而DeepWiFi区分。因此,解空间是不同的。我们发现DeepWiFi在性能上比基线WiFi和JADE有很大的提高。在这三种算法中,我们采用了自适应调制编码和背压路由算法进行了比较。
网络拓扑如图9所示,我们在给定的区域上随机均匀地部署了九个用户。由于友好用户之间不会因退避机制和信号分类而相互干扰,因此他们的位置不会影响系统性能。友好用户(DeepWiFi或baselineWiFi)标有IDs 1-9。每个链路表示一组邻居(取决于小于0db的SINR阈值)。这40个干扰机在图9的右侧和顶部被描绘为没有链接的用户(用户ID为10-49)。每个干扰机负责干扰一个频道(40个频道中的一个)。例如,ID为10、11、12的干扰机将分别干扰信道1、2、3等。当干扰机打开(关闭)时,它被描绘成一个红色(蓝色)用户。
考虑以下指标来衡量性能:
- 每个用户的平均吞吐量(Mb/s):每个用户在模拟期间可以达到的平均吞吐量。
2)累计吞吐量:模拟期间所有用户的网络平均吞吐量。

6 性能结果
6.1 概率(随机)干扰机
首先,我们将SINR修正为0db,然后从随机开始干扰机fixedSINR(0dB)的单个用户吞吐量(当npj=0.7)如图10所示。端到端网络吞吐量如图11所示,是Pj的函数。对于smallpJ,DeepWiFi和baseline WiFi都实现了相同的吞吐量,因为所有用户都可以在没有内部或外部干扰的情况下找到空闲频道。根据[12],JADE使用其默认参数运行。由于其信道接入概率较小,JADE的启动情况比基线WiFi和DeepWiFi差。当增量超过0.3时,基线WiFi的吞吐量开始急剧下降,而DeepWiFi维持其吞吐量并提供相对于基线WiFi的主要吞吐量增益。当pj≥0.5时,JADE通过调整信道接入概率,抗干扰能力优于基线wifib,性能优于DeepWiFi。即使所有信道一直被阻塞(pj=1),DeepWiFi也能实现接近70Mbs的网络端到端吞吐量,而基线WiFi和JADE的吞吐量为零(请注意,波动是由于信道的随机性和干扰效应造成的)。DeepWiFi激活的链路比基线WiFi和JADE多,在这两种方案中,用户都会在干扰信道上后退,而DepWiFi允许用户在降级模式下在干扰信道(如果noidle信道可用)上进行传输。由于干扰和噪声的影响,我们开始改变SINR。累积吞吐量如图12所示,是SINR atpJ=0.8的函数。对于所有方案,累积吞吐量随着SINR的增加而缓慢增加,并且DeepWiFi优于其他所有SINR。另外,请注意,本文中的累积吞吐量项表示网络中的多个跃点,并表示端到端网络吞吐量。



6.2 基于静态传感的干扰机
到目前为止,我们考虑了以固定概率开启的随机(概率)干扰机。接下来,我们评估了基于感知的干扰机的效果和LPI/LPD的功率控制性能。在这里,我们考虑一个静态干扰机,它具有恒定的感知阈值τ,而自适应干扰机(第6.3节讨论)可以动态调整其感知阈值。
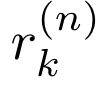
表示干扰机在信道NAT timek上接收到的信号。如果在信道上检测到大于或等于阈值τ的信号,即isr(n)i≥τ,则基于静态传感的干扰机开启,否则以固定的干扰概率pJ开启。在我们的实验中,基于感知的干扰机的功率检测阈值在2db到10db之间变化,每增加1db。图13显示了基于干扰源的感知开启时,DeepWiFi、JADE和基线的平均单个吞吐量(Mb/s),pJ=0.7,τJ=5dB。我们观察到,基于感知的干扰机将基线WiFi的吞吐量降低到零,因为用户最终会无限期地后退。接下来,我们将向DeepWiFi展示发射功率控制的结果,以演示LPI/LPD功能。具有lpi/LPD发射功率控制的DeepWiFi可以通过在τJ以下工作来避免干扰。图14示出了每个用户的发射功率的直方图。我们观察到,大约一半的传输具有低功率以提供LPI/lpd能力,而另一半则具有高功率以支持在干扰信道上的通信。因此,与基线WiFi、JADE和没有LPI/LPD的DeepWiFi相比,使用LPI/LPD的DeepWiFi可以实现更高的速率。图15显示了当基于感测的干扰机打开时,DeepWiFi和基线WiFi的平均单个吞吐量(Mb/s),pJ=0.7,τJ=2dB,并且针对LPI调整发射功率/LPD。我们观察到,随着干扰机变得更具反应性,即干扰机τj的检测阈值从10 dB降低到2 dB,系统的吞吐量DeepWiFi和JADE减少,而baselineWiFi的吞吐量则完全减少
当用户超过可用频道时,我们也会评估DeepWiFi。我们考虑9个用户和9个流量共享6个信道。图16显示了DeepWiFi、基线WiFi和JADE的累积吞吐量与干扰概率的函数关系。我们观察到,随着干扰概率的增加,累积吞吐量呈线性下降。请注意,DeepWiFi的累积吞吐量取决于干扰概率、用户数、信道数、退避机制、干扰功率和信号分类精度。比较图。在图11和图16中,我们观察到当用户数少于信道数时,累积吞吐量与干扰概率的斜率呈对数关系,而当用户数多于信道数时,斜率几乎是线性的(即,拥塞的影响增加)。




6.3 自适应干扰机
接下来,我们考虑通过观察WiFi用户的信道接入模式来动态调整感知阈值τtat时间的自适应干扰机。在时间kis1(r(n)k≥τk)信道n(干扰机感知到它时)上的信道利用率,其中1(x)表示指示函数,即1为真,0为假。在时间t,自适应干扰机的效用函数包括信道利用率和自身功耗,定义为

其中,pki是时间k和w≥0时的干扰功率,是一个亮度常数,用于平衡干扰机功耗和WiFi信道利用率之间的折衷。矢量sr(t)和p(t)分别表示干扰机的接收信号和发射功率值,在时间和通道结束的0个时间窗内,

图17显示了DeepWiFi、baseline和jade在自适应干扰下的性能。我们将初始传感阈值取为τ0=1,加权常数取为w=1,步长常数∆=0.5。我们观察到,在所有情况下,在存在自适应干扰的情况下,累积吞吐量都显著降低,而与基线WiFi和翡翠。
总体来说, 对三种不同类型干扰机的评估结果表明,DeepWiFi提供了可靠的通信。

7 实现、复杂性和过度关注的方面
DeepWiFi可以在内核或WiFi中实现卡。打开-Nexmon[11]等源固件可以从WiFi中提取I/Q数据,以便在内核中处理I/Q数据。为物联网构建的系统芯片(SOC)解决方案,如,14Qualcomm QCS603/QCS605[42]还可用于提取可在内核中处理的I/Q数据(或可移动到其他FPGA或ARM进行进一步处理)。这些SOC包括802.11ac WiFi和集成在芯片中的神经处理引擎(用于深度学习),可用于射频通信和深度学习。训练通常离线进行,训练后的模型被移植到内核或其他平台进行推理。
DeepWiFi可以通过两种方式获取训练数据方法。首先,通道和信号可以通过MATLAB WLANToolbox生成(如第2.2节所述),并可用于构建训练数据。第二,一个真正的802.11.ac WiFi卡可以用来进行anSDR捕获的空中传输,这些通道和信号可以用于训练。
为了评估时间复杂度和开销,我们在一个低成本的嵌入式系统NVIDIA Jetson Nano Developer Kit中实现了每个深度学习任务[43]。为了有效地部署,我们将Tensorflow代码转换为TensorRT[44],即NVIDIA嵌入式系统的推理优化器。我们重复了1000次测试来计算平均推断时间。例如,每个数据样本的前端处理时间为0.09毫秒。802.11ac标准中的典型帧为5.484毫秒。[16] 因此,前端处理时间被测量为802.11帧的1.6%。报告的处理时间适用于已有数据可供处理的情况。由于在后台运行其他进程(如其他WiFi操作)会降低现成硬件的性能,我们使用stress ngsoftware[45]通过生成模拟高负载的后台进程,对嵌入式GPU的内存使用情况进行了压力测试条件。我们观察到深度学习操作的处理时间增加了33%,但相对于MAC帧长来说仍然很小。注意,定制的ASIC芯片和fpga可以进一步减少嵌入式平台上的开销和处理时间。
对于信号分类任务,我们观察到FNNmodel平均需要0.009毫秒来预测每个样本点。开另一方面,CNN模型需要0.035毫秒来预测超过1000次的重复。作为fn和CNN模型之间的比较,这两种架构具有相似的特性表演。自从CNN结构有更多的层次,在推理时间内处理一个单一的波形大约需要四倍的时间。作为回报,cnn在网络上的占地面积更小硬件。注意由于FNN使用完全连接的层来减少从一层到另一层的尺寸,而CNN使用以滑动窗口方式利用特征映射的卷积层,因此预计硬件占用空间的差异。有关FNN和CNNmodels中参数数量的更多讨论,请参阅[33,p.357]。
对于信号认证任务,MCD异常值检测时间为0.0556毫秒,一类SVM时间为52.813毫秒,隔离林时间为33.521毫秒毫秒。
添加在这些组件中,我们观察到前端处理、使用FNN的信号分类和使用MCD的信号认证的总处理开销为0.1546毫秒,仅为802.11ac帧的2.8%。
对于路由开销,backpressure算法ex改变了常规距离向量路由算法中的典型消息。消息交换的数量没有封闭式表达式,确切的数量取决于网络和通信条件。在文献[46]中,背压算法是用SDR实现的,它根据经验评估了消息交换的数量
8 结论
我们提出了应用机器学习的DeepWiFi协议,特别是deeplearning,使WiFi适应频谱动态,并与baselineWiFi和另一种抗干扰MAC协议相比提供了更大的吞吐量增益。deepwifi的设计目的是减轻概率和传感干扰机的网外干扰影响。基于ieee802.11ac的PHY收发器链,DeepWiFi在不改变PHY和MAC帧格式的情况下为WiFi收发器提供决策参数。DeepWiFi应用基于深度学习的数据编码器来提取特征,并应用深度神经网络(FNN或CNN)将信号分类为WiFi、干扰或闲着的。那个分类为WiFi的信号通过rf指纹进一步处理,rf指纹通过机器学习识别基于硬件的功能,并验证合法性WiFi信号。通过在感知到的信道上使用这些信号标签,DeepWiFi支持用户使用空闲信道、退回合法WiFi信号使用的信道,以及访问(如果降级模式中需要)由合法WiFi以外的信号占用的信道。deepwifi用户通过backpres-sure算法优化其LPI/LPD和mc的发射功率以最大化链路速率和路由决策。利用MATLAB-WLANToolbox生成的信道和信号,对分布式网络中的DeepWiFi进行了仿真。我们展示了DeepWiFi可以帮助WiFi用户维持他们的工作状态,相对于基线WiFi和另一种抗干扰MAC协议来说,性能有了很大的提高,特别是当通道可能被干扰并且SINR较低时。
附录
8.1 其他降维技术
除了一个自动编码器,我们还测试了噪声、WiFi和干扰信号的可分性,使用了其他维度还原方法,如主成分分析(PCA)[27]和t-分布随机邻居嵌入(tSNE)[28]。我们得出结论,这些技术不能分离感兴趣的信号类型。PCA方法是一种正交线性变换,它将数据转换成由主坐标定义的新坐标系[27]。pca的第一个分量可以通过求解
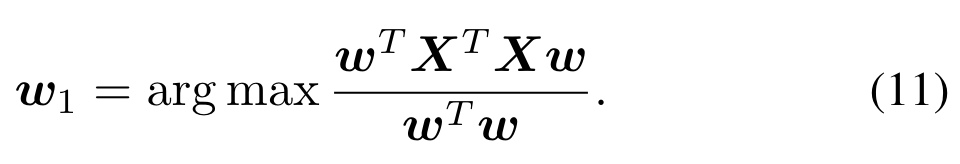
这个项也叫做瑞利商,最大值出现在矩阵的最大特征值处。主成分分析的其他成分是通过使用类似的程序发现的,但要受先前成分的影响。例如,为了计算第k个PCA分量,在求解(11)之前,从X中提取k−1PCA分量。因此,我们首先执行subtraction
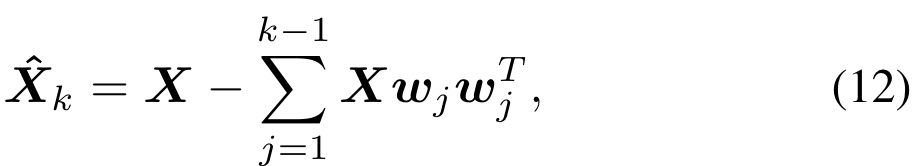
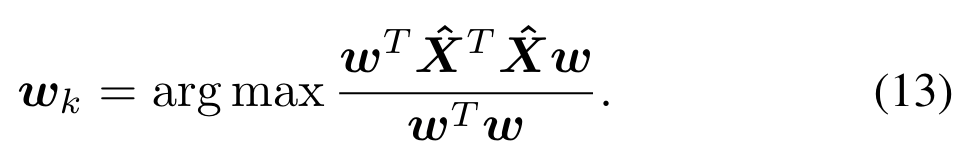
首先,我们使用PCA将维数减少到2,N=2。图18说明了三种信号类型的分布。我们观察到WiFi信号沿着两个特征向量方向分布,而干扰和噪声则聚集在原始信号周围。接下来,我们将维度大小增加到3,N=3,并尝试查看它们是否在三维中分开。图19和20说明了三种成分sn=3的分布。图19显示了所有三种类型的点在彼此的顶部,其中图20在不同的图中绘制了每种类型的点。我们观察到,虽然WiFi信号在三维中均匀分布,但干扰和噪声信号聚集在较小的值中(在x∈[−10,15]andy∈[−20,5]周围的水平面中),这使得很难区分。我们的结论是WiFi和jamming信号不是线性可分离的,而PCA不是区分这三种信号类型的一个很好的候选方法。
接下来,我们尝试另一种常用的降维技术t-SNE。与PCA不同,t-SNE使用数据点之间的联合概率,并试图最小化低维嵌入和高维数据的联合概率之间的Kullback-Leibler(KL)散度[28]。t-SNE方法首先计算输入数据之间的条件概率pj | i
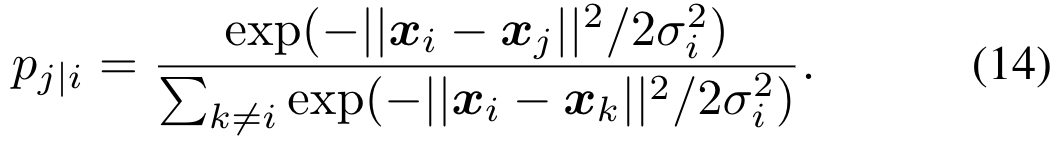




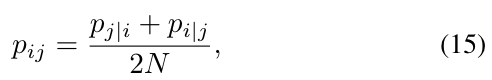
其中ndent表示采样点的数量。Letz1,…,zn表示简化的 使zi∈rd的维数,其中d表示要缩减到的维数。在这种情况下,我们评估ford=2和d=3。表示ziandzjind维度的相似性为
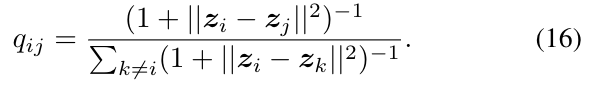
利用这些相似性度量,t-SNE方法利用数据分布的降维分布的KL散度,并求解
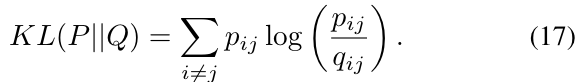
KL散度在t-SNE中用作代价函数
,我们采用t-SNE方法对干扰信号和干扰信号进行降维处理,同时为了提高视觉清晰度,本研究将噪声放在一边。虽然t-SNE特别适合于高维数据集的可视化,但图21和图22表明,WiFi和干扰信号不能用簇之间的平滑线分离。因此,我们不使用t-SNE

8.2 信号分类
如第5.3节所述,生成的数据集分为80%的训练和20%的测试。我们在图23(a)-(b)中提供了训练集和测试集的FNN和CNN架构的精度和损失函数。这些图中的结果验证了最终模型不会出现过拟合或欠拟合。