ElasticSearch7.10.2
1 什么是RestFul
REST : 表现层状态转化(Representational State Transfer),如果一个架构符合REST原则,就称它为 RESTful 架构风格。
资源(Resources): 所谓"资源",就是网络上的一个实体,或者说是网络上的一个具体信息
表现层(Representation) :我们把"资源"具体呈现出来的形式,叫做它的"表现层"。
状态转化(State Transfer):如果客户端想要操作服务器,必须通过某种手段,让服务器端发生"状态转 化"(State Transfer)。而这种转化是建立在表现层之上的,所以就是"表现层状态转化"。
REST原则就是指一个URL代表一个唯一资源,并且通过HTTP协议里面四个动词:GET、POST、PUT、DELETE对应四种服务器端的基本操作: GET用来获取资源,POST用来更新资源(也可以用于添加资源),PUT用来添加资源(也可以用于更新资源),DELETE用来删除资源。
2 什么是全文检索
全文检索是计算机程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置。当用户查询时根据建立的索引查找,类似于通过字典的检索字表查字的过程。
全文检索(Full-Text Retrieval(检索))以文本作为检索对象,找出含有指定词汇的文本。全面、准确和快速是衡量全文检索系统的关键指标。
关于全文检索,我们要知道:
1 只处理文本。
2 不处理语义。
3 搜索时英文不区分大小写。
4 结果列表有相关度排序。
3 什么是ElasticSearch
Elasticsearch是一个基于Apache Lucene(TM)的开源搜索引擎。无论在开源还是专有领域,Lucene
可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。
但是,Lucene只是一个库。想要 使用它,你必须使用Java来作为开发语言并将其直接集成到你的
应用中,更糟糕的是,Lucene非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目
的是通过简单的 RESTful API 来隐藏Lucene的复杂性,从而让全文搜索变得简单。
4 ES的诞生
多年前,一个叫做Shay Banon 的刚结婚不久的失业开发者,由于妻子要去伦敦学习厨师,他便跟着也去了。在他找工作的过程中,为了给妻子构建一个食谱的搜索引擎,他开始构建一个早期版本的Lucene。
直接基于Lucene工作会比较困难,所以Shay开始抽象Lucene代码以便Java程序员可以在应用中添加搜索功能。他发布了他的第一个开源项目,叫做“Compass”。
后来Shay找到一份工作,这份工作处在高性能和内存数据网格的分布式环境中,因此高性能的、实时的、分布式的搜索引擎也是理所当然需要的。然后他决定重写Compass库使其成为一个独立的服务叫做Elasticsearch。
第一个公开版本出现在2010年2月,在那之后Elasticsearch已经成为Github上最受欢迎的项目之一,代码贡献者超过300人。一家主营Elasticsearch的公司就此成立,他们一边提供商业支持一边开发新功能,不过Elasticsearch将永远开源且对所有人可用。
Shay的妻子依旧等待着她的食谱搜索……
5 ES的应用场景 json格式数据 restful
Es主要以轻量级JSON作为数据存储格式,这点与MongoDB有点类似,但它在读写性能上优于 MongoDB 。同时也支持地理位置查询 ,还方便地理位置和文本混合查询 。 以及在统计、日志类数据存储和分析、可视化这方面是引领者。
国外:
Wikipedia(维基百科)使用ES提供全文搜索并高亮关键字、StackOverflow(IT问答网站)结合全文搜索与地理位置查询、Github使用Elasticsearch检索1300亿行的代码。
国内:
百度(在云分析、网盟、预测、文库、钱包、风控等业务上都应用了ES,单集群每天导入30TB+数据, 总共每天60TB+)、新浪 、阿里巴巴、腾讯等公司均有对ES的使用。
使用比较广泛的平台ELK(ElasticSearch 全文检索服务器 核心, Logstash, Kibana)。
6 ES的安装
# 1 安装前准备
centos7 +
java 8 +
elastic 7.10.2
# 2 在官方网站下载ES
wget http://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.4.1.tar.gz
# 3 安装JDK(必须JDK1.8+)
# 4 配置环境变量
vim /etc/profile
在文件末尾加入:
export JAVA_HOME=jdk的位置
export PATH=$PATH:$JAVA_HOME/bin
# 5 重载系统配置
source /etc/profile
# 6 创建普通用户(es不能作为root用户启动)
a 在linux系统中创建新的组
groupadd es
b 创建新的用户es并将es用户放入es组中
useradd es -g es
c 修改es用户密码
passwd es
# 7 上传es到普通用户的家目录,并安装elasticsearch
tar -zxvf elasticsearch-7.10.2.tar.gz
# 8 elasticsearch的目录结构
bin 可执行的二进制文件的目录
config 配置文件的目录
lib 运行时依赖的库
logs 运行时日志文件
plugins es中提供的插件
# 9 运行es服务
在bin目录中执行 ./elasticsearch
# 10 测试ES是否启动成功
在命令终端中执行: curl http://localhost:9200 出现以下信息:
{
"name" : "DESKTOP-2NN438G",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "YExzP7U1Q3iHj56RhfmMDQ",
"version" : {
"number" : "7.10.2",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "747e1cc71def077253878a59143c1f785afa92b9",
"build_date" : "2021-01-13T00:42:12.435326Z",
"build_snapshot" : false,
"lucene_version" : "8.7.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
# 10. 开启ES远程访问
vim elasticsearch.yml 将原来network修改为以下配置:
network.host: 0.0.0.0
# 11. 关闭网络防火墙
systemctl stop firewalld 关闭本次防火墙服务
systemctl disable firewalld 关闭开启自启动防火墙服务
# 各种报错解决方案:
启动时错误解决方案
# 12. 外部浏览器访问即可
http://es的主机名:9200 出现如下信息说明安装成功:
{
"name" : "DESKTOP-2NN438G",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "YExzP7U1Q3iHj56RhfmMDQ",
"version" : {
"number" : "7.10.2",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "747e1cc71def077253878a59143c1f785afa92b9",
"build_date" : "2021-01-13T00:42:12.435326Z",
"build_snapshot" : false,
"lucene_version" : "8.7.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
# 13 权限不足解决方法:
chown -R es:es /usr/local/elasticsearch/ # elasticsearch用户没有该文件夹的权限(用户是es),执行命令
# 14 内存不足解决方案
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
elasticsearch启动时遇到的错误
问题翻译过来就是:elasticsearch用户拥有的内存权限太小,至少需要262144;
解决:
切换到root用户
执行命令:
sysctl -w vm.max_map_count=262144
查看结果:
sysctl -a|grep vm.max_map_count
显示:
vm.max_map_count = 262144
上述方法修改之后,如果重启虚拟机将失效,所以:
解决办法:
在 /etc/sysctl.conf文件最后添加一行
vm.max_map_count=262144
即可永久修改
# 15 [1]: the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
在elasticsearch的config目录下,修改elasticsearch.yml配置文件中:
cluster.initial_master_nodes: ["node-1"]
# 16 max file descriptors [4096] for elasticsearch process is too low, increase to at least [65535]
解决办法:
将当前用户的软硬限制调大。
找到文件 /etc/security/limits.conf,编辑,在文件的最后追加如下配置:
* soft nofile 65535
* hard nofile 65537
soft nofile表示软限制,hard nofile表示硬限制,
上面两行语句表示,用户的软限制为65535,硬限制为65537,
即表示用户能打开的最大文件数量为65537,不管它开启多少个shell。
硬限制是严格的设定,必定不能超过这个设定的数值。
软限制是警告的设定,可以超过这个设定的值,但是若超过,则有警告信息。
在设定上,通常soft会比hard小,举例来说,soft可以设定为80,而hard设定为100,那么你可以使用到90(因为没有超过100),但介于80~100之间时,系统会有警告信息。
修改了limits.conf,不需要重启,重新登录即生效。
查看当前用户的软限制
命令:ulimit -n 等价于 ulimit -S -n
结果:65535
查看当前用户的硬限制
命令:ulimit -H -n
结果:65537
7 正向索引和倒排索引
正向索引与倒排索引,这是在搜索领域中非常重要的两个名词,正向索引通常用于数据库中,在搜
索引擎领域使用的最多的就是倒排索引,我们根据如下两个网页来对这两个概念进行阐述:
html1
我爱我的祖国,我爱编程
html2
我爱编程,我是个快乐的小码农
正向索引
假设我们使用mysql的全文检索,会对如上两句话分别进行分词处理,那么预计得到的结果如下:
我 爱 爱我 祖国 我的祖国 编程 爱编程 我爱编程
我 我爱 爱 编程 爱编程 我爱编程 快乐 码农 小码农
假设我们现在使用正向索引搜索 编程 这个词,那么会到第一句话中去查找是否包含有 编程 这
个关键词,如果有则加入到结果集中;第二句话也是如此。假设现在有成千上百个网页,每个网页
非常多的分词,那么搜索的效率将会非常非常低些。
倒排索引
倒排索引是按照分词与文档进行映射,我们来看看如果按照倒排索引的效果:
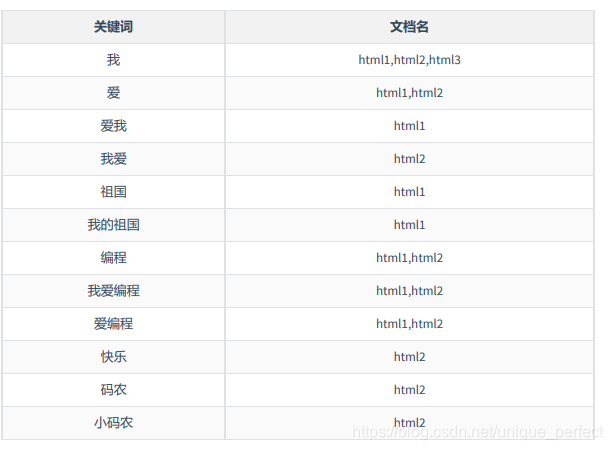
如果采用倒排索引的方式搜索 编程 这个词,那么会直接找到关键词中查找到 编程 ,然后查找
到对应的文档,这就是所谓的倒排索引。
8 ES中基本概念
8.1 接近实时(Near Real Time 简称NRT)
Elasticsearch是一个接近实时的搜索平台。这意味着,从索引一个文档直到这个文档能够被搜索到有一个轻微的延迟(通常是1秒内)
8.2 索引(index)
Elasticsearch中的索引有多层的意思:
a 某一类文档的集合就构成了一个索引,类比到数据库就是一个数据库(或者数据库表);
b它还描述了一个动作,就是将某个文档保存在elasticsearch的过程也叫索引;
c 倒排索引。
8.3 文档(document)
具体的一条数据,类比到数据库就是一条记录。

8.4 映射(Mapping)
mapping 是ES每一个文档的约束信息,例如属性的类型,是否能被索引等。
8.5 DSL
DSL 是 ES 的查询语言。
8.6 类比

在7.0之前,一个Index可以创建多个类型,从7.0开始,一个索引只能创建一个类型,也就是 _doc
9 Kibana的安装
Kibana是世界上最受欢迎的开源日志分析平台ELK Stack中的“K” ,它为用户提供了一个工具,用于
在存储于Elasticsearch集群中的日志数据进行检索,可视化和构建仪表板。
Kibana的核心功能是数据查询和分析。使用各种方法,用户可以搜索Elasticsearch中索引的数据,
以查找其数据中的特定事件或字符串,以进行根本原因分析和诊断。基于这些查询,用户可以使用
Kibana的可视化功能,允许用户使用图表,表格,地理图和其他类型的可视化以各种不同的方式可
视化数据。
1 下载Kibana
https://www.elastic.co/downloads/kibana
2 编辑kibana配置文件
[root@localhost /]# vim /etc/kibana/kibana.yml
3 修改如下配置
server.host: "10.102.115.3" #Kibana服务器主机名
elasticsearch.hosts: ["http://10.102.115.4:9200"] #Elasticsearch服务器地址
4 访问kibana的web界面
http://10.102.115.3:5601/ #kibana默认端口为5601 使用主机:端口直接访问即可
5 kibana启动bug
Error: Unable to write Kibana UUID file, please check the uuid.server configuration value in kibana.yml and ensure Kibana has sufficient permissions to read / write to this file. Error was: EACCES
解决:在root下为 为kibana赋权
chown -R elsearch:elsearch /home/es/kibana-7.6.1-linux-x86_64/ # elsearch表示用户
10 RestAPI
10.1 基本CRUD
GET movies/_search # 查询movies的数据
GET movies/_count #查询movies的总数
GET _cat/indices #查看所有的索引
GET movies/_doc/24 #查询id为24的数据
POST users/_doc/1 #添加id为1的文档 ,如果没有指定id,ES会自动生成
{
"firstname": "will",
"lastname": "smith"
}
POST users/_create/2 #创建id为2的文档,如果索引中已存在相同id,会报错;
{
"firstname": "will",
"lastname": "smith"
}
POST users/_update/2 #在id位2的文档中添加一个age属性,修改结构
{
"doc":
{
"age": 30
}
}
DELETE users/_doc/2 #删除id为2的文档
DELETE users #删除 users 索引
PUT users/_doc/1 #创建或者修改文档 {
"firstname": "Jack", "lastname": "ma"
}
PUT users/_create/2 #创建id为2的文档,如果已存在就报错,如果不存在就创建
{
"firstname": "will",
"lastname": "smith"
}
GET _mget # #批量查询多个指定的id的数据,也可以批量查询
{
"docs": [ {"_index": "users", "_id": 1},
{"_index": "users", "_id": 2}
]
}
POST users/_bulk # #批量插入数据
{"index": {"_id": 3}}
{"firstname": "A", "lastname": "a"}
{"index":{"_id": 4}}
{"firstname": "B", "lastname": "b"}
{"index": {"_id": 5}}
{"firstname": "X", "lastname": "x"}
{"index": {}}
{"firstname": "Z", "lastname": "z"}
10.2 URI查询
GET movies/_search?q=2012 #查询所有的属性中只要包含2012的所有的数据,泛查询 #
# 查询title中包含2012的所有的电影,df(default field)
GET movies/_search?q=2012&df=title
或者
GET movies/_search?q=title:2012
# 查询title中包含Beautiful或者Mind的所有的数据
GET movies/_search?q=title:Beautiful Mind
GET movies/_search?q=title:(Beautiful Mind)
GET movies/_search?q=title:(+Beautiful +Mind)
# 查询title中包含Beautiful但是不包含mind的所有的数据
GET movies/_search?q=title:(Beautiful NOT Mind)
GET movies/_search?q=title:(Beautiful -Mind)
GET movies/_search?q=title:"Beautiful Mind" #查询title中包含 "Beautiful Mind"这个短语的所有的数据
GET movies/_search?q=title:(Mind AND Beautiful) #查询title中既包含Mind又包含Beautiful的所有的数据,与顺序没有关系。AND不可以小写。否则为普通关键字
GET movies/_search?q=title:2012&from=10&size=8 #查询title中包含2012,从第10条开始,查询8条数据
GET movies/_search?q=year:>=2018 #查询2018年之后上映的电影
GET movies/_search?q=title:Beautiful AND year:>=2012 #查询title中包含Beautiful且电影上映时间在2012年之后的所有的数据
GET movies/_search?q=year:(>=2012 AND <2018) #查询在2012到2017年上映的电影
GET movies/_search?q=year:{2015 TO 2017] #查询2016年到2017年上映的电影,必须以 ] 结尾
GET movies/_search?q=title:Min?x # ?代表一个字母
GET movies/_search?q=title:Min* # 查询title中包含以 Min开头的字母的电影
GET movies/_search?q=title:Min* # 查询title中包含以 Min开头的字母的电影
11 Analysis
analysis(只是一个概念),文本分析是将全文本转换为一系列单词的过程,也叫分词。analysis是通
过analyzer(分词器)来实现的,可以使用Elasticsearch内置的分词器,也可以自己去定制一些分词
器。 除了在数据写入的时候进行分词处理,那么在查询的时候也可以使用分析器对查询语句进行分词。
anaylzer是由三部分组成,例如有
Hello a World, the world is beautiful
1. Character Filter: 将文本中html标签剔除掉。
2. Tokenizer: 按照规则进行分词,在英文中按照空格分词。
3. Token Filter: 去掉stop world(停顿词,a, an, the, is, are等),然后转换小写 # 这个是Stop Analyzer的功能
11.1 内置分词器

11.2 内置分词器示例
Standard Analyzer
GET _analyze
{
"analyzer": "standard",
"text": "2 Running quick brown-foxes leap over lazy dog in the summer evening"
}
Simple Analyzer
GET _analyze
{
"analyzer": "simple",
"text": "2 Running quick brown-foxes leap over lazy dog in the summer evening"
}
Stop Analyzer
GET _analyze
{
"analyzer": "stop",
"text": "2 Running quick brown-foxes leap over lazy dog in the summer evening"
}
Whitespace Analyzer
GET _analyze
{
"analyzer": "whitespace",
"text": "2 Running quick brown-foxes leap over lazy dog in the summer evening"
}
Keyword Analyzer
GET _analyze
{
"analyzer": "keyword",
"text": "2 Running quick brown-foxes leap over lazy dog in the summer evening"
}
Pattern Analyzer
GET _analyze
{
"analyzer": "pattern",
"text": "2 Running quick brown-foxes leap over lazy dog in the summer evening"
}
12 Request Body深入搜索
12.1 term查询
term是表达语义的最小单位,在搜索的时候基本都要使用到term。
term查询的种类有:Term Query、Range Query等。
在ES中,Term查询不会对输入进行分词处理,将输入作为一个整体,在倒排索引中查找准确的词项。我们也可以使用 Constant Score 将查询转换为一个filter,避免算分,利用缓存,提高查询的效率
12.1.1 term与terms
查询电影名字中包含有 beautiful 这个单词的所有的电影,用于查询的单词不会进行分词的处理
NOTE1: 通过使用term查询得知ES中默认使用分词器为标准分词器(StandardAnalyzer),标准分词器对于英文单词分词,对于中文单字分词。
NOTE2: 通过使用term查询得知,在ES的Mapping Type 中 keyword , date ,integer, long , double , boolean or ip 这些类型不分词,只有text类型分词。
查询电影名字中包含有 beautiful 这个单词的所有的电影,用于查询的单词不会进行分词的处理
GET movies/_search
{
"query": {
"term": {
"title": {
"value": "beautiful"
}
}
}
}
查询电影名字中包含有 beautiful 或者 mind 这两个单词的所有的电影,用于查询的单词不会进行分词的处理
GET movies/_search
{
"query": {
"terms": {
"title": [
"beautiful",
"mind"
]
}
}
}
12.1.2 range
查询上映在2016到2018年的所有的电影,再根据上映时间的倒序进行排序
GET movies/_search
{
"query": {
"range": {
"year": {
"gte": 2016,
"lte": 2018
}
}
},
"sort": [
{
"year": {
"order": "desc"
}
}
]
}
12.1.3 Constant Score
查询title中包含有beautiful的所有的电影,不进行相关性算分,查询的数据进行缓存,提高效率
GET movies/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"title": "beautiful"
}
}
}
}
}
12.2 全文查询
全文查询的种类有: Match Query、Match Phrase Query、Query String Query等
索引和搜索的时候都会进行分词,在查询的时候,会对输入进行分词,然后每个词项会逐个到底层进行
查询,将最终的结果进行合并
12.2.1 match
查询电影名字中包含有beautiful的所有电影,每页十条,取第二页的数据
GET movies/_search
{
"query": {
"match": {
"title": "beautiful"
}
},
"from": 10,
"size": 10
}
查询电影名字中包含有 beautiful 或者 mind 的所有的数据,但是只查询title和id两个属性
GET movies/_search
{
"_source": [
"title",
"id"
],
"query": {
"match": {
"title": "beautiful mind"
}
}
}
12.2.2 match_phrase
查询电影名字中包含有 "beautiful mind" 这个短语的所有的数据
GET movies/_search
{
"query": {
"match_phrase": {
"title": "beautiful mind"
}
}
}
12.2.3 multi_match
查询 title 或 genre 中包含有 beautiful 或者 Adventure 的所有的数据
GET movies/_search
{
"query": {
"multi_match": {
"query": "beautiful Adventure",
"fields": [
"title",
"genre"
]
}
}
}
12.2.4 match_all
查询所有的数据
GET movies/_search
{
"query": {
"match_all": {}
}
}
12.2.5 query_string
查询 title 中包含有 beautiful 和 mind 的所有的电影
GET movies/_search
{
"query": {
"query_string": {
"default_field": "title",
"query": "mind AND beautiful"
}
}
}
GET movies/_search
{
"query": {
"query_string": {
"default_field": "title",
"query": "mind beautiful",
"default_operator": "AND"
}
}
}
12.2.6 simple_query_string
simple_query_string 覆盖了很多其他查询的用法。
查询 title 中包含有 beautiful 和 mind 的所有的电影
GET movies/_search
{
"query": {
"simple_query_string": {
"query": "beautiful + mind",
"fields": [
"title"
]
}
}
}
GET movies/_search
{
"query": {
"simple_query_string": {
"query": "beautiful mind",
"fields": [
"title"
],
"default_operator": "AND"
}
}
}
查询title中包含 "beautiful mind" 这个短语的所有的电影 (用法和match_phrase类似)
GET movies/_search
{
"query": {
"simple_query_string": {
"query": "\"beautiful mind\"",
"fields": [
"title"
]
}
}
}
查询title或genre中包含有 beautiful mind romance 这个三个单词的所有的电影 (与multi_match类似)
GET movies/_search
{
"query": {
"simple_query_string": {
"query": "beautiful mind Romance",
"fields": [
"title",
"genre"
]
}
}
}
查询title中包含 “beautiful mind” 或者 "Modern Romance" 这两个短语的所有的电影
GET movies/_search
{
"query": {
"simple_query_string": {
"query": "\"beautiful mind\" | \"Modern Romance\"",
"fields": [
"title"
]
}
}
}
查询title或者genre中包含有 beautiful + mind 这个两个词,或者Comedy + Romance +Musical + Drama + Children 这个五个词的所有的数
GET movies/_search
{
"query": {
"simple_query_string": {
"query": "(beautiful + mind) | (Comedy + Romance + Musical + Drama + Children)",
"fields": [
"title",
"genre"
]
}
}
}
查询 title 中包含 beautiful 和 people 但是不包含 Animals 的所有的数据
GET movies/_search
{
"query": {
"simple_query_string": {
"query": "beautiful + people + -Animals",
"fields": [
"title"
]
}
}
}
12.3 模糊搜索
fuzzy 关键字: 用来模糊查询含有指定关键字的文档 注意:允许出现的错误必须在0-2之间
注意: 最大编辑距离为 0 1 2
如果关键词为2个长度 0..2 must match exactly 必须完全匹配
如果关键词长度3..5之间 one edit allowed 允许一个失败
如果关键词长度>5 two edits allowed 最多允许两个错误
查询title中从第6个字母开始只要最多纠正一次,就与 neverendign 匹配的所有的数据
GET movies/_search
{
"query": {
"fuzzy": {
"title": {
"value": "neverendign",
"fuzziness": 1, # 可以设置出错的个数。范围0-2
"prefix_length": 5
}
}
}
}
12.4 多条件查询
查询title中包含有beautiful或者mind单词,并且上映时间在2016~1018年的所有的电影
GET movies/_search
{
"query": {
"bool": {
"must": [
{
"simple_query_string": {
"query": "beautiful mind",
"fields": [
"title"
]
}
},
{
"range": {
"year": {
"gte": 2016,
"lte": 2018
}
}
}
]
}
}
}
查询 title 中包含有 beautiful 这个单词,并且上映年份在2016~2018年间的所有电影,但是不进行相关性的算分
# filter不会进行相关性的算分,并且会将查出来的结果进行缓存,效率上比 query 高
GET movies/_search
{
"query": {
"bool": {
"filter": [
{
"term": {
"title": "beautiful"
}
},
{
"range": {
"year": {
"gte": 2016,
"lte": 2018
}
}
}
]
}
}
}
12.5 (过滤查询) Filter Query
12.5.1 过滤查询
其实准确来说,ES中的查询操作分为2种: 查询(query)`和过滤(filter)。查询即是之前提到的query查询,它 (查询)默认会计算每个返回文档的得分,然后根据得分排序。而过滤(filter)只会筛选出符合的文档,并不计算 得分,且它可以缓存文档 。所以,单从性能考虑,过滤比查询更快。
换句话说,过滤适合在大范围筛选数据,而查询则适合精确匹配数据。一般应用时, 应先使用过滤操作过滤数据, 然后使用查询匹配数据。
12.5.2 过滤语法
GET /movies/_search
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": {
"range": {
"year": {
"gte": 2000
}
}
}
}
}
}
在执行filter和query时,先执行filter在执行query
Elasticsearch会自动缓存经常使用的过滤器,以加快性能。
12.5.3 常见的过滤器类型
term 、terms Filte、range filter
GET /movies/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"title": {
"value": "halloween"
}
}
}
],
"filter": {
"term": {
"genre": "horror"
}
}
}
}
}
GET movies/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"title": {
"value": "halloween"
}
}
}
],
"filter": {
"terms": {
"genre": [
"horror",
"thriller"
]
}
}
}
}
}
GET /movies/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"title": {
"value": "halloween"
}
}
}
],
"filter": {
"range": {
"year": {
"gte": 2000,
"lte": 3000
}
}
}
}
}
}
12.6 其他补充
12.6.1 查询结果中返回指定条数(size)
size 关键字: 指定查询结果中返回指定条数。 默认返回值10条
GET /movies/_search
{
"query": {
"match_all": {}
},
"size": 1
}
12.6.2 分页查询(from)
from 关键字: 用来指定起始返回位置,和size关键字连用可实现分页效果
GET /movies/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"year": {
"order": "desc"
}
}
],
"size": 2,
"from": 1 # 从0开始
}
12.6.3 查询结果中返回指定字段(_source)
_source 关键字: 是一个数组,在数组中用来指定展示那些字段
GET /movies/_search
{
"query": {
"match_all": {}
},
"_source": [
"id",
"year"
]
}
12.6.4 前缀查询(prefix)
prefix关键字: 用来检索含有指定前缀的关键词的相关文档
GET /movies/_search
{
"query": {
"prefix": {
"title": { # 属性名
"value": "beau"
}
}
}
}
12.6.5 通配符查询(wildcard)
wildcard 关键字: 通配符查询 ? 用来匹配一个任意字符 * 用来匹配多个任意字符
GET /movies/_search
{
"query": {
"wildcard": {
"title": { # 属性名
"value": "re*"
}
}
}
}
12.6.6 多id查询(ids)
ids 关键字 : 值为数组类型,用来根据一组id获取多个对应的文档
GET /movies/_search
{
"query": {
"ids": {
"values": ["932","939"]
}
}
}
12.6.7 布尔查询(bool)
bool 关键字: 用来组合多个条件实现复杂查询 boolb表达式查询
must: 相当于&& 同时成立
should: 相当于|| 成立一个就行
must_not: 相当于!不能满足任何一个
GET /movies/_search
{
"query": {
"bool": {
"must": [
{
"range": {
"year": {
"gte": 0,
"lte": 30
}
}
}
],
"must_not": [
{"wildcard": {
"title": {
"value": "a*"
}
}}
]
}
},
"sort": [
{
"year": {
"order": "desc"
}
}
]
}
13 Mapping
mapping类似于数据库中的schema,作用如下:
1 定义索引中的字段类型;
2 定义字段的数据类型,例如:布尔、字符串、数字、日期.....
3 字段倒排索引的设置
13.1 数据类型

ES中还有 "对象类型/嵌套类型"、"特殊类型(geo_point/geo_shape)"。
13.2 Mapping的定义
语法格式如下:
PUT users
{
"mappings": {
// define your mappings here
}
}
定义mapping的建议方式: 写入一个样本文档到临时索引中,ES会自动生成mapping信息,通过访问
mapping信息的api查询mapping的定义,修改自动生成的mapping成为我们需要方式,创建索引,删
除临时索引,简而言之就是 “卸磨杀驴” 。
14 常见参数
14.1 index
可以给属性添加一个 布尔类型的index属性,标识该属性是否能被倒排索引,也就是说是否能通过
该字段进行搜索。
14.2 null_value
在数据索引进ES的时候,当某些数据为 null 的时候,该数据是不能被搜索的,可以使用
null_value 属性指定一个值,当属性的值为 null 的时候,转换为一个通过 null_value 指
定的值。 null_value属性只能用于Keyword类型的属性
15 再谈搜索
15.1 聚合查询
聚合搜索的语法格式如下:
GET indexName/_search
{
"aggs": {
"aggs_name": { #聚合分析的名字是由用户自定义的
"aggs_type": {}
}
}
}
给users索引创建mapping信息
PUT employee
{
"mappings": {
"properties": {
"id": {
"type": "integer"
},
"name": {
"type": "keyword"
},
"job": {
"type": "keyword"
},
"age": {
"type": "integer"
},
"gender": {
"type": "keyword"
}
}
}
}
往 users 索引中写入数据
PUT employee/_bulk
{"index":{"_id":1}}
{"id":1,"name":"Bob","job":"java","age":21,"sal":8000,"gender":"female"}
{"index":{"_id":2}}
{"id":2,"name":"Rod","job":"html","age":31,"sal":18000,"gender":"female"}
{"index":{"_id":3}}
{"id":3,"name":"Gaving","job":"java","age":24,"sal":12000,"gender":"male"}
{"index":{"_id":4}}
{"id":4,"name":"King","job":"dba","age":26,"sal":15000,"gender":"female"}
{"index":{"_id":5}}
{"id":5,"name":"Jonhson","job":"dba","age":29,"sal":16000,"gender":"male"}
{"index":{"_id":6}}
{"id":6,"name":"Douge","job":"java","age":41,"sal":20000,"gender":"female"}
{"index":{"_id":7}}
{"id":7,"name":"cutting","job":"dba","age":27,"sal":7000,"gender":"male"}
{"index":{"_id":8}}
{"id":8,"name":"Bona","job":"html","age":22,"sal":14000,"gender":"female"}
{"index":{"_id":9}}
{"id":9,"name":"Shyon","job":"dba","age":20,"sal":19000,"gender":"female"}
{"index":{"_id":10}}
{"id":10,"name":"James","job":"html","age":18,"sal":22000,"gender":"male"}
{"index":{"_id":11}}
{"id":11,"name":"Golsling","job":"java","age":32,"sal":23000,"gender":"female"}
{"index":{"_id":12}}
{"id":12,"name":"Lily","job":"java","age":24,"sal":2000,"gender":"male"}
{"index":{"_id":13}}
{"id":13,"name":"Jack","job":"html","age":23,"sal":3000,"gender":"female"}
{"index":{"_id":14}}
{"id":14,"name":"Rose","job":"java","age":36,"sal":6000,"gender":"female"}
{"index":{"_id":15}}
{"id":15,"name":"Will","job":"dba","age":38,"sal":4500,"gender":"male"}
{"index":{"_id":16}}
{"id":16,"name":"smith","job":"java","age":32,"sal":23000,"gender":"male"}
单值的输出
ES中大多数的数学计算只输出一个值,如:min、max、sum、avg、cardinality
查询工资的总和
GET employee/_search
{
"size": 0, # 显示查出来的不聚合的显示纪录条数
"aggs": {
"other_info": {
"sum": {
"field": "sal"
}
}
}
}
查询员工的平均工资
GET employee/_search
{
"size": 0,
"aggs": {
"other_aggs_info": {
"avg": {
"field": "sal"
}
}
}
}
查询总共有多少个岗位, cardinality的值类似于sql中的 count distinct,即去重统计总数
GET employee/_search
{
"size": 0,
"aggs": {
"job_count": {
"cardinality": {
"field": "job"
}
}
}
}
查询航班票价的最高值、平均值、最低值
GET kibana_sample_data_flights/_search
{
"size": 0,
"aggs": {
"max_price": {
"max": {
"field": "AvgTicketPrice"
}
},
"min_price": {
"min": {
"field": "AvgTicketPrice"
}
},
"avg_price": {
"avg": {
"field": "AvgTicketPrice"
}
}
}
}
多值的输出
ES还有些函数,可以一次性输出很多个统计的数据: terms、stats
查询工资的信息
GET employee/_search
{
"size": 0,
"aggs": {
"sal_info": {
"stats": {
"field": "sal"
}
}
}
}
结果:
{
"took" : 9,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 16,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"sal_info" : {
"count" : 16,
"min" : 2000.0,
"max" : 23000.0,
"avg" : 13281.25,
"sum" : 212500.0
}
}
}
查询到达不同城市的航班数量
GET kibana_sample_data_flights/_search
{
"size": 0,
"aggs": {
"flight_dest": {
"terms": {
"field": "DestCountry"
}
}
}
}
查询每个岗位有多少人
GET employee/_search
{
"size": 0,
"aggs": {
"job_count": {
"terms": {
"field": "job"
}
}
}
}
查询目标地的航班次数以及天气信息
GET kibana_sample_data_flights/_search
{
"size": 0,
"aggs": {
"dest_city": {
"terms": {
"field": "DestCityName"
},
"aggs": {
"whether_info": {
"terms": {
"field": "DestWeather"
}
}
}
}
}
}
查询每个岗位下工资的信息(平均工资、最高工资、最少工资等)
GET employee/_search
{
"size": 0,
"aggs": {
"job_inf": {
"terms": {
"field": "job"
},
"aggs": {
"sal_info": {
"stats": {
"field": "sal"
}
}
}
}
}
}
查询不同工种的男女员工数量、然后统计不同工种下男女员工的工资信息
GET employee/_search
{
"size": 0,
"aggs": {
"job_info": {
"terms": {
"field": "job"
},
"aggs": {
"gender_info": {
"terms": {
"field": "gender"
},
"aggs": {
"sal_info": {
"stats": {
"field": "sal"
}
}
}
}
}
}
}
}
查询年龄最大的两位员工的信息
GET employee/_search
{
"size": 0,
"aggs": {
"top_age_2": {
"top_hits": {
"size": 2,
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
}
}
}
查询不同区间员工工资的统计信息
GET employee/_search
{
"size": 0,
"aggs": {
"sal_info": {
"range": {
"field": "sal",
"ranges": [
{
"key": "0 <= sal <= 5000",
"from": 0,
"to": 5000
},
{
"key": "5001 <= sal <= 10000",
"from": 5001,
"to": 10000
},
{
"key": "10001 <= sal <= 15000",
"from": 10001,
"to": 15000
}
]
}
}
}
}
以直方图的方式以每5000元为一个区间查看工资信息
GET employee/_search
{
"size": 0,
"aggs": {
"sal_info": {
"histogram": {
"field": "sal",
"interval": 5000,
"extended_bounds": {
"min": 0,
"max": 30000
}
}
}
}
}
interval: 以指定的值为一个区间。
extended_bounds: 可以指定区间的范围,如果超出了区间范围以实际为准,如果没有超出其他区间的数据依然显示。
查询平均工资大最低的工种
GET employee/_search
{
"size": 0,
"aggs": {
"job_info": {
"terms": {
"field": "job"
},
"aggs": {
"job_avg_sal": {
"avg": {
"field": "sal"
}
}
}
},
"min_sal_job": {
"min_bucket": {
"buckets_path": "job_info>job_avg_sal"
}
}
}
}
求工资和工种的信息
GET employee/_search
{
"size": 0,
"aggs": {
"job_inf": {
"terms": {
"field": "job"
}
},
"sal_info": {
"stats": {
"field": "sal"
}
}
}
}
查询年龄大于30岁的员工的平均工资
GET employee/_search
{
"size": 0,
"query": {
"range": {
"age": {
"gte": 30
}
}
},
"aggs": {
"avg_sal": {
"avg": {
"field": "sal"
}
}
}
}
查询Java员工的平均工资
GET employee/_search
{
"size": 0,
"query": {
"constant_score": {
"filter": {
"term": {
"job": "java"
}
},
"boost": 1.2
}
},
"aggs": {
"avg_sal": {
"avg": {
"field": "sal"
}
}
}
}
求30岁以上的员工的平均工资和所有员工的平均工资
GET employee/_search
{
"size": 0,
"aggs": {
"older_emp": {
"filter": {
"range": {
"age": {
"gte": 30
}
}
},
"aggs": {
"avg_sal": {
"avg": {
"field": "sal"
}
}
}
},
"job_info": {
"terms": {
"field": "job"
}
}
}
}
15.2 推荐搜索
在搜索过程中,因为单词的拼写错误,没有得到任何的结果,希望ES能够给我们一个推荐搜索。
GET movies/_search
{
"suggest": {
"title_suggestion": { # # title_suggestion为我们自定义的名字
"text": "drema",
"term": {
"field": "title",
"suggest_mode": "popular"
}
}
}
}
suggest_mode,有三个值:popular、missing、always
1 popular 是推荐词频更高的一些搜索。
2 missing 是当没有要搜索的结果的时候才推荐。
3 always无论什么情况下都进行推荐。
15.3 自动补全
自动补全应该是我们在日常的开发过程中最常见的搜索方式了,如百度搜索和京东商品搜索。
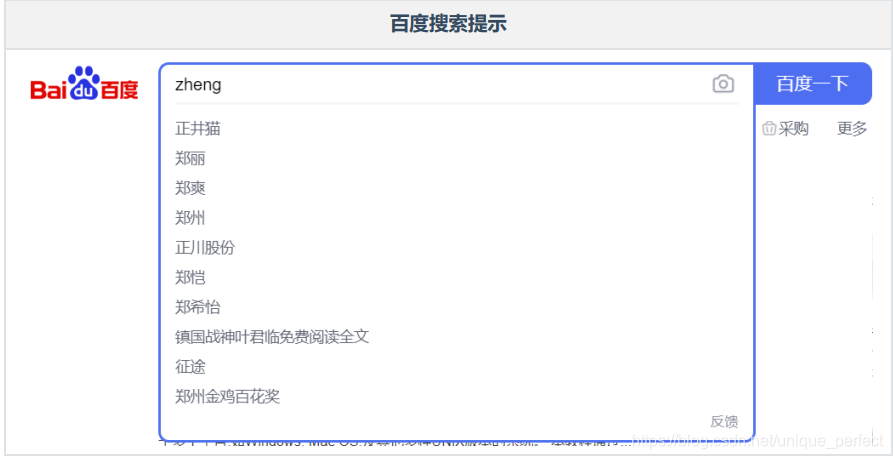
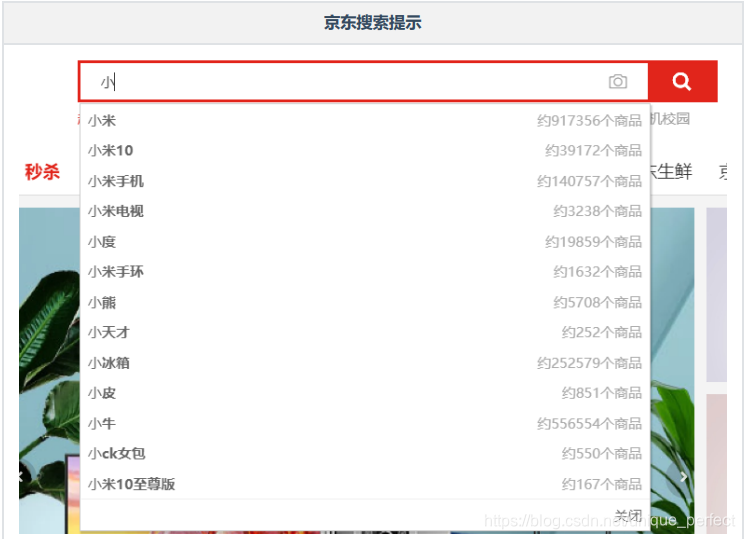
自动补全的功能对性能的要求极高,用户每发送输入一个字符就要发送一个请求去查找匹配项。
ES采取了不同的数据结构来实现,并不是通过倒排索引来实现的;需要将对应的数据类型设置为
completion ; 所以在将数据索引进ES之前需要先定义 mapping 信息。
定义mapping
PUT yxj
{
"mappings": {
"properties": {
"@version": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"genre": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"id": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"title": {
"type": "completion" # # 需要自动提示的属性类型必须是 completion
},
"year": {
"type": "long"
}
}
}
}
定义完 mapping 信息之后,导入响应的数据
2 前缀搜索
GET movies/_search
{
"_source": [
"title"
],
"suggest": {
"prefix_suggestion": {
"prefix": "Lan",
"completion": {
"field": "title",
"skip_duplicates": true,
"size": 10
}
}
}
}

15.4 高亮显示
高亮显示在实际的应用中也会碰到很多
将所有的包含有 beautiful 的单词高亮显示
GET movies/_search
{
"query": {
"match": {
"title": "beautiful"
}
},
"highlight": {
"post_tags": "</span>",
"pre_tags": "<span color='red'>",
"fields": {
"title": {}
}
}
}
GET /movies/_search
{
"query": {
"term": {
"title": {
"value": "beautiful"
}
}
},
"highlight": {
"fields": {
"title": {}
}
}
}
多字段高亮 使用require_field_match开启多个字段高亮
GET /employee/_search
{
"query": {
"term": {
"name": "Bob"
}
},
"highlight": {
"pre_tags": [
"<span style='color:red'>"
],
"post_tags": [
"</span>"
],
"require_field_match": false,
"fields": {
"*": {}
}
}
}
pre_tags: 是需要高亮文本的前置 html 内容。
post_tags: 是需要高亮的后置html内容。
fields: 是需要高亮的属性。
注意: 如果没写pre_tags、post_tags,则默认添加<em></em>

16 IK分词器
NOTE: 默认ES中采用标准分词器进行分词,这种方式并不适用于中文网站,因此需要修改ES对中文友好分词,从而达到更加的搜索的效果。
16.1 本地安装IK
可以将对应的IK分词器下载到本地,然后再安装
1 下载对应版本
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.10.2/elasticsearch-analysis-ik-7.10.2.zip
2 解压
unzip elasticsearch-analysis-ik-6.2.4.zip #先使用yum install -y unzip
3 移动到es安装目录的plugins目录中
IK分词器在任何操作系统下安装步骤均⼀样: 在ES的家⽬录下的 plugins ⽬录下创建名为ik的⽂件夹,然后将下载后的 zip 包拷⻉到 ik解压即可
4. 重启es生效
16.2 测试IK分词器
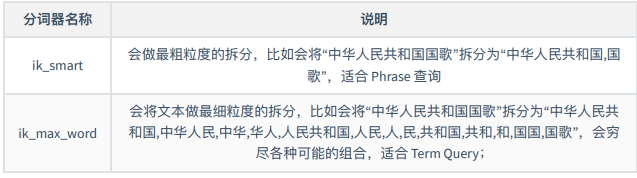
IK分词器提供了两种mapping类型用来做文档的分词分别是 ik_max_word和ik_smart
使⽤ ik_smart 分词器
GET _analyze
{
"analyzer": "ik_smart",
"text": [
"⼈终究是孤独的,每个⼈的⼈⽣都有别⼈参与,却都要⾃⼰完成。现在已经学会⾯对和接受孤独,即使伤疤没磨练的⾜够硬实,也不再依赖别⼈给的铠甲"
]
}
使⽤ ik_max_word 分词器
GET _analyze
{
"analyzer": "ik_max_word",
"text": [
"⼈终究是孤独的,每个⼈的⼈⽣都有别⼈参与,却都要⾃⼰完成。现在已经学会⾯对和接受孤独,即使伤疤没磨练的⾜够硬实,也不再依赖别⼈给的铠甲"
]
}
16.3 配置扩展词
IK支持自定义扩展词典和停用词典,所谓扩展词典就是有些词并不是关键词,但是也希望被ES用来作为检索的关键词,可以将这些词加入扩展词典。停用词典就是有些词是关键词,但是出于业务场景不想使用这些关键词被检索到,可以将这些词放入停用词典。
如何定义扩展词典和停用词典可以修改IK分词器中config目录中IKAnalyzer.cfg.xml这个文件。
NOTE:词典的编码必须为UTF-8,否则无法生效
1. 修改vim IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext_dict.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">ext_stopword.dic</entry>
</properties>
2 在ik分词器目录下config目录中创建ext_dict.dic文件 编码一定要为UTF-8才能生效
vim ext_dict.dic 加入扩展词即可
3 在ik分词器目录下config目录中创建ext_stopword.dic文件
vim ext_stopword.dic 加入停用词即可
4 重启es生效
17 pinyin分词器
1 下载对应版本
wget https://github.com/medcl/elasticsearch-analysis-pinyin/releases/download/v7.10.2/elasticsearch-analysis-pinyin-7.10.2.zip
2 解压
unzip elasticsearch-analysis-pinyin-7.10.2.zip #先使用yum install -y unzip
3 移动到es安装目录的plugins目录中
拼音分词器在任何操作系统下安装步骤均⼀样: 在ES的家⽬录下的 plugins ⽬录下创建名为pinyin的⽂件夹,然后将下载后的 zip 包拷⻉到 pinyin解压即可
4 重启es生效
5 验证
GET _analyze
{
"analyzer": "pinyin",
"text": "海贼王"
}
18 Java操作ES
注意:按道理来说只要引入elasticsearch-rest-high-level-client即可。但是因为引入elasticsearch跟对应的版本不符。所以需要额外引入elasticsearch的正确版本。否则启动失败
<dependencies>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.10.2</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.10.2</version>
</dependency>
</dependencies>
其他按着官方文档即可。这里主要解决启动不起来的问题
19 ES中集群
19.1 相关概念
19.1.1 集群(cluster)
一个集群就是由一个或多个节点组织在一起,它们共同持有你整个的数据,并一起提供索引和搜索功能。一个集群 由一个唯一的名字标识,这个名字默认就是elasticsearch。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群。在产品环境中显式地设定这个名字是一个好习惯,但是使用默认值来进行测试/开发也是不错的。
19.1.2 节点(node)
一个节点是你集群中的一个服务器,作为集群的一部分,它存储你的数据,参与集群的索引和搜索功能。和集群类似,一个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的漫威漫画角色的名字,这个名字会在启动的时候赋予节点。这个名字对于管理工作来说挺重要的,因为在这个管理过程中,你会去确定网络中的哪些服务器对应于Elasticsearch集群中的哪些节点。
一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫 做“elasticsearch”的集群中,这意味着,如果你在你的网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做“elasticsearch”的集群中。
在一个集群里,只要你想,可以拥有任意多个节点。而且,如果当前你的网络中没有运行任何Elasticsearch节点, 这时启动一个节点,会默认创建并加入一个叫做“elasticsearch”的集群。
19.1.3 分片和复制(shards & replicas)
一个索引可以存储超出单个结点硬件限制的大量数据。比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢。为了解决这个问题,Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片。当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置 到集群中的任何节点上。 分片之所以重要,主要有两方面的原因:
允许你水平分割/扩展你的内容容量允许你在分片(潜在地,位于多个节点上)之上进行分布式的、并行的操作,进而提高性能/吞吐量 至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由Elasticsearch管理的,对于作为用户的你来说,这些都是透明的。
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了。这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片,或者直接叫复制。复制之所以重要,主要有两方面的原因:
在分片/节点失败的情况下,提供了高可用性。因为这个原因,注意到复制分片从不与原/主要 (original/primary)分片置于同一节点上是非常重要的。 扩展你的搜索量/吞吐量,因为搜索可以在所有的复制上并行运行
总之,每个索引可以被分成多个分片。一个索引也可以被复制0次(意思是没有复制)或多次。一旦复制了,每个 索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。分片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制数量,但是不能改变分片的数量。
默认情况下,Elasticsearch中的每个索引被分片5个主分片和1个复制(7版本之后是一个主分片跟一个复制),这意味着,如果你的集群中至少有两个节点,你的索引将会有5个主分片和另外5个复制分片(1个完全拷贝),这样的话每个索引总共就有10个分片。一个索引的多个分片可以存放在集群中的一台主机上,也可以存放在多台主机上,这取决于你的集群机器数量。主分片和复制分片的具体位置是由ES内在的策略所决定的。
19.2 快速搭建集群
1 将原有ES安装包复制三份
cp -r elasticsearch-7.10.3/ master/
cp -r elasticsearch-7.10.3/ slave1/
cp -r elasticsearch-7.10.3/ slave2/
2 删除复制目录中data目录
#注意:由于复制目录之前使用过因此需要在创建集群时将原来数据删除
rm -rf master/data
rm -rf slave1/data
rm -rf slave2/data
3 编辑文件夹中config目录中jvm.options文件跳转启动内存(默认启动1g)
vim master/config/jvm.options
vim slave1/config/jvm.options
vim slave2/config/jvm.options
#分别加入: -Xms512m -Xmx512m
4 分别修改三个文件夹中config目录中elasticsearch.yml文件
vim master/config/elasticsearch.yml
vim salve1/config/elasticsearch.yml
vim slave2/config/elasticsearch.yml
#分别修改如下配置:
master/config/elasticsearch.yml
cluster.name: my-application #集群名称(集群名称必须一致)
node.name: node-1 #节点名称(节点名称不能一致)
network.host: 0.0.0.0 #监听地址(必须开启远程权限,并关闭防火墙)
http.port: 9201 #监听端口(在一台机器时服务端口不能一致)
discovery.seed_hosts: ["192.168.42.136:9302", "192.168.42.136:9303"] #另外两个节点的ip
cluster.initial_master_nodes: ["node-1","node-2","node-3"]
gateway.recover_after_nodes: 3 #集群可做master的最小节点数
transport.tcp.port: 9301 #集群TCP端口(在一台机器搭建必须修改)
http.cors.enabled: true
http.cors.allow-origin: "*"
salve1/config/elasticsearch.yml
cluster.name: my-application
node.name: node-2
network.host: 0.0.0.0
http.port: 9202
discovery.seed_hosts: ["192.168.42.136:9301", "192.168.42.136:9303"]
cluster.initial_master_nodes: ["node-1","node-2","node-3"]
gateway.recover_after_nodes: 3
transport.tcp.port: 9302
http.cors.enabled: true
http.cors.allow-origin: "*"
slave2/config/elasticsearch.yml
cluster.name: my-application
node.name: node-3
network.host: 0.0.0.0
http.port: 9203
discovery.seed_hosts: ["192.168.42.136:9301", "192.168.42.136:9302"]
cluster.initial_master_nodes: ["node-1","node-2","node-3"]
gateway.recover_after_nodes: 3
transport.tcp.port: 9303
http.cors.enabled: true
http.cors.allow-origin: "*"
5 启动多个es
./master/bin/elasticsearch
./slave1/bin/elasticsearch
./slave2/bin/elasticsearch
6 查看节点状态
curl http://10.102.115.3:9201
curl http://10.102.115.3:9202
curl http://10.102.115.3:9203
7 查看集群健康
http://10.102.115.3:9201/_cat/health?v
19.3 安装head插件
1 访问github网站
搜索: elasticsearch-head 插件
2 安装git
yum install git
3 将elasticsearch-head下载到本地
git clone git://github.com/mobz/elasticsearch-head.git
4. 安装nodejs
#注意: 没有wget的请先安装yum install -y wget
wget http://cdn.npm.taobao.org/dist/node/latest-v8.x/node-v8.1.2-linux-x64.tar.xz
5 解压缩nodejs(elasticsearch-head 插件依赖node)
xz -d node-v10.15.3-linux-arm64.tar.xz
tar -xvf node-v10.15.3-linux-arm64.tar
6. 配置环境变量
mv node-v10.15.3-linux-arm64 nodejs
mv nodejs /usr/nodejs
vim /etc/profile
export NODE_HOME=/usr/nodejs
export PATH=$PATH:$JAVA_HOME/bin:$NODE_HOME/bin
source /etc/profile
7 进入elasticsearch-head的目录
npm config set registry https://registry.npm.taobao.org
npm install
npm run start
8 编写elastsearch.yml配置文件开启head插件的访问(上面已经修改了)
http.cors.enabled: true
http.cors.allow-origin: "*"
9. 启动访问head插件 默认端口9100
http://ip:9100 查看集群状态
20 图片总结


















