聚类分析是一种无监督机器学习(训练样本的标记信息是未知的)算法,它的目标是将相似的对象归到同一个簇中,将不相似的对象归到不同的簇中。如果要使用聚类分析算法对一堆文本分类,一般需要确定几个关键的问题:
(1) 怎样来判断两个对象的相似与否
(2) 怎样权衡比较几个算法的优劣
(3) 如何确定分类的个数
(4) 需要选择哪种算法
对于第一个问题,判断中文文本相似与否那必须通过分词、构建词袋模型、权值转换等步骤,本篇小文主要围绕分词和构建词袋模型进行分析,先介绍在聚类前需要掌握的一些基础的理论。
1 基础理论
(1)余弦相似度
对多维向量A=(A1,A2,……,An),B=(B1,B2,……,Bn),余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个个体差异的大小。相比欧氏距离度量,余弦相似度更加注重两个向量在方向上的差异,而非距离或长度上的差异。余弦值的计算公式如下:
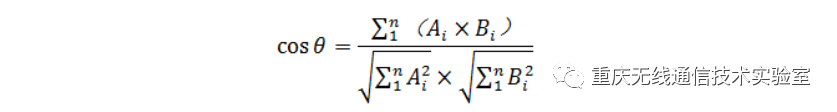
相对于欧氏距离,余弦相似度更适合计算文本的相似度。首先将文本转换为权值向量,通过计算两个向量的夹角余弦值,就可以评估他们的相似度。余弦值的范围在[-1,1]之间,值越趋近于1,代表两个向量方向越接近;越趋近于-1,代表他们的方向越相反。为了方便聚类分析,我们将余弦值做归一化处理,将其转换到[0,1]之间,并且值越小距离越近

(2)性能度量
在选择聚类算法之前,首先来了解什么样的聚类结果是比较好的。我们希望同一个簇内的样本尽可能相似,不同簇的样本尽可能不同,也就是说聚类结果的“簇内相似度”高且“簇间相似度”低。
DB指数(Davies-Bouldin Index,DBI)
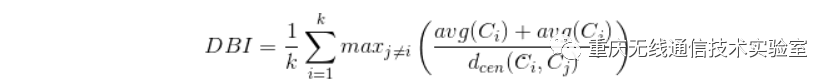
Dumn指数(Dumn Index,DI)
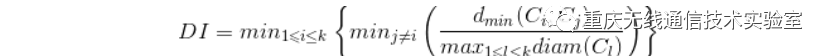
DB指数的计算方法是任意两个簇内样本的平均距离之和除以两个簇的中心点距离,并取最大值,DBI的值越小,意味着簇内距离越小,同时簇间的距离越大;Dumn指数的计算方法是任意两个簇的最近样本间的距离除以簇内样本的最远距离的最大值,并取最小值,DI的值越大,意味着簇间距离大而簇内距离小。因此,DBI的值越小,同时DI的值越大,意味着聚类的效果越好。
2具体应用
以一个具体需求为例,现有一个业务系统需要对收集的一些公司名数据进行处理,由于当时收录时杂乱无章,存在数据重复、信息不规范、错别字等现象;需要对数据进行分析归类,将相同或相似的数据划到一起,再通过人工审核规范数据,最终形成规范的字典数据。
(1)分词
要对中文文本做聚类分析,首先要对文本做分词处理,例如“联想移动通信科技有限公司”,我们希望将其切分为“联想移动通信科技有限公司”。Python提供专门的中文切词工具“jieba”,它可以将中文长文本划分为若干个单词。
为了提高分类的准确率,还要考虑两个干扰因素:一是英文字母大小写的影响,为此我们将英文字母统一转换为大写;二是例如“有限” “公司”等通用的词汇,我们将这样的词汇连同“()”、“-”、“/”、“&”等符号作为停用词,将其从分词结果中去除掉,最后得到有效的词汇组合,结果如下:
原始数据:

分词后数据:

(2)构建词袋模型
文本被切分成单词后,需要进一步转换成向量。先将所有文本中的词汇构建成一个词条列表,其中不含重复的词条。然后对每个文本,构建一个向量,向量的维度与词条列表的维度相同,向量的值是词条列表中每个词条在该文本中出现的次数,这种模型叫做词袋模型。例如,“阿尔西集团”和“阿尔西制冷工程技术(北京)有限公司”两个文本切词后的结果是“阿尔西集团”和“阿尔西制冷工程技术北京”,它们构成的词条列表是[阿尔西, 集团, 制冷, 工程技术, 北京],对应的词袋模型分别是[1,1,0,0,0],[1,0,1,1,1]。
具体代码:
#1分词
import jieba as ib
# 加载停用词,这里主要是排除“有限公司”一类的通用词
def loadStopWords(fileName):
dataMat =[]
fr =open(fileName)
words =fr.read()
result =jb.cut(words, cut_all=True)
newWords= []
for s inresult:
if snot in newWords:
newWords.append(s)
newWords.extend([u'(', u')', '(', ')', '/', '-', '.', '-', '&'])
returnnewWords
# 把文本分词并去除停用词,返回数组
def wordsCut(words, stopWordsFile):
result =jb.cut(words)
newWords= []
stopWords= loadStopWords(stopWordsFile)
for s inresult:
if snot in stopWords:
newWords.append(s)
returnnewWords
# 把样本文件做分词处理,并写文件
def fileCut(fileName, writeFile, stopWordsFile):
dataMat =[]
fr =open(fileName)
frW =open(writeFile, 'w')
for linein fr.readlines():
curLine = line.strip()
curLine1 = curLine.upper() # 把字符串中的英文字母转换成大写
cutWords = wordsCut(curLine1, stopWordsFile)
for iin range(len(cutWords)):
frW.write(cutWords[i])
frW.write('\t')
frW.write('\n')
dataMat.append(cutWords)
frW.close()
# 2构建词袋模型
# 创建不重复的词条列表
defcreateVocabList(dataSet):
vocabSet = set([])
for document in dataSet:
vocabSet = vocabSet | set(document)
return list(vocabSet)
# 将文本转化为词袋模型
defbagOfWords2Vec(vocabList, inputSet):
returnVec = [0] * len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] +=1
else:
print "the word: %s is not inmy Vocabulary!" % word
return returnVec