概述
都知道他是实现共享变量在多线程之间的可见性,那么有没有想过是什么导致了这种不可见?
变量在多个CPU之间共享(处理器角度实现可见性)
- 现代计算机内存模型。
其实早期计算机中cpu和内存的速度是差不多的,但在现代计算机中,cpu的指令速度远超内存的存取速度,由于计算机的存储设备与处理器的运算速度有几个数量级的差距,所以现代计算机系统都不得不加入一层读写速度尽可能接近处理器运算速度的高速缓存(Cache)来作为内存与处理器之间的缓冲。
将运算需要使用到的数据复制到缓存中,让运算能快速进行,当运算结束后再从缓存同步回内存之中,这样处理器就无须等待缓慢的内存读写了。
在多处理器系统中,每个处理器都有自己的高速缓存,而它们又共享同一主内存。

-
多个CPU的缓存数据可能不一样,那么同步回到主内存,以谁为主?为了解决缓存一致性,我们提出缓存一致性协议
-
缓存一致性协议
当CPU写数据时,如果发现操作的变量是共享变量,即在其他CPU中也存在该变量的副本,会发出信号通知其他CPU将该变量的缓存行置为无效状态,是通过总线嗅探机制来实现的,因此当其他CPU需要读取这个变量时,发现自己缓存中缓存该变量的缓存行是无效的,那么它就会从内存重新读取。
Java程序角度
- Java内存模型(JMM),是java虚拟机规范中所定义的一种内存模型,Java内存模型是标准化的,屏蔽掉了底层不同计算机的区别。
- 而Java内存模型描述了Java程序中各种线程共享变量访问规则,以及在JVM中将变量,存储到内存和从内存中读取变量这样的底层细节。
JMM规定:所有的共享变量都存储于主内存,这里所说的变量指的是实例变量和类变量,不包含局部变量,因为局部变量是线程私有的,因此不存在竞争问题。
每一个线程还存在自己的工作内存,线程的工作内存,保留了被线程使用的变量的工作副本。
线程对变量的所有的操作(读,取)都必须在工作内存中完成,而不能直接读写主内存中的变量。
不同线程之间也不能直接访问对方工作内存中的变量,线程间变量的值的传递需要通过主内存中转来完成。

- 解决方案
通过给操作共享变量的程序加锁
因为某一个线程进入synchronized代码块前后,线程会获得锁,清空工作内存,从主内存拷贝共享变量最新的值到工作内存成为副本,执行代码,将修改后的副本的值刷新回主内存中,线程释放锁。
而获取不到锁的线程会阻塞等待,所以变量的值肯定一直都是最新的。
volatile修饰共享变量
加了关键字每个线程都会把数据从主内存读到工作内存。
指令重排序
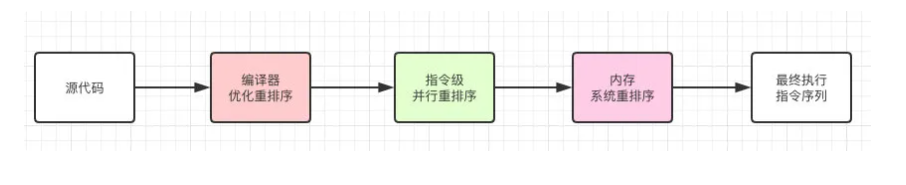
在执行程序时,为了提高性能,编译器和处理器常常会对指令进行重排序。
-
编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序;
-
指令级并行的重排序。现代处理器采用了指令级并行技术来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序;
-
内存系统的重排序。由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是在乱序执行的
Volatile是怎么保证不会被执行重排序的呢?
java编译器会在生成指令系列时在适当的位置会插入内存屏障指令来禁止特定类型的处理器重排序。
为了实现volatile的内存语义,JMM会限制特定类型的编译器和处理器重排序,JMM会针对编译器制定volatile重排序规则表。
要理解这些可能比较麻烦,JDK5又提出:如果一个操作执行的结果需要对另一个操作可见,那么这两个操作之间必须存在happens-before关系。