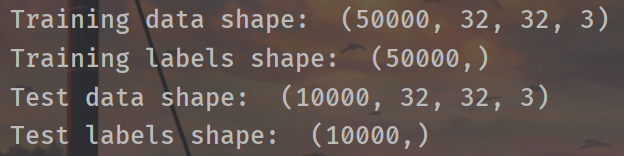
import matplotlib.pyplot as plt from six.moves import cPickle as pickle import platform import os import numpy as np def load_pickle(f): version = platform.python_version_tuple() if version[0] == '2': return pickle.load(f) elif version[0] == '3': return pickle.load(f, encoding='latin1') raise ValueError("invalid python version: {}".format(version)) def load_CIFAR_batch(filename): """ load single batch of cifar """ with open(filename, 'rb') as f: datadict = load_pickle(f) X = datadict['data'] Y = datadict['labels'] X = X.reshape(10000, 3, 32, 32).transpose(0, 2, 3, 1).astype("float") Y = np.array(Y) return X, Y def load_CIFAR10(ROOT): """ load all of cifar """ xs = [] ys = [] for b in range(1, 6): f = os.path.join(ROOT, 'data_batch_%d' % (b,)) X, Y = load_CIFAR_batch(f) xs.append(X) ys.append(Y) Xtr = np.concatenate(xs) Ytr = np.concatenate(ys) del X, Y Xte, Yte = load_CIFAR_batch(os.path.join(ROOT, 'test_batch')) return Xtr, Ytr, Xte, Yte def get_CIFAR10_data(num_training=49000, num_validation=1000, num_test=1000, subtract_mean=True): """ Load the CIFAR-10 dataset from disk and perform preprocessing to prepare it for classifiers. These are the same steps as we used for the SVM, but condensed to a single function. """ # Load the raw CIFAR-10 data cifar10_dir = 'cs231n/datasets/cifar-10-batches-py' X_train, y_train, X_test, y_test = load_CIFAR10(cifar10_dir) # Subsample the data mask = list(range(num_training, num_training + num_validation)) X_val = X_train[mask] y_val = y_train[mask] mask = list(range(num_training)) X_train = X_train[mask] y_train = y_train[mask] mask = list(range(num_test)) X_test = X_test[mask] y_test = y_test[mask] # Normalize the data: subtract the mean image if subtract_mean: mean_image = np.mean(X_train, axis=0) X_train -= mean_image X_val -= mean_image X_test -= mean_image # Transpose so that channels come first X_train = X_train.transpose(0, 3, 1, 2).copy() X_val = X_val.transpose(0, 3, 1, 2).copy() X_test = X_test.transpose(0, 3, 1, 2).copy() # Package data into a dictionary return { 'X_train': X_train, 'y_train': y_train, 'X_val': X_val, 'y_val': y_val, 'X_test': X_test, 'y_test': y_test, } # Load the raw CIFAR-10 data. cifar10_dir = 'dataset/cifar-10-batches-py' X_train, y_train, X_test, y_test = load_CIFAR10(cifar10_dir) # As a sanity check, we print out the size of the training and test data. print('Training data shape: ', X_train.shape) print('Training labels shape: ', y_train.shape) print('Test data shape: ', X_test.shape) print('Test labels shape: ', y_test.shape) # Visualize some examples from the dataset. # We show a few examples of training images from each class. classes = ['plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'] num_classes = len(classes) samples_per_class = 7 for y, cls in enumerate(classes): idxs = np.flatnonzero(y_train == y) idxs = np.random.choice(idxs, samples_per_class, replace=False) for i, idx in enumerate(idxs): plt_idx = i * num_classes + y + 1 plt.subplot(samples_per_class, num_classes, plt_idx) plt.imshow(X_train[idx].astype('uint8')) plt.axis('off') if i == 0: plt.title(cls) plt.show()
参考cs231n代码
Python手动读取CIFAR-10数据集

猜你喜欢
转载自blog.csdn.net/hxxjxw/article/details/113748717
今日推荐
周排行