Sematch是一个用于知识图谱的语义相似性的开发、评价和应用的集成框架,其代码见github。 Sematch支持对概念、词和实体的语义相似度的计算,并给出得分。 Sematch专注于基于特定知识的语义相似度量,它依赖于分类( 比如 ) 中的结构化知识。 深度、路径长度 ) 和统计信息内容( 语料库与语义图谱) 。
其应用框架如下所示:从图中可见,其支持多样化、多层次的相似度计算。

如其DEMO上可见,支持多样化的相似度计算。

1、测试:词的相似度计算,其结果如图所示:(代码见github)
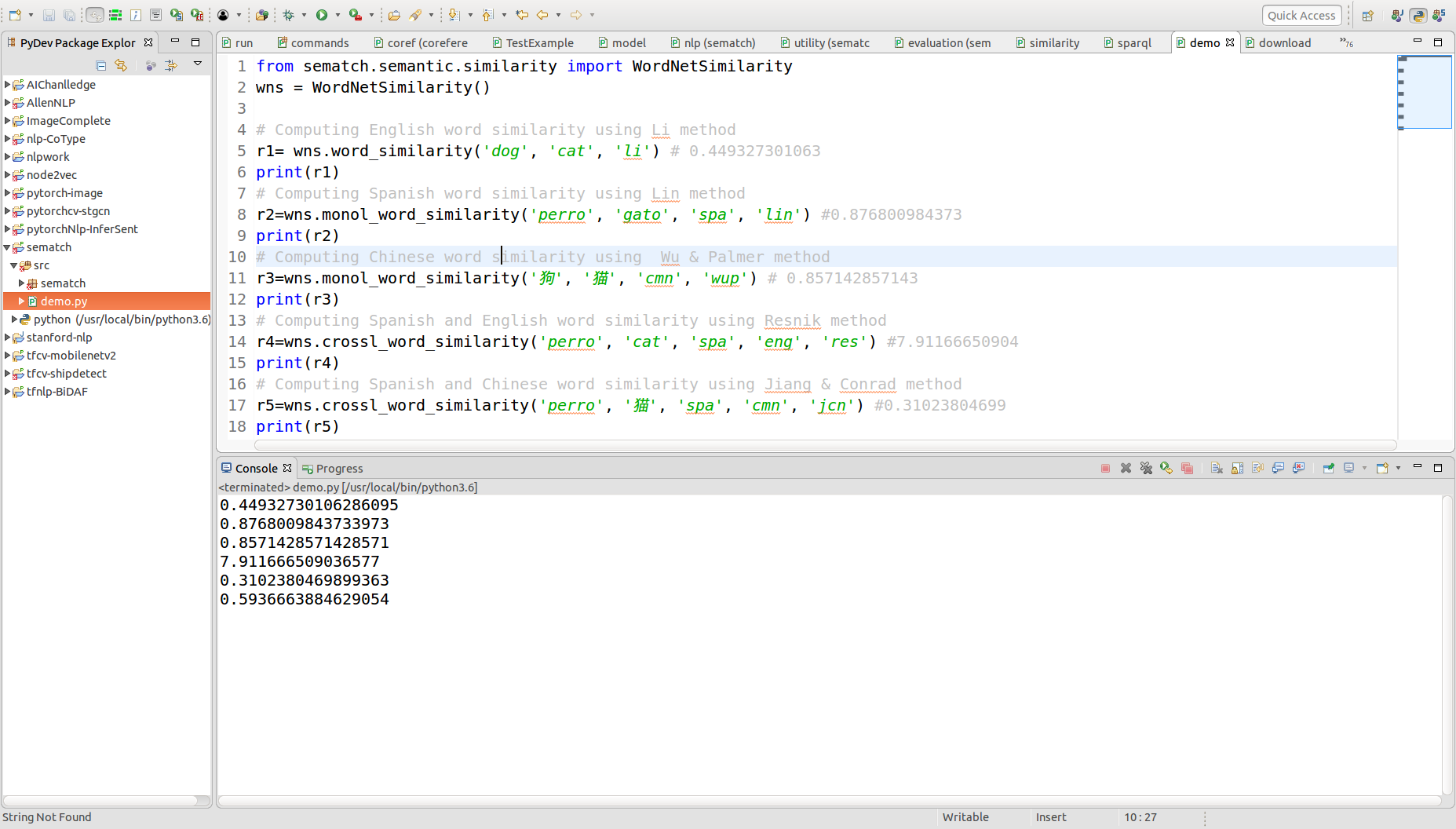
2、概念的相似度计算
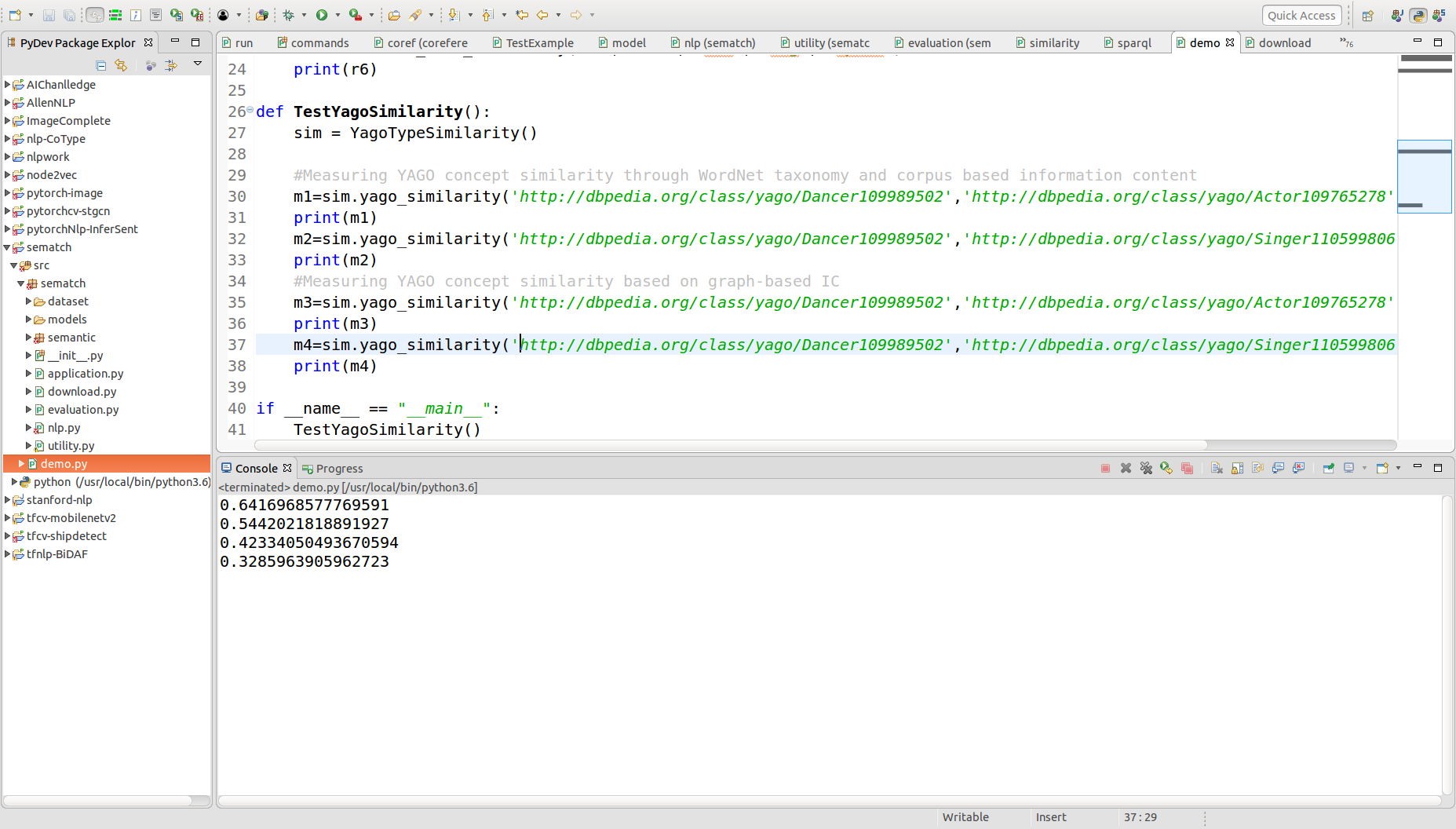
附:由于dbpedia国内无法访问,所以一些实体的相似性等目前暂无法测试。